trainAutoencoder
Entrenar un codificador automático
Sintaxis
Descripción
autoenc = trainAutoencoder(X,hiddenSize)autoenc, con el tamaño de la representación oculta de hiddenSize.
autoenc = trainAutoencoder(___,Name,Value)autoenc, para cualquiera de los argumentos de entrada anteriores con opciones adicionales especificadas por uno o varios argumentos de par Name,Value.
Por ejemplo, puede especificar la proporción de esparsidad o el número máximo de iteraciones de entrenamiento.
Ejemplos
Cargue los datos de muestra.
X = abalone_dataset;
X es una matriz de 8 por 4177 que define ocho atributos para 4177 conchas de abulón diferentes: sexo (M, F e I [para crías]), longitud, diámetro, altura, peso total, peso desconchado, peso de las vísceras y peso de la concha. Para obtener más información sobre el conjunto de datos, escriba help abalone_dataset en la línea de comandos.
Entrene un codificador automático esparso con la configuración predeterminada.
autoenc = trainAutoencoder(X);

Reconstruya los datos de anillos de conchas de abulón utilizando el codificador automático entrenado.
XReconstructed = predict(autoenc,X);
Calcule el error de reconstrucción cuadrático medio.
mseError = mse(X-XReconstructed)
mseError = 0.0167
Cargue los datos de muestra.
X = abalone_dataset;
X es una matriz de 8 por 4177 que define ocho atributos para 4177 conchas de abulón diferentes: sexo (M, F e I [para crías]), longitud, diámetro, altura, peso total, peso desconchado, peso de las vísceras y peso de la concha. Para obtener más información sobre el conjunto de datos, escriba help abalone_dataset en la línea de comandos.
Entrene un codificador automático esparso con tamaño oculto 4, 400 épocas máximas y función de transferencia lineal para el decodificador.
autoenc = trainAutoencoder(X,4,'MaxEpochs',400,... 'DecoderTransferFunction','purelin');
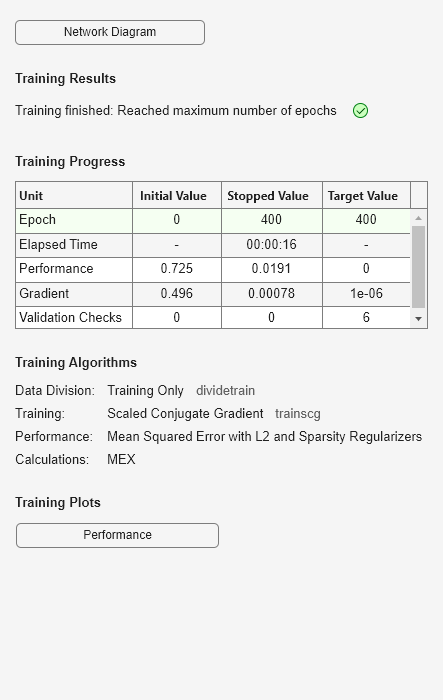
Reconstruya los datos de anillos de conchas de abulón utilizando el codificador automático entrenado.
XReconstructed = predict(autoenc,X);
Calcule el error de reconstrucción cuadrático medio.
mseError = mse(X-XReconstructed)
mseError = 0.0048
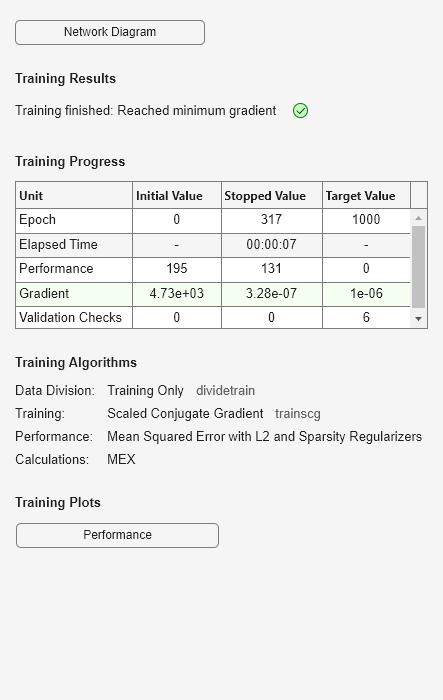
Genere los datos de entrenamiento.
