Optimize a Boosted Regression Ensemble
This example shows how to optimize hyperparameters of a boosted regression ensemble. The optimization minimizes the cross-validation loss of the model.
The problem is to model the efficiency in miles per gallon of an automobile, based on its acceleration, engine displacement, horsepower, and weight. Load the carsmall data, which contains these and other predictors.
load carsmall
X = [Acceleration Displacement Horsepower Weight];
Y = MPG;Fit a regression ensemble to the data using the LSBoost algorithm, and using surrogate splits. Optimize the resulting model by varying the number of learning cycles, the maximum number of surrogate splits, and the learn rate. Furthermore, allow the optimization to repartition the cross-validation between every iteration.
For reproducibility, set the random seed and use the 'expected-improvement-plus' acquisition function.
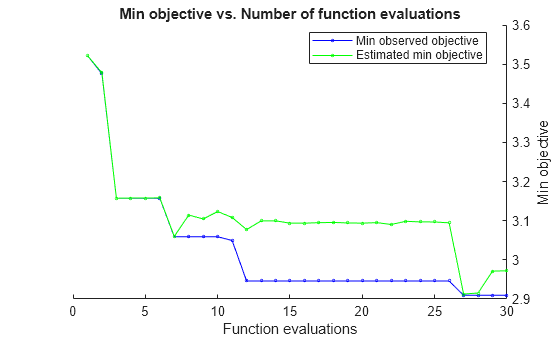
rng('default') Mdl = fitrensemble(X,Y, ... 'Method','LSBoost', ... 'Learner',templateTree('Surrogate','on'), ... 'OptimizeHyperparameters',{'NumLearningCycles','MaxNumSplits','LearnRate'}, ... 'HyperparameterOptimizationOptions',struct('Repartition',true, ... 'AcquisitionFunctionName','expected-improvement-plus'))
|====================================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | NumLearningC-| LearnRate | MaxNumSplits |
| | result | log(1+loss) | runtime | (observed) | (estim.) | ycles | | |
|====================================================================================================================|
| 1 | Best | 3.5219 | 2.0591 | 3.5219 | 3.5219 | 383 | 0.51519 | 4 |
| 2 | Best | 3.4752 | 0.30474 | 3.4752 | 3.4777 | 16 | 0.66503 | 7 |
| 3 | Best | 3.1575 | 0.19245 | 3.1575 | 3.1575 | 33 | 0.2556 | 92 |
| 4 | Accept | 6.3076 | 0.093649 | 3.1575 | 3.1579 | 13 | 0.0053227 | 5 |
| 5 | Accept | 3.4449 | 0.88764 | 3.1575 | 3.1579 | 277 | 0.45891 | 99 |
| 6 | Accept | 3.9806 | 0.050365 | 3.1575 | 3.1584 | 10 | 0.13017 | 33 |
| 7 | Best | 3.059 | 0.041349 | 3.059 | 3.06 | 10 | 0.30126 | 3 |
| 8 | Accept | 3.1707 | 0.054005 | 3.059 | 3.1144 | 10 | 0.28991 | 15 |
| 9 | Accept | 3.0937 | 0.08764 | 3.059 | 3.1046 | 10 | 0.31488 | 13 |
| 10 | Accept | 3.196 | 0.052277 | 3.059 | 3.1233 | 10 | 0.32005 | 11 |
| 11 | Best | 3.0495 | 0.048818 | 3.0495 | 3.1083 | 10 | 0.27882 | 85 |
| 12 | Best | 2.946 | 0.045202 | 2.946 | 3.0774 | 10 | 0.27157 | 7 |
| 13 | Accept | 3.2026 | 0.059559 | 2.946 | 3.0995 | 10 | 0.25734 | 20 |
| 14 | Accept | 5.7151 | 0.95614 | 2.946 | 3.0996 | 376 | 0.001001 | 43 |
| 15 | Accept | 3.207 | 1.3971 | 2.946 | 3.0937 | 499 | 0.027394 | 18 |
| 16 | Accept | 3.8606 | 0.15493 | 2.946 | 3.0937 | 36 | 0.041427 | 12 |
| 17 | Accept | 3.2026 | 1.0993 | 2.946 | 3.095 | 443 | 0.019836 | 76 |
