classperformance Properties
Classifier performance information
To view the performance-related information of a classifier, create a
classperformance object by using the classperf function. Use dot notation to access the object properties, such as
CorrectRate, ErrorRate,
Sensitivity, and Specificity.
Name and Description
Name of the classifier object, specified as a character vector. Use dot notation to set this property.
Example:
'cp_kfold'
Data Types: char
Description of the object, specified as a character vector. Use dot notation to set this property.
Example:
'performance_data_kfold'
Data Types: char
True Labels and Indices
This property is read-only.
Unique set of true labels from groundTruth, specified as a
vector of positive integers or cell array of character vectors. This property is
equivalent to the output when you run
unique(.groundTruth)
Example:
{'ovarian','liver','normal'}
Data Types: double | cell
This property is read-only.
True labels for all observations in your data set, specified as a vector of positive integers or cell array of character vectors.
Example:
{'ovarian','liver','normal','ovarian','ovarian','liver'}
Data Types: double | cell
This property is read-only.
Number of observations in your data set, specified as a positive integer.
Example:
200
Data Types: double
Indices to the control classes from the true labels
(ClassLabels), specified as a vector of positive integers. This
property indicates the control (or negative) classes in the diagnostic test. By default,
ControlClasses contains all classes other than the first class
returned by grp2idx(.groundTruth)
You can set this property by using dot notation or the 'Negative'
name-value pair argument with the classperf function.
Example:
[3]
Data Types: double
Indices to the target classes from the true labels
(ClassLabels), specified as a vector of positive integers. This
property indicates the target (or positive) classes in the diagnostic test. By default,
TargetClasses contains the first class returned by
grp2idx(.groundTruth)
You can set this property by using dot notation or the 'Positive'
name-value pair argument with the classperf function.
Example:
[1 2]
Data Types: double
Sample and Error Distributions
This property is read-only.
Number of evaluations for each sample during the validation, specified as a numeric
vector. For example, if you use resubstitution, SampleDistribution is
a vector of ones and ValidationCounter = 1. If you have a 10-fold
cross-validation, SampleDistribution is also a vector of ones, but
ValidationCounter = 10.
SampleDistribution is useful when performing Monte Carlo
partitions of the test sets, and it can help determine if each sample is tested an equal
number of times.
Example:
[0 0 2 0]
Data Types: double
This property is read-only.
Frequency of misclassification of each sample, specified as a numeric vector.
Example:
[0 0 1 0]
Data Types: double
This property is read-only.
Frequency of the true classes during the validation, specified as a numeric vector.
Example:
[10 10 0]
Data Types: double
This property is read-only.
Frequency of errors for each class during the validation, specified as a numeric vector.
Example:
[0 0 0]
Data Types: double
Performance Statistics
This property is read-only.
Number of validations, specified as a positive integer.
Example:
10
Data Types: double
This property is read-only.
Classification confusion matrix, specified as a numeric array. The order of the rows
and columns in the matrix is the same as in grp2idx(groundTruth).
Columns represent the true classes, and rows represent the classifier prediction. The
last row in CountingMatrix is reserved for counting inconclusive
results.
Example:
[10 0 0;0 10 0; 0 0 0; 0 0 0]
Data Types: double
This property is read-only.
Correct rate of the classifier, specified as a positive scalar.
CorrectRate is defined as the number of correctly classified
samples divided by the number of classified samples. Inconclusive results are not
counted.
Example: 1
Data Types: double
This property is read-only.
Error rate of the classifier, specified as a positive scalar.
ErrorRate is defined as the number of incorrectly classified
samples divided by the number of classified samples. Inconclusive results are not
counted.
Example: 0
Data Types: double
This property is read-only.
Correct rate of the classifier during the last validation run, specified as a
positive scalar. In contrast with CorrectRate,
LastCorrectRate only applies to the evaluated samples from the
most recent validation run of the classifier performance object.
Example:
1
Data Types: double
This property is read-only.
Error rate of the classifier during the last validation run, specified as a positive
scalar. In contrast with ErrorRate,
LastErrorRate only applies to the evaluated samples from the most
recent validation run of the classifier performance object.
Example:
0
Data Types: double
This property is read-only.
