Esta página es para la versión anterior. La página correspondiente en inglés ha sido eliminada en la versión actual.
Diseñar redes neuronales recurrentes de capas
La siguiente red dinámica que se presenta es la red recurrente de capas (LRN). Elman [Elma90] introdujo una versión anterior simplificada de esta red. En la LRN hay un bucle de retroalimentación, con un único retardo, alrededor de cada capa de la red excepto en la última. La red original de Elman solo tenía dos capas y usaba una función de transferencia tansig para la capa oculta y una función de transferencia purelin para la capa de salida. La red original de Elman se entrenó utilizando una aproximación al algoritmo de retropropagación. El comando layrecnet generaliza la red de Elman para que tenga un número aleatorio de capas y funciones de transferencia arbitrarias en cada capa. La toolbox entrena la LRN mediante versiones exactas de los algoritmos basados en gradientes analizados en Redes neuronales superficiales multicapa y entrenamiento de retropropagación. La siguiente imagen ilustra una LRN de dos capas.
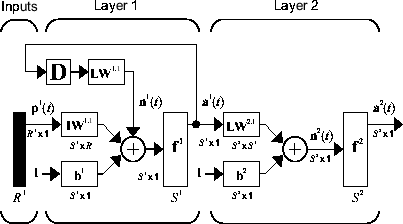
La configuración de la LRN se usa en muchas aplicaciones de filtrado y modelado que ya se han analizado previamente. Para mostrar cómo opera, este ejemplo utiliza el conjunto de datos de pH. Aquí se muestra el código para cargar los datos y crear y entrenar la red:
[p,t] = ph_dataset;
lrn_net = layrecnet(1,8);
lrn_net.trainFcn = 'trainbr';
lrn_net.trainParam.show = 5;
lrn_net.trainParam.epochs = 50;
lrn_net = train(lrn_net,p,t);
Tras el entrenamiento, puede representar la respuesta utilizando el siguiente código:
y = lrn_net(p); plot(cell2mat(y)) hold on plot(cell2mat(t)) legend(["Predicted" "Target"]) hold off
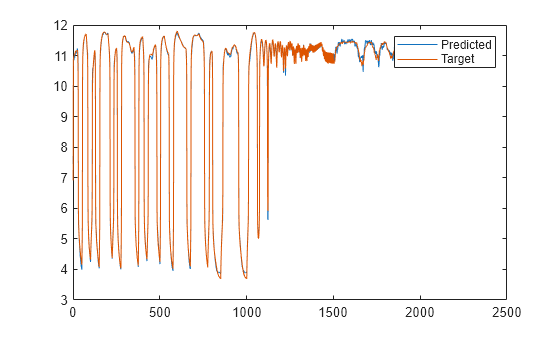
La gráfica muestra que la red ha podido detectar el pH de una solución.
Cada vez que se entrena una red neuronal, puede dar como resultado una solución diferente debido a diferentes valores iniciales de pesos y sesgos, así como a diferentes divisiones de los datos en conjuntos de entrenamiento, validación y prueba. Como resultado, diferentes redes neuronales entrenadas para el mismo problema pueden dar diferentes salidas para la misma entrada. Para asegurarse de que se ha encontrado una red neuronal con una buena precisión, vuelva a entrenarla varias veces.
Existen varias técnicas para mejorar las soluciones iniciales si se desea una mayor precisión. Para obtener más información, consulte .