Automated Semantic Segmentation of Large Data Sets
Scientists and engineers leverage domain specific features/tools that support the entire workflow from labeling the ground truth, handling data from a wide variety of sources/formats, developing models and finally deploying these models. Users can scale their deployments optimally on GPU-based cloud infrastructure to build accelerated training and inference pipelines while working with big datasets. These environments are optimized for engineers to develop such functionality with ease and then scale against large datasets with Spark-based clusters on the cloud.
Published: 14 Dec 2020
Arvind Hosagrahara-- Arvind, are you there?
Is it shared? Whew.
It's OK.
I'd like to make up for time here, but I'm here to talk about automating the process of semantic segmentation of large data sets. In this particular talk, I'd be focusing on three main things.
The first one is a big picture-- what is semantic segmentation? How do you-- what is it useful for, and a quick demonstration of the results of such systems. Then, talking about architecture of how to build our systems to not only handle your Extract, Transform, and Load-- your ETL. Your training and inference is a series of pipelines that allow you to process larger data sets. The third part of the talk is to talk about the design considerations-- what we learned in putting together systems of this kind, discussing maturity models in building this, and talking a little bit about the infrastructure that surrounds it, and conclude.
So to start with, as the human race is moving towards safer transportation, you might have heard about automated driving or self-driving cars in the news. And what goes inside these self-driving cars can be broken up into three sets of functionality. The first one is perception, where the car knows where it is, what it's doing, be able to localize itself, and be able to sense the world through a variety of sensors-- cameras, radar, lidar-- a whole number of sensors that you can put on the car. Then go through a certain planning process to decide what to do, which then indicates to the control system the actions that need to be taken.
In today's talk, we are going to focus down only on the perception stack, and focus even further down just to the camera feeds, or the video or image processing side of it. And within that, focus down to just one particular kind of image processing called semantic segmentation. Semantic segmentation is the classification of every pixel in an image or video, giving an ability to simplify your processing to be able to figure out different classes of objects that the camera sees.
And the reason you do that is because it makes it easier to validate localization modules. And you can produce higher quality perception stack for the car to know exactly where it is. We want to automate this across larger data sets because the larger-- the more amount of data you can push through these pipelines, the better models you arrive at and faster design iterations. In this particular case, a video for a very standard data set is being classified out into bicyclists, pedestrians, and the road as well as the sky.
Though, why people are doing this is because-- there is a quote here from an interesting research paper that talks about the amount of data you need to be able to push through these systems to be able to demonstrate reliability in terms of outcomes. And they talk about millions of miles of data, hundreds of billions of miles of data, with a "b." It's a lot of data and a lot of work to be done.
And that's what makes the problem particularly challenging. In this particular case, as a problem statement, how do we accelerate the development of semantic segmentation models-- go from prototype to production; scale the workflows, capabilities, and engineering processes to be able to automate this and turn the crank to design iterations faster?
As headwind or challenges on this, we want to establish system and software engineering processes to take quick ideas-- prototypes and production. This is a very rapidly evolving space in research. Every year, there are new models. And I'll be showing you a little bit of what that looks like. Verify and validate this to modules to be used in safety critical systems, and be able to enable self-serve analytics to the data scientist, so that he can actually leverage the Cloud, handle bigger data sets, write less, and do more.
So I'll jump to a quick demonstration of the results showing what a typical iteration cycle looks like. In this particular case, here is a video. It's taken on the streets of Madrid. Off to your right is the famous football club Real Madrid in the stadium, their home ground.
I picked up this video because it has a number of features. And the front-facing camera of one of my colleague's car captured a little bit of video. As you turn design iterations on this, the first iteration is using a pre-trained model with absolutely no training data. And you can see that it tries to segment the image. This is actually a VGG-16 model from about 2015.
Doesn't do a very good job. If this is what my car was seeing, I would not feel very comfortable. But as you start processing through ETL pipelines, making sure that you're correcting for lens correction, adjusting, and color and contrast, you can start seeing these iterations get better and better at automatic semantic segmentation.
So in this case, you'll see that it's able to pick up the trees kind of well. And now, it gets a little better. It's able to see the road and trees with certain amount of-- with better resolution. It clearly gets better every design iterations. So what we're trying to do here is to build a system where you can turn the crank and produce a new design iteration, run against your large data set, validate it, measure accuracy.
