Extraer características de imágenes con una red preentrenada
Este ejemplo muestra cómo extraer características de imagen aprendidas de una red neuronal convolucional preentrenada y cómo utilizar esas características para entrenar un clasificador de imágenes. La extracción de características es la forma más rápida y sencilla de utilizar la capacidad de representación de las redes profundas preentrenadas. Por ejemplo, puede entrenar una máquina de vectores de soporte (SVM) utilizando fitcecoc (Statistics and Machine Learning Toolbox™) en las características extraídas. Como la extracción de características solo requiere una única pasada por los datos, es un buen punto de partida si no tiene una GPU con la que acelerar el entrenamiento de la red.
Cargar datos
Descomprima y cargue las imágenes de muestra como un almacén de datos de imágenes. imageDatastore etiqueta de forma automática las imágenes basándose en los nombres de las carpetas y almacena los datos como un objeto ImageDatastore. Un almacén de datos de imágenes permite almacenar un gran volumen de datos de imágenes, incluidos los que no caben en la memoria. Divida los datos en un 70% de datos de entrenamiento y un 30% de datos de prueba.
unzip('MerchData.zip'); imds = imageDatastore('MerchData','IncludeSubfolders',true,'LabelSource','foldernames'); [imdsTrain,imdsTest] = splitEachLabel(imds,0.7,'randomized');
Ahora hay 55 imágenes de entrenamiento y 20 imágenes de validación en este pequeño conjunto de datos. Visualice algunas imágenes de muestra.
numTrainImages = numel(imdsTrain.Labels); idx = randperm(numTrainImages,16); figure for i = 1:16 subplot(4,4,i) I = readimage(imdsTrain,idx(i)); imshow(I) end

Cargar una red preentrenada
Cargue una red ResNet-18 preentrenada. Si no se ha instalado el paquete de soporte Deep Learning Toolbox Model for ResNet-18 Network, el software proporciona un enlace de descarga. ResNet-18 AlexNet se ha entrenado con más de un millón de imágenes y puede clasificar imágenes en 1000 categorías de objetos (por ejemplo, teclado, ratón, lápiz y muchos animales). Como resultado, el modelo ha aprendido representaciones ricas en características para una amplia gama de imágenes.
net = resnet18
net =
DAGNetwork with properties:
Layers: [71×1 nnet.cnn.layer.Layer]
Connections: [78×2 table]
InputNames: {'data'}
OutputNames: {'ClassificationLayer_predictions'}
Analice la arquitectura de red. La primera capa, que es la de entrada de imágenes, requiere imágenes de entrada de un tamaño de 224 por 224 por 3, donde 3 es el número de canales de color.
inputSize = net.Layers(1).InputSize; analyzeNetwork(net)
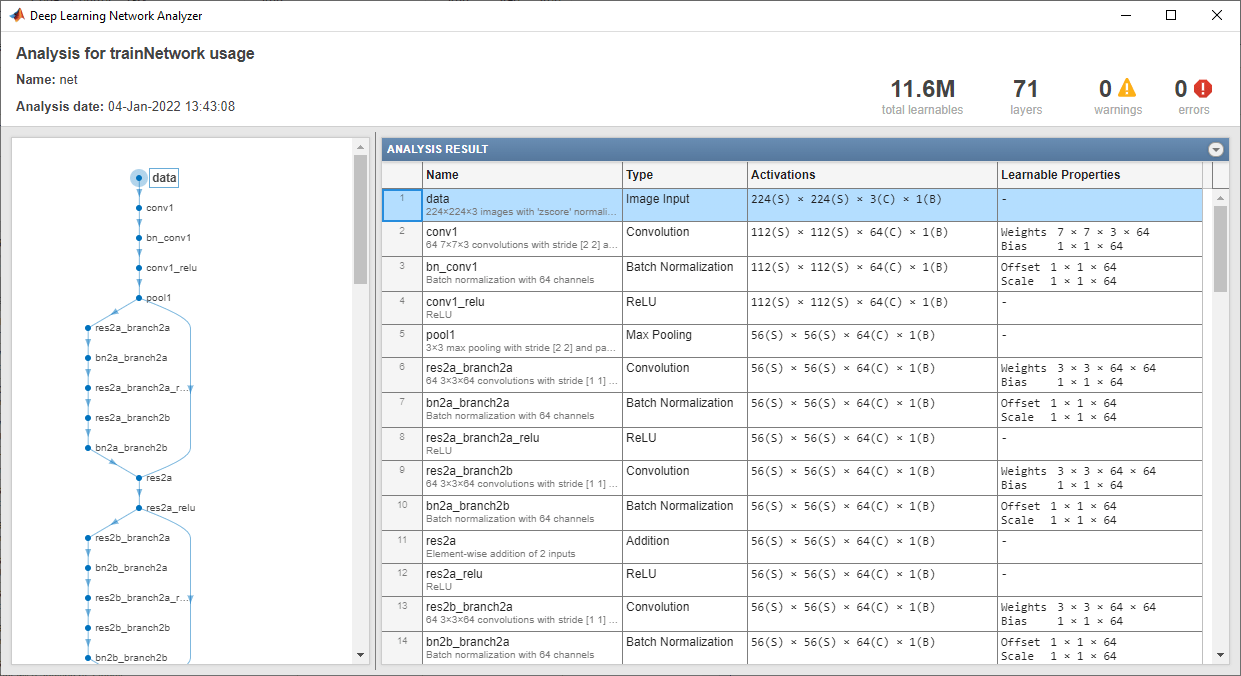
Extraer características de imágenes
La red requiere imágenes de entrada de un tamaño de 224 por 224 por 3, pero las imágenes de los almacenes de datos de imágenes tienen diferentes tamaños. Para cambiar automáticamente el tamaño de las imágenes de entrenamiento y de prueba antes de introducirlas en la red, cree almacenes de datos de imágenes aumentados, especifique el tamaño de imagen deseado y utilice estos almacenes de datos como argumentos de entrada de activations.
