Esta página es para la versión anterior. La página correspondiente en inglés ha sido eliminada en la versión actual.
Segmentación semántica mediante deep learning
En este ejemplo se muestra cómo segmentar una imagen mediante una red de segmentación semántica.
Una red de segmentación semántica clasifica cada píxel de una imagen, lo que resulta en una imagen segmentada por clase. Las aplicaciones para la segmentación semántica incluyen la segmentación de carreteras para conducción autónoma y la segmentación de células cancerígenas para diagnóstico médico. Para obtener más información, consulte Get Started with Semantic Segmentation Using Deep Learning (Computer Vision Toolbox).
En este ejemplo se muestra primero cómo segmentar una imagen con una red Deeplab v3+ [1] preentrenada, que es un tipo de red neuronal convolucional (CNN) diseñada para la segmentación semántica de imágenes. Otro tipo de red para la segmentación semántica es U-Net. Luego, puede descargar, opcionalmente, un conjunto de datos para entrenar la red Deeplab v3 usando transferencia del aprendizaje. El procedimiento de entrenamiento mostrado aquí puede aplicarse a otros tipos de redes de segmentación semántica.
Para ilustrar el procedimiento de entrenamiento, este ejemplo usa el conjunto de datos CamVid [2] de la Universidad de Cambridge. Este conjunto de datos es una colección de imágenes que contiene vistas a nivel de calle obtenidas durante la conducción. El conjunto de datos proporciona etiquetas a nivel de píxeles para 32 clases semánticas, incluyendo coche, peatón y carretera.
Se recomienda una GPU NVIDIA™ compatible con CUDA para ejecutar este ejemplo. Utilizar una GPU requiere Parallel Computing Toolbox™. Para obtener información sobre las prestaciones de cálculo compatibles, consulte GPU Computing Requirements (Parallel Computing Toolbox).
Descargar una red de segmentación semántica preentrenada
Descargue una versión preentrenada de DeepLab v3+ entrenada con el conjunto de datos CamVid.
pretrainedURL = "https://ssd.mathworks.com/supportfiles/vision/data/deeplabv3plusResnet18CamVid_v2.zip"; pretrainedFolder = fullfile(tempdir,"pretrainedNetwork"); pretrainedNetworkZip = fullfile(pretrainedFolder,"deeplabv3plusResnet18CamVid_v2.zip"); if ~exist(pretrainedNetworkZip,'file') mkdir(pretrainedFolder); disp("Downloading pretrained network (58 MB)..."); websave(pretrainedNetworkZip,pretrainedURL); end
Downloading pretrained network (58 MB)...
unzip(pretrainedNetworkZip, pretrainedFolder)
Cargue la red preentrenada.
pretrainedNetwork = fullfile(pretrainedFolder,"deeplabv3plusResnet18CamVid_v2.mat");
data = load(pretrainedNetwork);
net = data.net;Establezca las clases para cuya clasificación se ha entrenado la red.
classes = getClassNames()
classes = 11×1 string
"Sky"
"Building"
"Pole"
"Road"
"Pavement"
"Tree"
"SignSymbol"
"Fence"
"Car"
"Pedestrian"
"Bicyclist"
Realizar segmentación semántica de imágenes
Lea una imagen que contenga clases para cuya clasificación está entrenada la red.
I = imread("parkinglot_left.png");Cambie el tamaño de la imagen para que coincida con el tamaño de entrada de la red.
inputSize = net.Layers(1).InputSize; I = imresize(I,inputSize(1:2));
Realice la segmentación semántica con la función semanticseg y la red preentrenada.
C = semanticseg(I,net);
Superponga los resultados de segmentación encima de la imagen con labeloverlay. Establezca el mapa de colores de superposición en los valores de mapa de colores definidos por el conjunto de datos CamVid [2].
cmap = camvidColorMap; B = labeloverlay(I,C,Colormap=cmap,Transparency=0.4); figure imshow(B) pixelLabelColorbar(cmap, classes);

Aunque la red está preentrenada con imágenes de conducción por ciudad, genera un resultado razonable en una escena de un aparcamiento. Para mejorar los resultados de segmentación, la red debería volverse a entrenar con imágenes adicionales que contengan escenas de aparcamientos. El resto de este ejemplo muestra cómo entrenar una red de segmentación semántica con transferencia del aprendizaje.