As a fourth iteration, we switch over to a much more modern model, DeepLabv3. You can see that I'm now able to pick up the motorcyclist a little better. The road is still-- it's still very noisy, but the idea here is that all of this is being done without retraining, completely hands-free, in an automated fashion.
When I do contrast corrected, now we are beginning to look like better video. It's able to pick up the traffic signs. We're able to gradually improve the quality of this.
As a snapshot, if I were to switch out to a system where you have taken this, not just augmented your training data, but also added 3D simulation data, you'll get results where the semantic segmentation on top-- the noisy image, around here, on the top-- keeps getting refined until the point where you're doing pretty good semantic segmentation. You're able to see the road, and the sky, and the trees, the pedestrians. Your car is able to see the world a little better for it to be able to do it off the camera feeds.
So as a nutshell, this talk is-- the topic of semantic segmentation goes pretty deep, the techniques for doing this. It can be roughly spoken about the technique, and then the systems, and how do you scale it. In this particular case, you can see the results of a very standard data set-- the road, the sky, the trees, the buildings, other vehicles, and pedestrians being properly classified.
So with that, I wanted to leave a couple of slides here to say, this isn't a science experiment. There are industries such as-- a white paper by General Motors and The MathWorks talking about how to reconstruct these scenarios, and how to compare it with real recorded videos, taking all of this with the data, and scaling it up to a much larger data set out on the Cloud.
The other use case here is Caterpillar, where they were comparing different algorithms to select them, and taking it down all the way to their equipment. That's through code generation down. Some of these systems, again, scaling up to larger Cloud data sets.
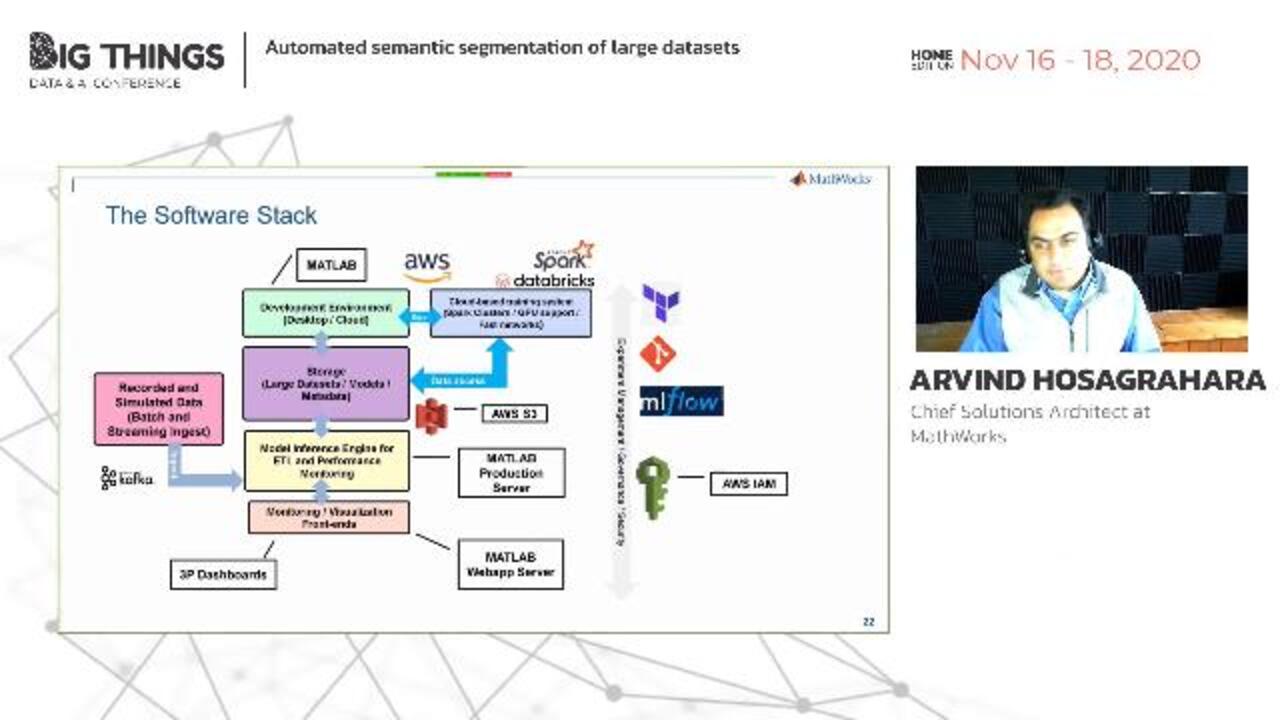
Which brings us to a system-- the architecture of a system-- on how to do this. Now, this picture is a system that we stood up on AWS for doing this kind of work. It's very busy. I'm going to try simplifying it a little bit.