| 18 | Accept | 3.4832 | 0.49205 | 2.946 | 3.0956 | 205 | 0.99989 | 8 |
| 19 | Accept | 5.6285 | 0.31967 | 2.946 | 3.0942 | 192 | 0.0022197 | 2 |
| 20 | Accept | 3.0896 | 0.49971 | 2.946 | 3.0938 | 188 | 0.023227 | 93 |
|====================================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | NumLearningC-| LearnRate | MaxNumSplits |
| | result | log(1+loss) | runtime | (observed) | (estim.) | ycles | | |
|====================================================================================================================|
| 21 | Accept | 3.1408 | 0.29373 | 2.946 | 3.0935 | 156 | 0.02324 | 5 |
| 22 | Accept | 4.691 | 0.046193 | 2.946 | 3.0941 | 12 | 0.076435 | 2 |
| 23 | Accept | 5.4686 | 0.14229 | 2.946 | 3.0935 | 50 | 0.0101 | 58 |
| 24 | Accept | 6.3759 | 0.087191 | 2.946 | 3.0893 | 23 | 0.0014716 | 22 |
| 25 | Accept | 6.1278 | 0.10032 | 2.946 | 3.094 | 47 | 0.0034406 | 2 |
| 26 | Accept | 5.9134 | 0.05991 | 2.946 | 3.0969 | 11 | 0.024712 | 12 |
| 27 | Accept | 3.401 | 0.34472 | 2.946 | 3.0995 | 151 | 0.067779 | 7 |
| 28 | Accept | 3.2757 | 0.45129 | 2.946 | 3.1009 | 198 | 0.032311 | 8 |
| 29 | Accept | 3.2296 | 0.085049 | 2.946 | 3.1023 | 17 | 0.30283 | 19 |
| 30 | Accept | 3.2385 | 0.24549 | 2.946 | 3.1027 | 83 | 0.21601 | 76 |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 22.8327 seconds
Total objective function evaluation time: 10.7519
Best observed feasible point:
NumLearningCycles LearnRate MaxNumSplits
_________________ _________ ____________
10 0.27157 7
Observed objective function value = 2.946
Estimated objective function value = 3.1219
Function evaluation time = 0.045202
Best estimated feasible point (according to models):
NumLearningCycles LearnRate MaxNumSplits
_________________ _________ ____________
10 0.30126 3
Estimated objective function value = 3.1027
Estimated function evaluation time = 0.05686
Mdl =
RegressionEnsemble
ResponseName: 'Y'
CategoricalPredictors: []
ResponseTransform: 'none'
NumObservations: 94
HyperparameterOptimizationResults: [1×1 classreg.learning.paramoptim.SupervisedLearningBayesianOptimization]
NumTrained: 10
Method: 'LSBoost'
LearnerNames: {'Tree'}
ReasonForTermination: 'Terminated normally after completing the requested number of training cycles.'
FitInfo: [10×1 double]
FitInfoDescription: {2×1 cell}
Regularization: []
Properties, Methods
Compare the loss to that of a boosted, unoptimized model, and to that of the default ensemble.
loss = kfoldLoss(crossval(Mdl,'kfold',10))loss = 19.2667
Mdl2 = fitrensemble(X,Y, ... 'Method','LSBoost', ... 'Learner',templateTree('Surrogate','on')); loss2 = kfoldLoss(crossval(Mdl2,'kfold',10))
loss2 = 30.4083
Mdl3 = fitrensemble(X,Y);
loss3 = kfoldLoss(crossval(Mdl3,'kfold',10))loss3 = 29.0495
For a different way of optimizing this ensemble, see Optimize Regression Ensemble Using Cross-Validation.