Filtrar y suavizar datos
Acerca del filtrado y el suavizado de datos
Este tema explica cómo suavizar datos de respuesta utilizando esta función. Con la función smooth, puede utilizar métodos opcionales para filtros de media móvil, de Savitzky-Golay y de regresión local con o sin ponderación y robustez (lowess, loess, rlowess y rloess). Consulte smoothdata para ver más funcionalidades, incluida la compatibilidad con matrices, tablas y horarios, así como con los métodos de mediana móvil y de Gauss.
Filtrado de media móvil
Un filtro de media móvil suaviza datos sustituyendo cada punto de datos por el promedio de los puntos de datos vecinos definidos dentro del lapso. Este proceso es equivalente al filtrado lowpass con la respuesta del suavizado dada por la ecuación de diferencias
donde ys(i) es el valor suavizado para el punto de datos i-ésimo, N es el número de puntos de datos vecinos a ambos lados de ys(i) y 2N+1 es el lapso.
El método de suavizado de media móvil que utiliza Curve Fitting Toolbox™ sigue estas reglas:
El lapso debe ser impar.
El punto de datos que suavizar debe estar en el centro del lapso.
El lapso se ajusta para puntos de datos que no pueden acomodar el número especificado de vecinos a cada lado.
Los extremos de línea no se suavizan porque el lapso no se puede definir.
Tenga en cuenta que puede utilizar la función filter para implementar ecuaciones de diferencias como la que aparece arriba. Sin embargo, dada la forma en que se tratan los extremos de línea, el resultado de la media móvil de la toolbox diferirá del resultado devuelto por filter. Consulte Ecuaciones de diferencias y filtrado para obtener más información.
Por ejemplo, suponga que suaviza datos con un filtro de media móvil con un lapso de 5. Con las reglas descritas anteriormente, los primeros cuatro elementos de ys vienen dados por
ys(1) = y(1) ys(2) = (y(1)+y(2)+y(3))/3 ys(3) = (y(1)+y(2)+y(3)+y(4)+y(5))/5 ys(4) = (y(2)+y(3)+y(4)+y(5)+y(6))/5
Tenga en cuenta que ys(1), ys(2), ... , ys(end) se refieren al orden de los datos después de haberse ordenado, y no necesariamente al orden original.
A continuación se muestran los valores suavizados y los lapsos para los primeros cuatro puntos de datos de un conjunto de datos generado.
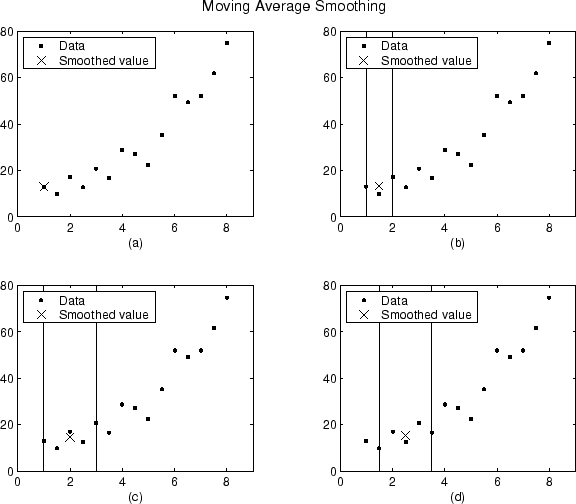
La gráfica (a) indica que el primer punto de datos no está suavizado porque no se puede construir un lapso. La gráfica (b) indica que el segundo punto de datos se suaviza con un lapso de tres. Las gráficas (c) y (d) indican que se utiliza un lapso de cinco para calcular el valor suavizado.
Filtro Savitzky-Golay
El filtro Savitzky-Golay se puede entender como una media móvil generalizada. Deriva los coeficientes del filtro realizando un ajuste de mínimos cuadrados lineales no ponderados con un polinomio de determinado grado. Por esta razón, el filtro Savitzky-Golay también se llama filtro polinomial de suavizado digital o filtro de suavizado de mínimos cuadrados. Tenga en cuenta que un polinomio de mayor grado hace que sea posible lograr un alto nivel de suavizado sin atenuar las características de los datos.
El método de filtrado Savitzky-Golay se suele utilizar con datos de frecuencia o con datos espectroscópicos (picos). En datos de frecuencia, el método resulta efectivo para preservar los componentes de alta frecuencia de la señal. En datos espectroscópicos, el método resulta efectivo para preservar momentos más elevados del pico como la anchura de línea. Por comparación, el filtro de media móvil suele dejar fuera una porción significativa del contenido de alta frecuencia de la señal, y solo puede preservar los momentos más bajos de un pico, como el centroide. Sin embargo, el filtrado Savitzky-Golay puede resultar menos efectivo que un filtro de media móvil para rechazar el ruido.