At the high level, you've got several building blocks. For starters, a development environment-- both desktop-based and cloud-based-- that connects up to cloud-based storage, allowing you to ingest lots and lots of data. An ETL pipeline-- extract, transform, and load pipeline-- where you're enriching data as it comes in, being able to run these entrance engines and being able to connect it up to other systems; and monitoring-- for you to be able to see how your models are doing, assess accuracy, assess performance.
Finally, some parts of this are actually expensive. So being able to run a training-- and I will talk about a few benchmarks on these cloud-based systems-- it becomes important to ensure that you can burst up to the Cloud, where you can use bigger hardware and more data and faster networks, and ingest the recorded data, not just recorded, but synthetic data, simulated data, to augment your training sets where classes are missing.
So simplifying this, and simplifying this picture, you can break it up as a few pipelines. The first pipeline being ingesting data, enriching it as it comes while you store it. The second one is, as you train your data, to turn the crank on the training and build better models.
This is a space that you want to be able to-- if there's one thing constant about it, it is that these models are rapidly evolving. Newer models are being made available by the research community. And one thing we know for sure is that the state of the art is moving very quickly. So you want to be able to keep up with agility.
The third is to be able to offer that app as services, where you can actually connect it up to storage, and then ingest larger data sets while monitoring performance. As a software stack, what we do is build out the system on AWS using a set of technologies for orchestrating, for rebuilding this, for securing the data-- and just a quick snapshot of what the software stack would look like.
Taking a little deeper dive, we can break each of these three pipelines into the local experimentation, or how do you build these models. You can build them optimized for GPU execution. And, using higher level APIs, allow you to write less and do more. So language abstractions, such as the imageDataAugumenter or trainNetwork over here, allows you to supplement your training data with data that has been augmented for better accuracy. And all of this while tracking your experiments, sweeping it through different parameter-- hyperparameter settings, tracking how well your algorithm is doing, so applications that will actually help you pick models, assess the quality of what you're building as you build it.
As you do this, it becomes possible to burst this-- burst the need, and leverage bigger instances on the Cloud. Defining your infrastructure as code allows you to version and reproduce these results, and certainly leverage the latest hardware drivers and toolkits as they become available on cloud-based data centers.
There are APIs for command and control of these systems. So it's a very natural syntax where you can define what kind of machine you want to and scale up based on your needs. This also allows you to take your capital expenses and return them to operating expenses, as opposed to buying big, expensive, local machines and being able to rent out a machine to be able to do this kind of training work. Once executed, you do have the ability to store the training model so that you can fetch it and operationalize it on the entrance pipeline.
In this particular case, I wanted to share a few benchmarks. In this case, when we picked up a VGG-16-based network locally on a NVIDIA Quadro, you can see a well-behaved trace in performance. The training time keeps reducing until we reach a kind of asymptote based on the kind of architecture of the network.
So as your many batch sizes go beyond 32, you start reaching limits of what your GPU memory can handle, and performance degrades. So tuning these hyperparameters for the most ideal training, for the most amenable training, will allow you to then take it from local instances up to the Cloud, where you deal with single GPU instances, and then scale it upwards. The most expensive local set-up I was able to find represents almost a 2x from my starting point. And when I do burst this out of the Cloud, I'm running nearly 3x as fast, just completing a five-hour training task on a Titan in about just over an hour and a half. So that becomes one way that you're actually increase your-- you can scale your compute elegantly.
Once your model is available, plugging it into an entrance pipeline allows you to build Directed Acyclic Graphs of-- to be able to resolve Directed Acyclic Graphs of processing, so that any changes to your training model, your training data, any changes to the ETL code, all of this can be built. And you want to be able to turn the crank automatically to be able to produce a new iteration. These can be deployed as Cloud services. And we provide, on GitHub.com, reference templates for you to be able to quickly dovetail it into your systems.