Entrenar una red de segmentación semántica
En este ejemplo se entrena una red Deeplab v3+ con pesos inicializada desde una red Resnet-18 preentrenada. ResNet-18 es una red eficiente adecuada para aplicaciones con recursos de procesamiento limitados. También se pueden usar otras redes preentrenadas, como MobileNet v2 o ResNet-50, en función de los requisitos de la aplicación. Para obtener más detalles, consulte Redes neuronales profundas preentrenadas.
Obtenga una red ResNet-18 preentrenada usando la función imagePretrainedNetwork. ResNet-18 requiere el paquete de soporte Deep Learning Toolbox™ Model for ResNet-18 Network. Si no ha instalado el paquete de soporte, la función proporciona un enlace de descarga.
imagePretrainedNetwork("resnet18")ans =
dlnetwork with properties:
Layers: [70×1 nnet.cnn.layer.Layer]
Connections: [77×2 table]
Learnables: [82×3 table]
State: [40×3 table]
InputNames: {'data'}
OutputNames: {'prob'}
Initialized: 1
View summary with summary.
Descargar el conjunto de datos CamVid
Descargue el conjunto de datos CamVid de las siguientes URL.
imageURL = "http://web4.cs.ucl.ac.uk/staff/g.brostow/MotionSegRecData/files/701_StillsRaw_full.zip"; labelURL = "http://web4.cs.ucl.ac.uk/staff/g.brostow/MotionSegRecData/data/LabeledApproved_full.zip"; outputFolder = fullfile(tempdir,"CamVid"); labelsZip = fullfile(outputFolder,"labels.zip"); imagesZip = fullfile(outputFolder,"images.zip"); if ~exist(labelsZip, 'file') || ~exist(imagesZip,'file') mkdir(outputFolder) disp("Downloading 16 MB CamVid dataset labels..."); websave(labelsZip, labelURL); unzip(labelsZip, fullfile(outputFolder,"labels")); disp("Downloading 557 MB CamVid dataset images..."); websave(imagesZip, imageURL); unzip(imagesZip, fullfile(outputFolder,"images")); end
Downloading 16 MB CamVid dataset labels...
Downloading 557 MB CamVid dataset images...
Nota: el tiempo de descarga de los datos depende de la conexión a Internet. Los comandos utilizados más arriba bloquean MATLAB hasta que la descarga se complete. Alternativamente, puede usar el navegador web para descargar primero el conjunto de datos en el disco local. Para utilizar el archivo descargado de la web, cambie la variable outputFolder más arriba a la ubicación del archivo descargado.
Cargar imágenes CamVid
Utilice imageDatastore para cargar imágenes CamVid. imageDatastore permite cargar de forma eficiente una gran colección de imágenes en disco.
imgDir = fullfile(outputFolder,"images","701_StillsRaw_full"); imds = imageDatastore(imgDir);
Muestre una de las imágenes.
I = readimage(imds,559); I = histeq(I); imshow(I)

Cargar imágenes CamVid con etiquetas de píxeles
Utilice pixelLabelDatastore (Computer Vision Toolbox) para cargar datos de imágenes CamVid de etiquetas de píxeles. pixelLabelDatastore encapsula los datos de etiquetas de píxeles y el ID de etiqueta en una aplicación de nombre de clase.