El método de suavizado Savitzky-Golay utilizado por el software de Curve Fitting Toolbox sigue estas normas:
El lapso debe ser impar.
El grado del polinomio debe ser menor que el lapso.
No es necesario que los puntos de datos tengan un espaciamiento uniforme.
Normalmente, el filtrado Savitzky-Golay requiere un espaciamiento uniforme de los datos predictores. Sin embargo, el algoritmo de Curve Fitting Toolbox admite espaciamiento no uniforme. Por lo tanto, no tiene que realizar un paso adicional de filtrado para crear datos con espaciamiento uniforme.
La gráfica que se muestra a continuación muestra datos de Gauss generados y varios intentos de suavizado con el método Savitzky-Golay. Los datos son muy con ruido y las anchuras de pico varían de amplias a estrechas. El lapso es igual al 5% del número de puntos de datos.
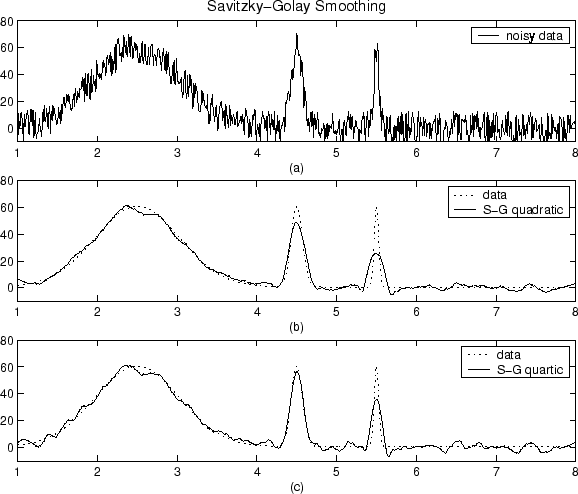
La gráfica (a) muestra los datos con ruido. Para comparar más fácilmente los resultados suavizados, las gráficas (b) y (c) muestran los datos sin el ruido añadido.
La gráfica (b) muestra el resultado de suavizar con un polinomio cuadrático. Tenga en cuenta que el método no tiene un buen desempeño para los picos estrechos. La gráfica (c) muestra el resultado de suavizar con un polinomio cuaternario. En general, los polinomios de mayor grado pueden capturar con mayor precisión las alturas y anchuras de los picos estrechos, pero tienen un peor rendimiento al suavizar los picos más anchos.
Suavizado de regresión local
Lowess y Loess
Los nombres "lowess" y "loess" derivan del término en inglés "locally weighted scatter plot smooth" (suavizado de gráfica de dispersión ponderada localmente), ya que ambos métodos utilizan regresión lineal ponderada localmente para suavizar datos.
El proceso de suavizado se considera local porque, como en el método de la media móvil, cada valor suavizado se determina por los puntos de datos vecinos definidos dentro del lapso. El proceso es ponderado porque se define una función de regresión ponderada para los puntos de datos contenidos dentro del lapso. Además de la función de regresión ponderada, puede utilizar una función de ponderación robusta, que hace que el proceso sea resistente a valores atípicos. Por último, los métodos se diferencian por el modelo que se utiliza en la regresión: lowess utiliza un polinomio lineal, mientras que loess utiliza un polinomio cuadrático.
Los métodos de regresión local utilizados por Curve Fitting Toolbox siguen estas reglas:
El lapso puede ser par o impar.
Puede especificar el lapso como un porcentaje del número total de puntos de datos en el conjunto de datos. Por ejemplo, un lapso de 0,1 utiliza el 10% de los puntos de datos.
El método de regresión local
El proceso de suavizado de regresión local sigue estos pasos para cada punto de datos:
Calcule las ponderaciones de regresión para cada punto de datos del lapso. Las ponderaciones vienen dadas por la función tricubo que se muestra a continuación.
x es el valor de predicción asociado con el valor de respuesta que suavizar, xi son los vecinos más cercanos de x como los define el lapso y d(x) es la distancia a lo largo de la abscisa desde x hasta el valor de predicción más distante dentro del lapso. Las ponderaciones tienen estas características:
Los puntos de datos que suavizar tienen la mayor ponderación y la mayor influencia sobre el ajuste.
Los puntos de datos fuera del lapso tienen ponderación cero y ninguna influencia sobre el ajuste.
Se realiza una regresión de mínimos cuadrados lineales ponderados. Para lowess, la regresión utiliza un polinomio de primer grado. Para loess, la regresión utiliza un polinomio de segundo grado.
El valor suavizado viene dado por la regresión ponderada en el valor de predicción de interés.
