pcmatchfeatures
Find matching features between point clouds
Syntax
Description
indexPairs = pcmatchfeatures(features1,features2)
[
returns the normalized Euclidean distances between the matching features using any
combination of input arguments from previous syntaxes.indexPairs,scores] = pcmatchfeatures(___)
[___] = pcmatchfeatures(___,
specifies options using one or more name-value pair arguments in addition to any combination
of arguments in previous syntaxes. For example, Name,Value)'MatchThreshold',0.03
sets the normalized distance threshold for matching features to
0.03.
Examples
Load point cloud data from a MAT file.
ld = load("livingRoom.mat");
ptCloud1 = ld.livingRoomData{1};
ptCloud2 = ld.livingRoomData{2};Visualize the loaded point clouds.
figure pcshowpair(ptCloud1,ptCloud2)

Downsample the point clouds.
gridSize = 0.05; ptCloud1 = pcdownsample(ptCloud1,"gridNearest",gridSize); ptCloud2 = pcdownsample(ptCloud2,"gridNearest",gridSize);
Detect features in each point cloud.
features1 = extractFPFHFeatures(ptCloud1); features2 = extractFPFHFeatures(ptCloud2);
Find matching features.
indexPairs = pcmatchfeatures(features1,features2,ptCloud1,ptCloud2);
Select the matched points.
matchedPoints1 = select(ptCloud1,indexPairs(:,1)); matchedPoints2 = select(ptCloud2,indexPairs(:,2));
Visualize the matched features.
figure
pcshowMatchedFeatures(ptCloud1,ptCloud2,matchedPoints1,matchedPoints2,Method="montage")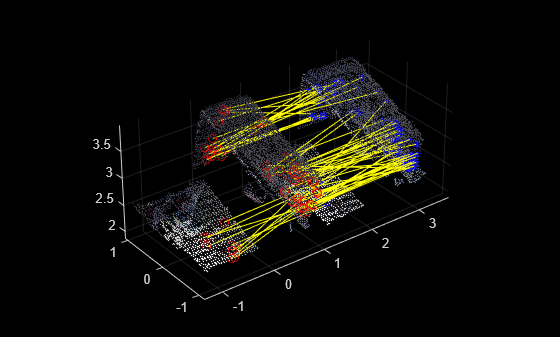
Input Arguments
Name-Value Arguments
Output Arguments
References
[1] Muja, Marius and David G. Lowe. "Fast Approximate Nearest Neighbors with Automatic Algorithm Configuration." In Proceedings of the Fourth International Conference on Computer Vision Theory and Applications, 331-40. Lisboa, Portugal: SciTePress - Science and Technology Publications, 2009. https://doi.org/10.5220/0001787803310340.
[2] Zhou, Qian-Yi, Jaesik Park, and Vladlen Koltun. "Fast global registration." In European Conference on Computer Vision, pp. 766-782. Springer, Cham, 2016.