Ajustar un modelo exponencial a los datos
Este ejemplo muestra cómo ajustar un modelo exponencial a los datos con los algoritmos de región de confianza y Levenberg-Marquardt de mínimos cuadrados no lineales.
Cargue el conjunto de datos census.
load censusLas variables pop y cdate contienen datos sobre el tamaño de la población y el año en que se ha realizado el censo, respectivamente.
Muestre una gráfica de dispersión de los datos.
scatter(cdate,pop) xlabel("Year") ylabel("Population")
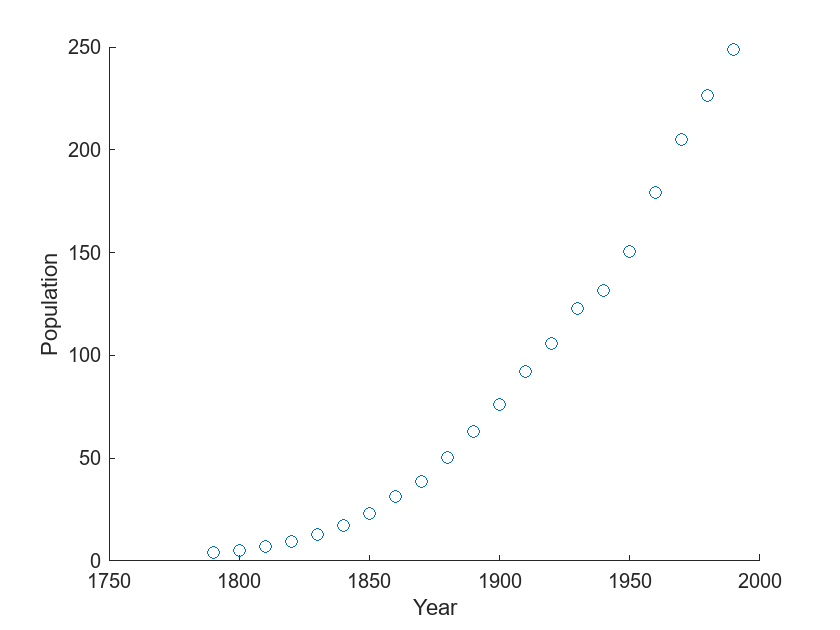
La gráfica muestra que la población aumenta año tras año con una forma que se asemeja a una función exponencial.
Ajuste un modelo exponencial de dos términos a los datos de población utilizando el algoritmo de ajuste predeterminado de región de confianza. Devuelva los resultados del ajuste y las estadísticas de bondad de ajuste.
[exp_tr,gof_tr] = fit(cdate,pop,"exp2")exp_tr =
General model Exp2:
exp_tr(x) = a*exp(b*x) + c*exp(d*x)
Coefficients (with 95% confidence bounds):
a = 7.169e-17
b = 0.02155
c = 0
d = 0.02155
gof_tr = struct with fields:
sse: 1.2412e+04
rsquare: 0.8995
dfe: 17
adjrsquare: 0.8818
rmse: 27.0209
exp_tr contiene los resultados del ajuste, incluyendo los coeficientes calculados con el algoritmo de ajuste de región de confianza. Las estadísticas de bondad de ajuste almacenadas en gof_tr incluyen la raíz del error cuadrático medio (RMSE) de 27.0209.
Represente el modelo de exp_tr junto con una gráfica de dispersión de los datos.