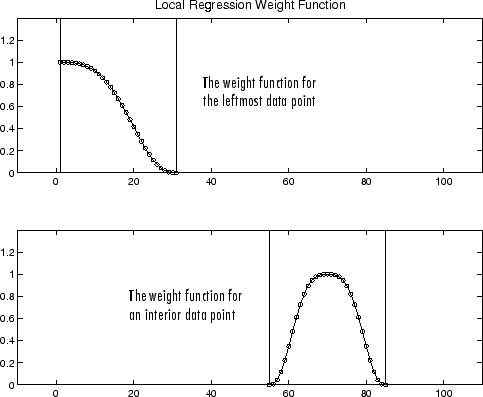
Si el cálculo de suavizado implica el mismo número de puntos de datos vecinos a ambos lados del punto de datos suavizado, la función de ponderación es simétrica. Sin embargo, si el número de puntos vecinos no es simétrico en torno al punto de datos suavizado, entonces la función de ponderación no es simétrica. Tenga en cuenta que, a diferencia del proceso de suavizado de media móvil, el lapso nunca cambia. Por ejemplo, cuando suaviza el punto de datos con el valor de predicción más pequeño, la forma de la función de ponderación se trunca por la mitad, el punto de datos más a la izquierda del lapso tiene la ponderación mayor y todos los puntos vecinos se encuentran a la derecha del valor suavizado.
A continuación se muestra la función de ponderación para un extremo de datos y para un punto interior, en un lapso de 31 puntos de datos.
A continuación se muestran los valores suavizados y las regresiones asociadas para los primeros cuatro puntos de datos de un conjunto de datos generado con el método lowess y un lapso de cinco.
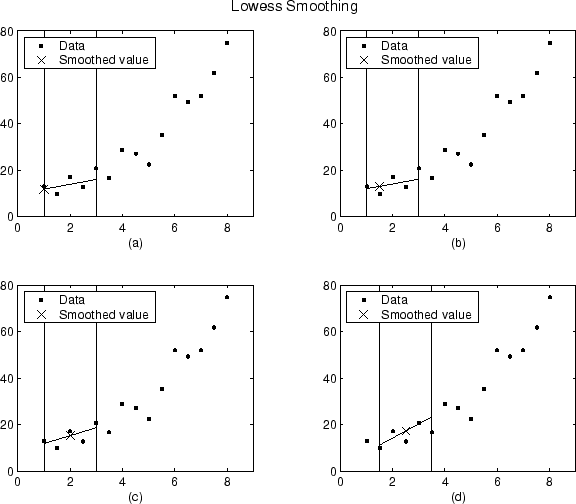
Tenga en cuenta que el lapso no cambia a medida que el proceso de suavizado avanza de un punto de datos a otro. Sin embargo, según el número de vecinos más cercanos, puede que la función de ponderación de regresión no sea simétrica sobre el punto de datos que suavizar. En concreto, las gráficas (a) y (b) utilizan una función de ponderación asimétrica, mientras que las gráficas (c) y (d) utilizan una función de ponderación simétrica.
Para el método loess, las gráficas tendrían el mismo aspecto excepto que el valor suavizado estaría generado por un polinomio de segundo grado.
Regresión local robusta
Si sus datos contienen valores atípicos, los valores suavizados pueden distorsionarse y no reflejar el comportamiento del grueso de los puntos de datos vecinos. Para resolver este problema, puede suavizar los datos con un procedimiento robusto que no esté influenciado por una pequeña fracción de valores atípicos. Para obtener una descripción de valores atípicos, consulte Análisis de valores residuales.
El software de Curve Fitting Toolbox ofrece una versión robusta para los métodos de suavizado lowess y loess. Estos métodos robustos incluyen un cálculo adicional de ponderaciones robustas, resistentes a los valores atípicos. El procedimiento de suavizado robusto sigue estos pasos:
Calcula los valores residuales del procedimiento suavizado descrito en la sección anterior.
Calcula las ponderaciones robustas para cada punto de datos del lapso. Las ponderaciones vienen dadas por la función bicuadrada,
donde ri es el valor residual del punto de datos i-ésimo producido por el procedimiento de suavizado de regresión y MAD es la desviación absoluta mediana de los valores residuales,
La desviación absoluta mediana es una medición de cómo de dispersos están los valores residuales. Si ri es menor que 6MAD, entonces la ponderación robusta está cerca de 1. Si ri es mayor que 6MAD, la ponderación robusta es 0 y el punto de datos asociado se excluye del cálculo de suavizado.
Suavice los datos de nuevo con las ponderaciones robustas. El valor suavizado final se calcula con la ponderación de regresión local y la ponderación robusta.
Repita los dos pasos anteriores hasta un total de cinco iteraciones.
A continuación se comparan los resultados suavizados del procedimiento lowess con los resultados del procedimiento lowess robusto para un conjunto de datos generado que contiene un único valor atípico. El lapso para ambos procedimientos es 11 puntos de datos.
