knnsearch
Encontrar los k vecinos más cercanos utilizando datos de entrada
Descripción
Idx = knnsearch(X,Y,Name,Value)Idx con más opciones especificadas con uno o más argumentos de par nombre-valor. Por ejemplo, puede especificar el número de vecinos más cercanos que desea buscar y la métrica de distancia utilizada en la búsqueda.
Ejemplos
Encuentre los pacientes del conjunto de datos hospital que más se parezcan a los pacientes de Y, en lo que respecta a la edad y el peso.
Cargue el conjunto de datos hospital.
load hospital; X = [hospital.Age hospital.Weight]; Y = [20 162; 30 169; 40 168; 50 170; 60 171]; % New patients
Realice una knnsearch entre X e Y para encontrar los índices de los vecinos más cercanos.
Idx = knnsearch(X,Y);
Encuentre los pacientes de X más próximos en edad y peso a los de Y.
X(Idx,:)
ans = 5×2
25 171
25 171
39 164
49 170
50 172
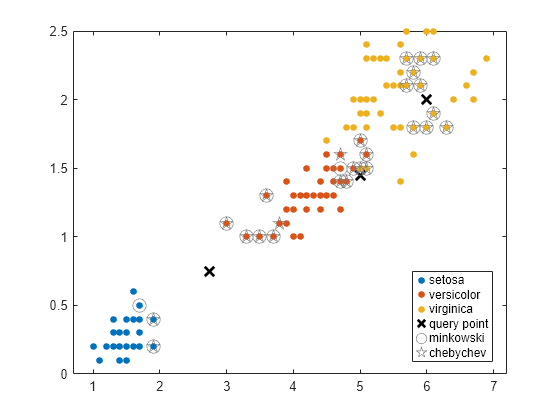
Encuentre los 10 vecinos más cercanos de X a cada punto de Y, primero utilizando la métrica de distancia de Minkowski y después utilizando la métrica de distancia de Chebychev.
Cargue el conjunto de datos Iris de Fisher.
load fisheriris X = meas(:,3:4); % Measurements of original flowers Y = [5 1.45;6 2;2.75 .75]; % New flower data
Realice una knnsearch entre X y los puntos de consulta de Y utilizando las métricas de distancia de Minkowski y Chebychev.
[mIdx,mD] = knnsearch(X,Y,'K',10,'Distance','minkowski','P',5); [cIdx,cD] = knnsearch(X,Y,'K',10,'Distance','chebychev');
Visualice los resultados de las dos búsquedas del vecino más cercano. Represente los datos de entrenamiento. Represente los puntos de consulta con el marcador X. Utilice círculos para denotar los vecinos más cercanos de Minkowski. Utilice pentagramas para denotar los vecinos más cercanos de Chebychev.
gscatter(X(:,1),X(:,2),species) line(Y(:,1),Y(:,2),'Marker','x','Color','k',... 'Markersize',10,'Linewidth',2,'Linestyle','none') line(X(mIdx,1),X(mIdx,2),'Color',[.5 .5 .5],'Marker','o',... 'Linestyle','none','Markersize',10) line(X(cIdx,1),X(cIdx,2),'Color',[.5 .5 .5],'Marker','p',... 'Linestyle','none','Markersize',10) legend('setosa','versicolor','virginica','query point',... 'minkowski','chebychev','Location','best')
Cree dos matrices grandes de puntos y, luego, mida el tiempo utilizado por knnsearch con la métrica de distancia predeterminada "euclidean".
rng default % For reproducibility N = 10000; X = randn(N,1000); Y = randn(N,1000); Idx = knnsearch(X,Y); % Warm up function for more reliable timing information tic Idx = knnsearch(X,Y); standard = toc
standard = 25.3805
A continuación, mida el tiempo utilizado por knnsearch con la métrica de distancia "fasteuclidean". Especifique un tamaño de caché de 100.
Idx2 = knnsearch(X,Y,Distance="fasteuclidean",CacheSize=100); % Warm up function tic Idx2 = knnsearch(X,Y,Distance="fasteuclidean",CacheSize=100); accelerated = toc
accelerated = 2.4388
Evalúe por qué factor es más rápido el cálculo acelerado en comparación con el estándar.
standard/accelerated
ans = 10.4071
La versión acelerada es más de tres veces más rápida en este ejemplo.
Argumentos de entrada
Argumentos de par nombre-valor
Argumentos de salida
Sugerencias
Para un entero positivo fijo k,
knnsearchencuentra los k puntos deXque más se aproximan a cada punto deY. Para encontrar todos los puntos deXdentro de una distancia fija de cada punto deY, utilicerangesearch.knnsearchno guarda un objeto de búsqueda. Para crear un objeto de búsqueda, utilicecreatens.
Algoritmos
Funcionalidad alternativa
Si establece el argumento de par nombre-valor 'NSMethod' de la función knnsearch en el valor adecuado ('exhaustive' para un algoritmo de búsqueda exhaustiva o 'kdtree' para un algoritmo del árbol Kd), los resultados de la búsqueda son equivalentes a los resultados obtenidos realizando una búsqueda de distancia utilizando la función del objeto knnsearch. A diferencia de la función knnsearch, la función del objeto knnsearch requiere un objeto ExhaustiveSearcher o un objeto de modelo KDTreeSearcher.
Bloque de Simulink
Para integrar una búsqueda de los k vecinos más cercanos en Simulink®, puede utilizar el bloque KNN Search de la biblioteca Statistics and Machine Learning Toolbox™ o un bloque Function de MATLAB con la función knnsearch. Para ver un ejemplo, consulte Predict Class Labels Using MATLAB Function Block.
A la hora de decidir qué enfoque utilizar, considere lo siguiente:
Si utiliza el bloque de biblioteca Statistics and Machine Learning Toolbox, puede utilizar Fixed-Point Tool (Fixed-Point Designer) para convertir un modelo de punto flotante en uno de punto fijo.
La compatibilidad con los arreglos de tamaño variable debe activarse para un bloque MATLAB Function con la función
knnsearch.
Referencias
[1] Friedman, J. H., J. Bentley, and R. A. Finkel. “An Algorithm for Finding Best Matches in Logarithmic Expected Time.” ACM Transactions on Mathematical Software 3, no. 3 (1977): 209–226.
Capacidades ampliadas
Historial de versiones
Introducido en R2010aConsulte también
createns | knnsearch | ExhaustiveSearcher | KDTreeSearcher | hnswSearcher | rangesearch