rng(0,'twister'); % For reproducibility n = 1000; r = linspace(-10,10,n)'; x = 1 + r*5e-2 + sin(r)./r + 0.2*randn(n,1);
Entrene el codificador automático con los datos de entrenamiento.
hiddenSize = 25; autoenc = trainAutoencoder(x',hiddenSize,... 'EncoderTransferFunction','satlin',... 'DecoderTransferFunction','purelin',... 'L2WeightRegularization',0.01,... 'SparsityRegularization',4,... 'SparsityProportion',0.10);
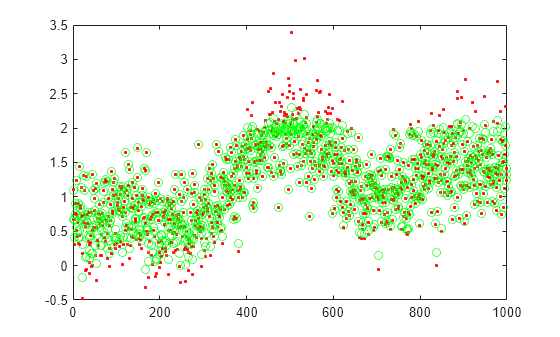
Genere los datos de prueba.
n = 1000; r = sort(-10 + 20*rand(n,1)); xtest = 1 + r*5e-2 + sin(r)./r + 0.4*randn(n,1);
Prediga los datos de prueba con el codificador automático entrenado, autoenc.
xReconstructed = predict(autoenc,xtest');
Represente los datos de prueba reales y las predicciones.
figure; plot(xtest,'r.'); hold on plot(xReconstructed,'go');
Cargue los datos de entrenamiento.
XTrain = digitTrainCellArrayData;
Los datos de entrenamiento son un arreglo de 1 por 5000 celdas, donde cada celda contiene una matriz de 28 por 28 que representa una imagen sintética de un dígito manuscrito.
Entrene un codificador automático con una capa oculta que contenga 25 neuronas.
hiddenSize = 25; autoenc = trainAutoencoder(XTrain,hiddenSize,... 'L2WeightRegularization',0.004,... 'SparsityRegularization',4,... 'SparsityProportion',0.15);
Cargue los datos de prueba.
XTest = digitTestCellArrayData;
Los datos de prueba son un arreglo de 1 por 5000 celdas, donde cada celda contiene una matriz de 28 por 28 que representa una imagen sintética de un dígito manuscrito.
Reconstruya los datos de imagen de prueba con el codificador automático entrenado, autoenc.
xReconstructed = predict(autoenc,XTest);
Visualice los datos de prueba reales.
figure; for i = 1:20 subplot(4,5,i); imshow(XTest{i}); end

Visualice los datos de prueba reconstruidos.
figure; for i = 1:20 subplot(4,5,i); imshow(xReconstructed{i}); end
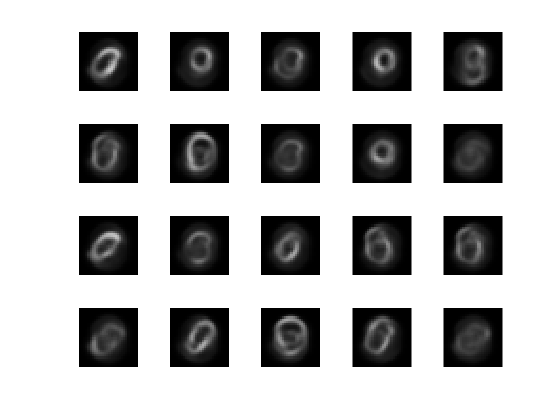
Argumentos de entrada
Argumentos de par nombre-valor
Argumentos de salida
Más acerca de
Referencias
[1] Moller, M. F. “A Scaled Conjugate Gradient Algorithm for Fast Supervised Learning”, Neural Networks, Vol. 6, 1993, pp. 525–533.
[2] Olshausen, B. A. and D. J. Field. “Sparse Coding with an Overcomplete Basis Set: A Strategy Employed by V1.” Vision Research, Vol.37, 1997, pp.3311–3325.
Historial de versiones
Introducido en R2015b