augimdsTrain = augmentedImageDatastore(inputSize(1:2),imdsTrain); augimdsTest = augmentedImageDatastore(inputSize(1:2),imdsTest);
La red construye una representación jerárquica de las imágenes de entrada. Las capas más profundas contienen características de nivel más alto construidas con las características de nivel más bajo de capas anteriores. Para obtener las representaciones de las características de las imágenes de entrenamiento y de prueba, utilice activations en la capa de grupo global 'pool5', del extremo final de la red. La capa de grupo global agrupa las características de entrada en todas las ubicaciones espaciales, dando un total de 512 características.
layer = 'pool5'; featuresTrain = activations(net,augimdsTrain,layer,'OutputAs','rows'); featuresTest = activations(net,augimdsTest,layer,'OutputAs','rows'); whos featuresTrain
Name Size Bytes Class Attributes featuresTrain 55x512 112640 single
Extraiga las etiquetas de clase de los datos de entrenamiento y de prueba.
YTrain = imdsTrain.Labels; YTest = imdsTest.Labels;
Ajustar el clasificador de imágenes
Utilice las características extraídas de las imágenes de entrenamiento como variables predictoras y ajuste una máquina de vectores de soporte (SVM) multiclase con fitcecoc (Statistics and Machine Learning Toolbox).
classifier = fitcecoc(featuresTrain,YTrain);
Clasificar imágenes de prueba
Clasifique las imágenes de prueba con el modelo de SVM entrenado empleando las características extraídas de las imágenes de prueba.
YPred = predict(classifier,featuresTest);
Muestre cuatro imágenes de prueba de muestra con etiquetas predichas.
idx = [1 5 10 15]; figure for i = 1:numel(idx) subplot(2,2,i) I = readimage(imdsTest,idx(i)); label = YPred(idx(i)); imshow(I) title(char(label)) end

Calcule la precisión de clasificación en el conjunto de prueba. La precisión es la fracción de etiquetas que la red predice correctamente.
accuracy = mean(YPred == YTest)
accuracy = 1
Entrenar el clasificador para las características más superficiales
También puede extraer características de una capa anterior en la red y entrenar un clasificador para esas características. Las capas anteriores suelen extraer características menos profundas y tienen una resolución espacial más alta, así como un número total de activaciones mayor. Extraiga las características de la capa 'res3b_relu'. Esta es la capa final que produce 128 características y las activaciones tienen un tamaño espacial de 28 por 28.
layer = 'res3b_relu'; featuresTrain = activations(net,augimdsTrain,layer); featuresTest = activations(net,augimdsTest,layer); whos featuresTrain
Name Size Bytes Class Attributes featuresTrain 28x28x128x55 22077440 single
Las características extraídas utilizadas en la primera parte de este ejemplo se han agrupado en todas las ubicaciones espaciales mediante la capa de grupo global. Para conseguir el mismo resultado al extraer características en capas anteriores, es necesario promediar manualmente las activaciones en todas las ubicaciones espaciales. Para obtener las características con la forma N-by-C, donde N es el número de observaciones y C es el número de características, se deben eliminar las dimensiones únicas y realizar la trasposición.
featuresTrain = squeeze(mean(featuresTrain,[1 2]))';
featuresTest = squeeze(mean(featuresTest,[1 2]))';
whos featuresTrainName Size Bytes Class Attributes featuresTrain 55x128 28160 single
Entrene un clasificador SVM para las características más superficiales. Calcule la precisión de la prueba.
classifier = fitcecoc(featuresTrain,YTrain); YPred = predict(classifier,featuresTest); accuracy = mean(YPred == YTest)
accuracy = 0.9500
Ambas SVM entrenadas ofrecen unas altas precisiones. Si la precisión no es lo suficientemente alta utilizando la extracción de características, pruebe la transferencia del aprendizaje en su lugar. Para ver un ejemplo, consulte Volver a entrenar redes neuronales para clasificar nuevas imágenes. Para obtener una lista comparativa de las redes preentrenadas, consulte Redes neuronales profundas preentrenadas.
Consulte también
fitcecoc (Statistics and Machine Learning Toolbox) | imagePretrainedNetwork