Inconclusive rate of the classifier, specified as a positive scalar.
InconclusiveRate is defined as the number of nonclassified
(inconclusive) samples divided by the total number of samples.
Example:
0
Data Types: double
This property is read-only.
Classified rate of the classifier, specified as a positive scalar.
ClassifiedRate is defined as the number of classified samples
divided by the total number of samples.
Example:
1
Data Types: double
This property is read-only.
Sensitivity of the classifier, specified as a positive scalar.
Sensitivity is defined as the number of correctly classified
positive samples divided by the number of true positive samples.
Inconclusive results that are true positives are counted as errors for computing
Sensitivity. In other words, inconclusive results can decrease the
diagnostic value of the test.
Example:
1
Data Types: double
This property is read-only.
Specificity of the classifier, specified as a positive scalar.
Specificity is defined as the number of correctly classified
negative samples divided by the number of true negative samples.
Inconclusive results that are true negatives are counted as errors for computing
Specificity. In other words, inconclusive results can decrease the
diagnostic value of the test.
Example:
0.8
Data Types: double
This property is read-only.
Positive predictive value of the classifier, specified as a positive scalar.
PositivePredictiveValue is defined as the number of correctly
classified positive samples divided by the number of positive classified samples.
Inconclusive results are classified as negative when computing
PositivePredictiveValue.
Example:
1
Data Types: double
This property is read-only.
Negative predictive value of the classifier, specified as a positive scalar.
NegativePredictiveValue is defined as the number of correctly
classified negative samples divided by the number of negative classified samples.
Inconclusive results are classified as positive when computing
NegativePredictiveValue.
Example:
1
Data Types: double
This property is read-only.
Positive likelihood of the classifier, specified as a positive scalar.
PositiveLikelihood is defined as
Sensitivity / (1 -
Specificity)
Example: 5
Data Types: double
This property is read-only.
Negative likelihood of the classifier, specified as a positive scalar.
NegativeLikelihood is defined as (1 -
.Sensitivity)/Specificity
Example: 0
Data Types: double
This property is read-only.
Prevalence of the classifier, specified as a positive scalar.
Prevalence is defined as the number of true positive samples
divided by the total number of samples.
Example:
1
Data Types: double
This property is read-only.
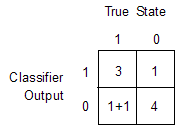
Diagnostic table, specified as a two-by-two numeric array. The first row indicates the number of samples classified as positive, with the number of true positives in the first column and the number of false positives in the second column. The second row indicates the number of samples classified as negative, with the number of false negatives in the first column and the number of true negatives in the second column.
Correct classifications appear in the diagonal elements and errors appear in the off-diagonal elements. Inconclusive results are considered errors and are counted in the off-diagonal elements. For an example, see Diagnostic Table Example.
Example:
[20 0;0 0]
Data Types: double
More About
Suppose that a cancer study of 10 patients yields these results.
| Patient | Classifier Output | Has Cancer |
|---|---|---|
| 1 | Positive | Yes |
| 2 | Positive | Yes |
| 3 | Positive | Yes |
| 4 | Positive | No |
| 5 | Negative | Yes |
| 6 | Negative | No |
| 7 | Negative | No |
| 8 | Negative | No |
| 9 | Negative | No |
| 10 | Inconclusive | Yes |
Using these results, the function computes the DiagnosticTable as
follows:
Version History
Introduced before R2006a
See Also
classperf | crossvalind | classify | grp2idx
MATLAB Command
You clicked a link that corresponds to this MATLAB command:
Run the command by entering it in the MATLAB Command Window. Web browsers do not support MATLAB commands.
Seleccione un país/idioma
Seleccione un país/idioma para obtener contenido traducido, si está disponible, y ver eventos y ofertas de productos y servicios locales. Según su ubicación geográfica, recomendamos que seleccione: .
También puede seleccionar uno de estos países/idiomas:
Cómo obtener el mejor rendimiento
Seleccione China (en idioma chino o inglés) para obtener el mejor rendimiento. Los sitios web de otros países no están optimizados para ser accedidos desde su ubicación geográfica.
América
- América Latina (Español)
- Canada (English)
- United States (English)
Europa
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)