Introducción a los almacenes de datos
¿Qué es un almacén de datos?
Un almacén de datos es un objeto para la lectura de un único archivo o una recopilación de archivos o datos. El almacén de datos actúa como repositorio para los datos que tienen la misma estructura y el mismo formato. Por ejemplo, cada uno de los archivos de un almacén de datos debe contener datos del mismo tipo (como numéricos o texto) que aparezcan en el mismo orden y separados por el mismo delimitador.
Un almacén de datos es útil cuando:
Cada uno de los archivos de la recopilación puede ser demasiado grande como para caber en la memoria. Un almacén de datos le permite leer y analizar datos de cada archivo en porciones más pequeñas que sí caben en la memoria.
Los archivos de la recopilación tienen nombres arbitrarios. Un almacén de datos actúa como un repositorio de archivos en una o más carpetas. No es necesario que los archivos tengan nombres secuenciales.
Puede crear un almacén de datos basado en el tipo de datos o aplicación. Los distintos tipos de almacenes de datos contienen propiedades que pertenecen al tipo de datos que admiten. Por ejemplo, consulte la siguiente tabla para obtener una lista de almacenes de datos de MATLAB®. Para obtener una lista completa de almacenes de datos, consulte Select Datastore for File Format or Application.
| Tipo de archivo o datos | Tipo de almacén de datos |
|---|---|
| Archivos de texto que contienen datos orientados a columnas, incluidos los archivos CSV. | TabularTextDatastore |
Archivos de imagen, incluidos los formatos admitidos por imread como JPEG y PNG. | ImageDatastore |
Archivos de hoja de cálculo con formatos de Excel® admitidos como .xlsx. | SpreadsheetDatastore |
Datos de pares clave-valor que son datos de entrada o salida de mapreduce. | KeyValueDatastore |
| Archivos Parquet que contienen datos orientados a columnas. | ParquetDatastore |
| Formatos de archivo personalizados. Requiere una función proporcionada para la lectura de datos. | FileDatastore |
Almacén de datos para crear puntos de control en arreglos tall. | TallDatastore |
Crear y leer a partir de un almacén de datos
Utilice la función tabularTextDatastore para crear un almacén de datos a partir del archivo de muestra airlinesmall.csv, que contiene la información de llegada y salida de vuelos de aerolíneas individuales. El resultado es un objeto TabularTextDatastore.
ds = tabularTextDatastore('airlinesmall.csv')ds =
TabularTextDatastore with properties:
Files: {
' ...\matlab\toolbox\matlab\demos\airlinesmall.csv'
}
Folders: {
' ...\matlab\toolbox\matlab\demos'
}
FileEncoding: 'UTF-8'
AlternateFileSystemRoots: {}
PreserveVariableNames: false
ReadVariableNames: true
VariableNames: {'Year', 'Month', 'DayofMonth' ... and 26 more}
DatetimeLocale: en_US
Text Format Properties:
NumHeaderLines: 0
Delimiter: ','
RowDelimiter: '\r\n'
TreatAsMissing: ''
MissingValue: NaN
Advanced Text Format Properties:
TextscanFormats: {'%f', '%f', '%f' ... and 26 more}
TextType: 'char'
ExponentCharacters: 'eEdD'
CommentStyle: ''
Whitespace: ' \b\t'
MultipleDelimitersAsOne: false
Properties that control the table returned by preview, read, readall:
SelectedVariableNames: {'Year', 'Month', 'DayofMonth' ... and 26 more}
SelectedFormats: {'%f', '%f', '%f' ... and 26 more}
ReadSize: 20000 rows
OutputType: 'table'
RowTimes: []
Write-specific Properties:
SupportedOutputFormats: ["txt" "csv" "xlsx" "xls" "parquet" "parq"]
DefaultOutputFormat: "txt"Después de crear el almacén de datos, puede previsualizar los datos sin tener que cargarlos todos en la memoria. Puede especificar variables (columnas) de interés mediante la propiedad SelectedVariableNames para previsualizar o leer únicamente dichas variables.
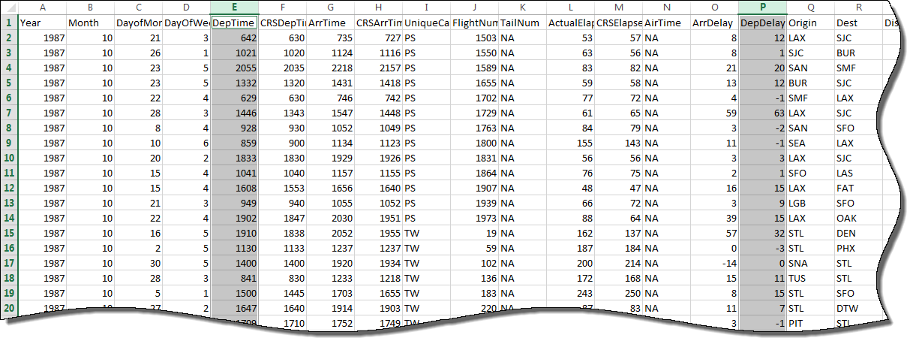
ds.SelectedVariableNames = {'DepTime','DepDelay'};
preview(ds)ans =
8×2 table
DepTime DepDelay
_______ ________
642 12
1021 1
2055 20
1332 12
629 -1
1446 63
928 -2
859 -1 Puede especificar los valores de los datos que representen valores ausentes. En airlinesmall.csv, los valores ausentes se representan con NA.
ds.TreatAsMissing = 'NA';Si todos los datos del almacén de datos de las variables de interés caben en la memoria, puede leerlos mediante la función readall.
T = readall(ds);
De lo contrario, lea los datos en subconjuntos más pequeños que sí caben en la memoria mediante la función read. De forma predeterminada, la función read lee 20.000 filas a la vez a partir de un TabularTextDatastore. Sin embargo, puede cambiar este valor asignando un nuevo valor a la propiedad ReadSize.
ds.ReadSize = 15000;
Restablezca el almacén de datos a su estado inicial antes de volver a leerlo mediante la función reset. Llamando a la función read en un bucle while, puede realizar cálculos intermedios en todos los subconjuntos de datos y luego sumar los resultados intermedios al final. Este código calcula el valor máximo de la variable DepDelay.
reset(ds) X = []; while hasdata(ds) T = read(ds); X(end+1) = max(T.DepDelay); end maxDelay = max(X)
maxDelay =
1438Si los datos de cada archivo individual caben en la memoria, puede especificar que cada una de las llamadas a read debe leer un archivo completo en lugar de un número de filas concreto.
reset(ds) ds.ReadSize = 'file'; X = []; while hasdata(ds) T = read(ds); X(end+1) = max(T.DepDelay); end maxDelay = max(X);
Además de leer subconjuntos de datos en un almacén de datos, puede aplicar las funciones map y reduce en el almacén de datos mediante mapreduce o crear un arreglo alto mediante tall. Para obtener más información, consulte Getting Started with MapReduce y Arreglos altos para datos con memoria insuficiente.
Consulte también
tabularTextDatastore | imageDatastore | spreadsheetDatastore | KeyValueDatastore | fileDatastore | tall | mapreduce