Para facilitar el entrenamiento, agrupe las 32 clases originales de CamVid en 11 clases. Para reducir 32 clases a 11, varias clases del conjunto de datos original se agrupan. Por ejemplo, "Car" es una combinación de "Car", "SUVPickupTruck", "Truck_Bus", "Train" y "OtherMoving". Devuelva los ID de etiqueta agrupados usando la función de apoyo camvidPixelLabelIDs, que se enumera al final de este ejemplo.
labelIDs = camvidPixelLabelIDs();
Utilice las clases y los ID de etiqueta para crear pixelLabelDatastore.
labelDir = fullfile(outputFolder,"labels");
pxds = pixelLabelDatastore(labelDir,classes,labelIDs);Lea y muestre una de las imágenes con etiqueta de píxeles superponiéndola encima de una imagen. Las áreas sin superposición de color no tienen etiquetas de píxeles y no se usan durante el entrenamiento.
C = readimage(pxds,559); cmap = camvidColorMap; B = labeloverlay(I,C,ColorMap=cmap); imshow(B) pixelLabelColorbar(cmap,classes);

Analizar estadísticas de conjuntos de datos
Para ver la distribución de las etiquetas de clase en el conjunto de datos CamVid, use countEachLabel (Computer Vision Toolbox). Esta función cuenta el número de píxeles por etiqueta de clase.
tbl = countEachLabel(pxds)
tbl=11×3 table
Name PixelCount ImagePixelCount
______________ __________ _______________
{'Sky' } 7.6801e+07 4.8315e+08
{'Building' } 1.1737e+08 4.8315e+08
{'Pole' } 4.7987e+06 4.8315e+08
{'Road' } 1.4054e+08 4.8453e+08
{'Pavement' } 3.3614e+07 4.7209e+08
{'Tree' } 5.4259e+07 4.479e+08
{'SignSymbol'} 5.2242e+06 4.6863e+08
{'Fence' } 6.9211e+06 2.516e+08
{'Car' } 2.4437e+07 4.8315e+08
{'Pedestrian'} 3.4029e+06 4.4444e+08
{'Bicyclist' } 2.5912e+06 2.6196e+08
Visualice los recuentos de píxeles por clase.
frequency = tbl.PixelCount/sum(tbl.PixelCount);
bar(1:numel(classes),frequency)
xticks(1:numel(classes))
xticklabels(tbl.Name)
xtickangle(45)
ylabel("Frequency")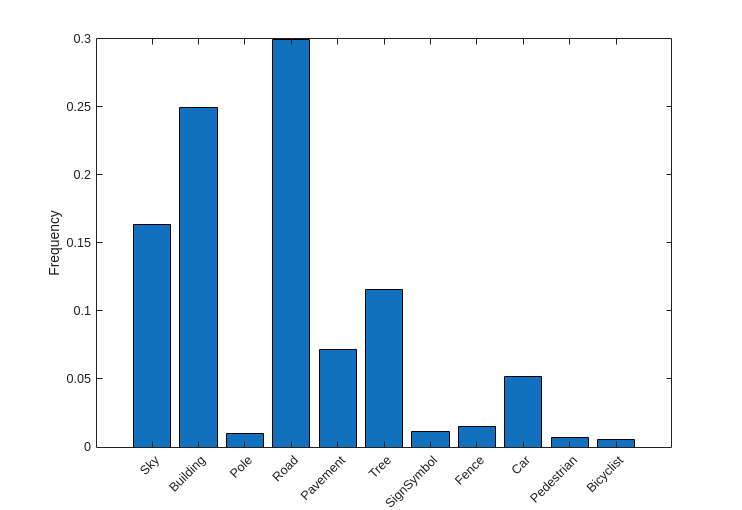
Lo ideal sería que todas las clases tuvieran el mismo número de observaciones. No obstante, las clases de CamVid están desequilibradas, un problema habitual en conjuntos de datos de automoción en escenas callejeras. Estas escenas tienen más píxeles de cielo, edificios y carreteras que de peatones y ciclistas, ya que el cielo, los edificios y las carreteras cubren una mayor parte de la imagen. Si no se gestiona correctamente, este desequilibrio podría perjudicar al proceso de aprendizaje, pues este está sesgado a favor de las clases dominantes. Más adelante en este ejemplo, utilizará la ponderación de clases para resolver este problema.