This pipeline metadata, defined once, can be orchestrated in a completely automated fashion. To show you a few benchmarks off that, the performance of the frame throughput improves kind of linearly. We are able to scale up more machines, more CPUs. At this point, we had about 350 CPUs fully maxed out. And the same applies to GPU-- picking the right instance types, we'll be able to use these resources optimally. Finally, changing it to operating costs, you are able to build this and use it as you need.
The third pipeline is there's lot of value in handling big data sets to enrich the data as it comes in. Because every IOT problem is a big data problem in disguise. You want to be able to enrich and do as much of this on the smaller data set as you aggregate it to prevent very large bottlenecks with very large processing later on. As the ETL, what you're seeing here when I bring up code is the entirety of the code. So you're actually doing almost the entirety of the code. You are doing lots of work, writing less and doing more. In this particular case, on the ETL pipeline, things like lens coverage or corrections, contrast, and color, and-- there's a whole bunch of image-processing tasks that happen to be able to ingest the data in a form that you can actually scale it well.
So in this particular case, exposing that on Production Server as http-based services gives you the ability to leverage the different engineering formats that-- higher level toolboxes for dealing with this, and expose them as 24/7 365 services running proximal to your data and accelerated on GPU hardware. So putting it all together, these different pipelines bolt together in the form of build graphs where any deltas, or changes to either the stored version metadata, the training data by looking at the version metadata, changes to the code, changes to the model. All of this can be built out as a DAG that can then be triggered automatically, or via a CI/CD pipeline, connected to performance numbers.
At which point, this semantic segmentation system, that is the infrastructure stack behind it. Let's talk a little bit about the design considerations in building this. For semantic segmentation, leveraging Cloud storage allows you to ingest larger data sets, and scale up both your computing, both in terms of Capex and OpEx. These self-serve analytics, there are anti-patterns, having research and engineering roles separated. By making it self-serve, you are actually allowing your data scientists and researchers to be able to work more efficiently without building these ivory towers, and be able to work on a single problem by self-serving their needs for more compute.
As accuracy considerations, in our data set, you'll notice that certain classes, we have very few instances of symbols. That shows in the quality of the segmentation, if you may. You can always supplement that. And that's where simulation comes in.
So in our recorded data set, we may not have enough of a certain class. But it becomes very easy to generate scenes, be able to create synthetic data, be able to create synthetic scenes, which give you perfect semantic segmentation that you can use to augment your training data sets.
The last part is this particular space. And the community is evolving so rapidly that it's very important to interoperate. So being able to talk on ONNX, to be able to communicate with ONNX standards, and leverage transfer learning so that you can ingest the latest model structures, the latest model architectures, from a variety of different technologies, and import/export them to standards that are common in the industry. Being able to connect up to automated simulators. Being able to build these systems at scale so that they interoperate with the rest of the ecosystem is very important.
The last mile is being able to take that and push it down to GPUs, to CPUs, to embedded microcontrollers. The last mile to get into the vehicle and reiterate, that becomes another source of friction. Trying to do this-- trying to turn the crank quicker on that is always helpful. That is a topic by itself.
So zooming out all the way, to build out a system like this, that does automatic semantic segmentation, we can talk in terms of maturity. Starting with local experimentation, automating some part of the training, going down to model deployment, being able to measure your performance, to be able to automatically release your new models with full traceability, and manage environments down to a system that supports-- MLOps, which is allows you to do your machine learning but be able to do it in an automated fashion, retriggering both the training, and keeping it a traceable and governable way.
There are frameworks here. I've just left a reference to one such maturity model. But there are others out there. The need of a maturity model allows people to assess their software processes in an organization to see how they can actually build these systems in a continuous way as you actually develop and deploy.
The last part of this is while a researcher is testing his experiments locally, centralizing it at some point will allow you to collaborate with larger teams. And that becomes available. As security on the Cloud, we do use best practices-- access control lists for permissions, and Cloud services like IAM for making sure that the right people have access to the right data sets and the right services.