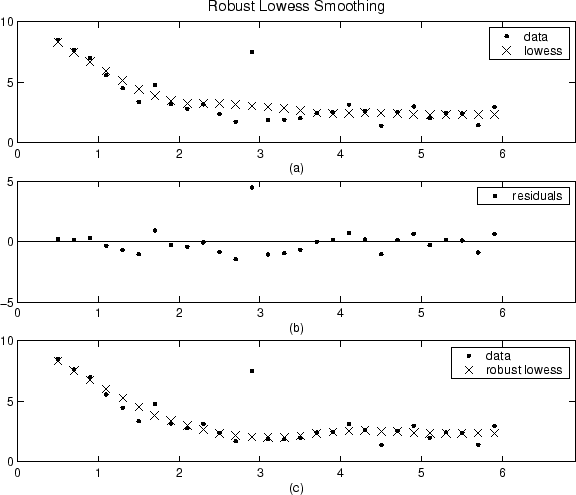
La gráfica (a) muestra que los valores atípicos influyen al valor suavizado en varios de los vecinos más cercanos. La gráfica (b) sugiere que el valor residual de los valores atípicos es mayor de seis desviaciones absolutas medianas. Por lo tanto, la ponderación robusta es cero para este punto de datos. La gráfica (c) muestra que los valores suavizados vecinos a los valores atípicos reflejan el grueso de los datos.
Ejemplo: Suavizar datos
Cargue los datos en count.dat:
load count.dat
El arreglo count de 24 por 3 contiene recuentos de tráfico en tres intersecciones para cada hora del día.
Primero, utilice un filtro de media móvil con un lapso de cinco horas para suavizar todos los datos de una vez (por índice lineal):
c = smooth(count(:)); C1 = reshape(c,24,3);
Represente los datos originales y los datos suavizados:
subplot(3,1,1)
plot(count,':');
hold on
plot(C1,'-');
title('Smooth C1 (All Data)')Segundo, utilice el mismo filtro para suavizar cada columna de datos de forma independiente:
C2 = zeros(24,3);
for I = 1:3,
C2(:,I) = smooth(count(:,I));
endDe nuevo, represente los datos originales y los datos suavizados:
subplot(3,1,2)
plot(count,':');
hold on
plot(C2,'-');
title('Smooth C2 (Each Column)')Represente la diferencia entre los dos conjuntos de datos representados:
subplot(3,1,3)
plot(C2 - C1,'o-')
title('Difference C2 - C1')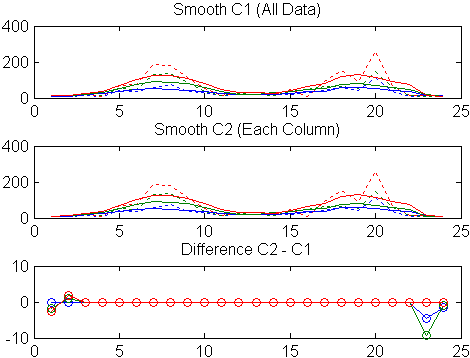
Observe los efectos finales adicionales del suavizado de tres columnas.
Ejemplo: Suavizar datos con loess y loess robusto
Cree datos con ruido con valores atípicos:
x = 15*rand(150,1); y = sin(x) + 0.5*(rand(size(x))-0.5); y(ceil(length(x)*rand(2,1))) = 3;
Suavice los datos con los métodos loess y rloess con un lapso del 10%:
yy1 = smooth(x,y,0.1,'loess'); yy2 = smooth(x,y,0.1,'rloess');
Represente los datos originales y los datos suavizados.
[xx,ind] = sort(x);
subplot(2,1,1)
plot(xx,y(ind),'b.',xx,yy1(ind),'r-')
set(gca,'YLim',[-1.5 3.5])
legend('Original Data','Smoothed Data Using ''loess''',...
'Location','NW')
subplot(2,1,2)
plot(xx,y(ind),'b.',xx,yy2(ind),'r-')
set(gca,'YLim',[-1.5 3.5])
legend('Original Data','Smoothed Data Using ''rloess''',...
'Location','NW')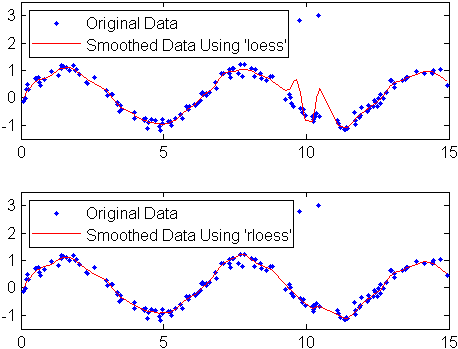
Observe que los valores atípicos tienen menos influencia en el método robusto.