plot(exp_tr,cdate,pop) legend(["data","predicted value"]) xlabel("Year") ylabel("Population")
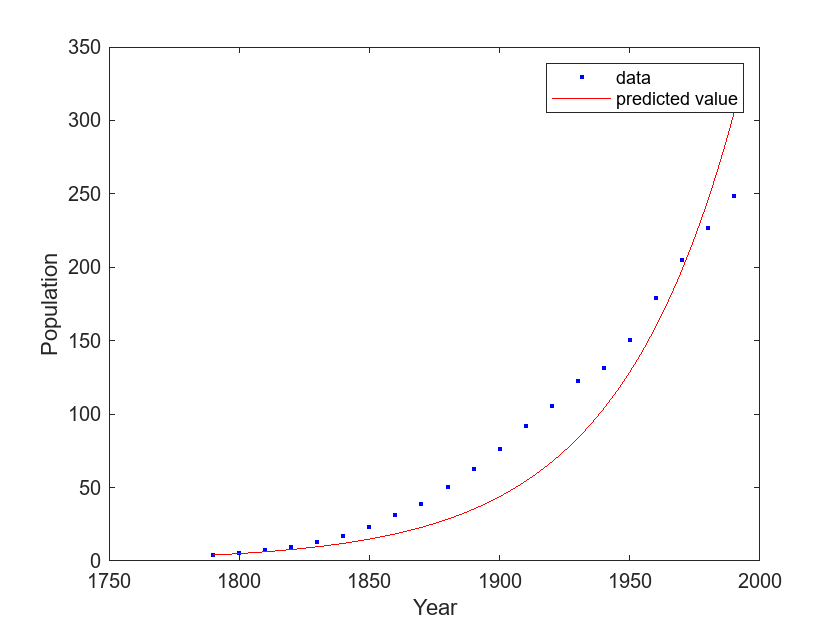
La gráfica muestra que el modelo de exp_tr no sigue de cerca los datos del censo.
Mejore el ajuste utilizando el algoritmo de ajuste Levenberg-Marquardt para calcular los coeficientes.
[exp_lm,gof_lm] = fit(cdate,pop,"exp2",Algorithm="Levenberg-Marquardt")
exp_lm =
General model Exp2:
exp_lm(x) = a*exp(b*x) + c*exp(d*x)
Coefficients (with 95% confidence bounds):
a = 4.282e-17 (-1.125e-11, 1.126e-11)
b = 0.02477 (-5.67, 5.719)
c = -3.933e-17 (-1.126e-11, 1.126e-11)
d = 0.02481 (-5.696, 5.745)
gof_lm = struct with fields:
sse: 475.9498
rsquare: 0.9961
dfe: 17
adjrsquare: 0.9955
rmse: 5.2912
exp_lm contiene los resultados del ajuste, incluyendo los coeficientes calculados con el algoritmo de ajuste Levenberg-Marquardt. Las estadísticas de bondad de ajuste almacenadas en gof_lm incluyen la RMSE de 5.2912, que es menor que la RMSE de exp_tr. Los tamaños relativos de las RMSE indican que el modelo almacenado en exp_lm se ajusta a los datos de forma más precisa que el modelo almacenado en exp_tr.
Represente el modelo de exp_lm junto con una gráfica de dispersión de los datos.
plot(exp_lm,cdate,pop) legend(["data","predicted value"]) xlabel("Year") ylabel("Population")
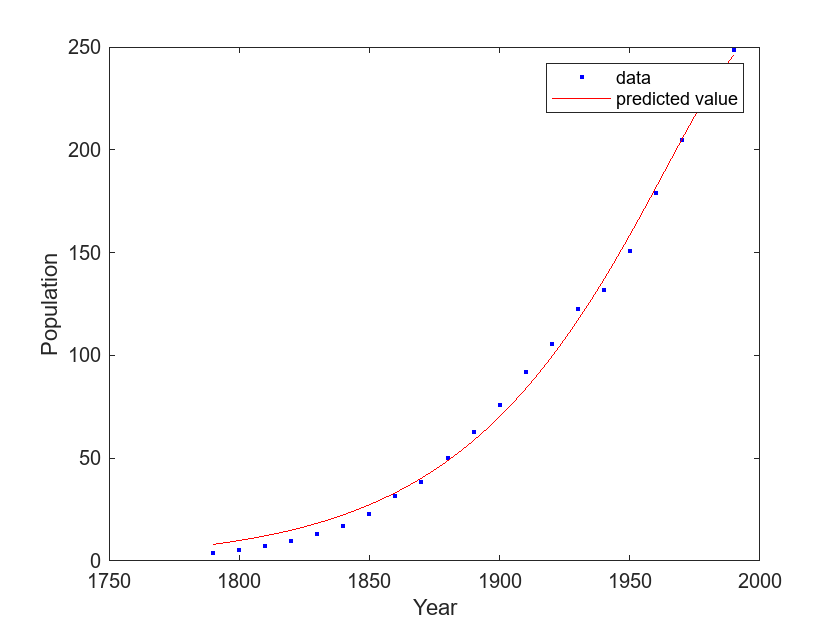
La gráfica muestra que el modelo de exp_lm sigue más de cerca los datos del censo que el modelo de exp_tr.