So in conclusion, building out these systems-- architecting it-- will allow you to turn the crank on automated semantic segmentations, scale it out on the Cloud, both in terms of compute, in terms of storage. And providing a smooth workflow reduces the friction for you to be able to turn the crank and produce new trained deep learning models. Doing this on the Cloud allows you to enable self-service analytics. And these techniques, even though this particular case has to do with self-driving cars, are equally applicable to other domains, such as medical geo-exploration, et cetera.
As key takeaways, build upon proven safety compliant and DevOps-ready development tools that to reduce friction, because you are using battle-tested strategies for doing this. Leveraging best in class simulation improves the quality of your output. It leads to faster time-to-market outcomes for ADAS development. And using domain specific tooling will allow practitioners in the space to write less and do more. So reduce the effort that it takes to be able to do this. Build it easily and quickly.
With that, I'd like to conclude by pointing to the virtual exhibit hall. Please feel free to stop by, meet our team, or post your questions, at which point I should be open for Q&A. I seem to be having a little audio issues in terms of not being able to hear the Q&A. But I'll try to do my best.
Hello, Arvind.
Yes. I can hear you now.
OK. That's fantastic. So I'm glad we managed to solve those technical issues. And we managed to get your talk. So that was a relief. Had me very worried for awhile there.
[LAUGHS] That makes both of us.
OK. I could see you were starting to panic. But you have--
No panic.
--this very calm and very soothing voice. So it was a pleasure to listen to you as you were giving us this talk. That was wonderful. Thank you.
Yeah. Thank you very much.
I think what we would like is for you to give us a bit more information on real-world applications, perhaps outside of driving, and how that might evolve in the future.
Correct. It turns out that being able to spot a pedestrian in an automated driving scenario is not too much different than being able to spot a cancer cell in an MRI scan, or to be able to spot features in medical imaging that are of interest. So deep learning systems like this are increasingly seeing adoption in being able to assist physicians for better medical outcomes.
In the manufacturing space, we see people that are actually trying to improve their manufacturing processes to be able to do predictive maintenance, to be able to do it based on visual feedback from equipment, cameras pointed to their assembly lines. There's a whole variety of techniques. But that's a whole different industry.
These techniques are also applicable in geo-exploration for people that are analyzing very large data sets of geographic information to spot natural resources, to explore the reserves of natural resources. So there's a whole variety of these kind of use cases across multiple industries. And we'd be very happy, if you connect up with us, to connect you up with experts in those spaces.
Well, hopefully a lot of our audience will do that via the networking section on the platform. So let me ask you another question, Arvind. Let's imagine that you return to Big Things next year-- Big Things '21. What do you think you'll be able to tell us then? What would you hope that you'll be able to tell us on how things have moved on?
Yes. There's a very exciting branch of research-- things like network architecture search, being able to find and spot the right architectures to make your problem fold correctly. Being able to do domain transfer, which is essentially map your simulation results to your recorded data-- and map that in a semantically accurate way, which is essentially allows you to get to your billion miles. It'll take 400 years to drive a fleet through billion miles, but that's where simulation comes into the picture.
And there's a lot of research. These models are evolving very rapidly. Just with the videos I showed you, we went from models from 2017, 2018, 2019. We're actually moving closer and closer to the bleeding edge of this. And if you do come back to Big Things Spain, we'd like to show you the latest iteration of that.
That would be great. Arvind, you showed us some very detailed slides there. There was a lot of information to take in. And I certainly didn't have time to unpack it all. Will we get a chance to have a look at these slides? Can we download them or view them somewhere?
Absolutely. We will try to make that accessible. I'll work with the organizers to make sure that we get them a print-ready copy of these slides. You may not have the videos, but everything else will be here. And this is--
Fantastic.
--a recorded session.
So it just remains for me to thank you so much, Arvind, for your time. I'm so glad that we managed to solve those technical issues. And hopefully, we'll see you again next year.
OK. Thank you so much. And I apologize for the technical issues. And--
Not at all.
--very nice to be able to present.
OK. Thank you so much, Arvind.

Featured Product
MATLAB Production Server
Up Next:


Related Videos:








Seleccione un país/idioma
Seleccione un país/idioma para obtener contenido traducido, si está disponible, y ver eventos y ofertas de productos y servicios locales. Según su ubicación geográfica, recomendamos que seleccione: United States.
También puede seleccionar uno de estos países/idiomas:
América
- América Latina (Español)
- Canada (English)
- United States (English)
Europa
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)