Preparar conjuntos de entrenamiento, validación y prueba
Deeplab v3+ se entrena usando el 60% de las imágenes del conjunto de datos. El resto de las imágenes se dividen de manera uniforme en 20% y 20% para la validación y para la prueba, respectivamente. El siguiente código divide aleatoriamente los datos de la imagen y las etiquetas de píxeles en conjuntos de entrenamiento, de validación y prueba.
[imdsTrain, imdsVal, imdsTest, pxdsTrain, pxdsVal, pxdsTest] = partitionCamVidData(imds,pxds);
La división 60/20/20 da como resultado el siguiente número de imágenes de entrenamiento, validación y prueba:
numTrainingImages = numel(imdsTrain.Files)
numTrainingImages = 421
numValImages = numel(imdsVal.Files)
numValImages = 140
numTestingImages = numel(imdsTest.Files)
numTestingImages = 140
Defina los datos de validación.
dsVal = combine(imdsVal,pxdsVal);
Aumento de datos
El aumento de datos se utiliza para mejorar la precisión de la red transformando aleatoriamente los datos originales durante el entrenamiento. Utilizando el aumento de datos, puede añadir más variedad a los datos de entrenamiento sin aumentar el número de muestras de entrenamiento etiquetadas. Para aplicar la misma transformación aleatoria tanto a los datos de la imagen como a los de las etiquetas de píxeles, use el almacén de datos combine y transform. Primero, combine imdsTrain y pxdsTrain.
dsTrain = combine(imdsTrain,pxdsTrain);
Luego, use el almacén de datos transform para aplicar el aumento de datos deseado definido en la función de apoyo augmentImageAndLabel. En este caso, se utiliza la reflexión izquierda/derecha aleatoria y la traslación X/Y aleatoria de +/- 10 píxeles para el aumento de datos.
xTrans = [-10 10]; yTrans = [-10 10]; dsTrain = transform(dsTrain, @(data)augmentImageAndLabel(data,xTrans,yTrans));
Tenga en cuenta que el aumento de datos no se aplica a los datos de prueba y validación. Idealmente, los datos de prueba y validación deben ser representativos de los datos originales y se dejan sin modificar para una evaluación sin sesgo.
Crear la red
Especifique el tamaño de imagen de la red. Suele ser el mismo que el tamaño de las imágenes de entrenamiento.
imageSize = [720 960 3];
Especifique el número de clases.
numClasses = numel(classes);
Use la función deeplabv3plus para crear una red DeepLab v3+ basada en ResNet-18. Elegir la mejor red para la aplicación requiere un análisis empírico y es otro nivel del ajuste de hiperparámetros. Por ejemplo, puede experimentar con distintas redes base como ResNet-50 o MobileNet v2, o puede probar otra arquitectura de red de segmentación semántica, como U-Net.
network = deeplabv3plus(imageSize,numClasses,"resnet18");Equilibrar las clases utilizando la ponderación de clases
Como se ha mostrado anteriormente, las clases de CamVid no están equilibradas. Para mejorar el entrenamiento, puede utilizar la ponderación de clases para equilibrar las clases. Utilice los recuentos de etiquetas de píxeles calculados anteriormente con la función countEachLabel (Computer Vision Toolbox) y calcule la mediana de los pesos de clase de frecuencia.
imageFreq = tbl.PixelCount ./ tbl.ImagePixelCount; classWeights = median(imageFreq) ./ imageFreq;
Seleccionar las opciones de entrenamiento
El algoritmo de optimización utilizado para el entrenamiento es un gradiente descendente estocástico con momento (SGDM). Utilice trainingOptions para especificar los hiperparámetros utilizados para SGDM.
La tasa de aprendizaje utiliza una programación por partes. La tasa de aprendizaje se reduce por un factor de 0.1 cada 6 épocas. Esto permite que la red aprenda rápidamente con una mayor tasa de aprendizaje inicial, a la vez que puede encontrar una solución cercana al valor óptimo local cuando la tasa de aprendizaje descienda.
La red se prueba en comparación con los datos de validación cada época estableciendo el argumento nombre-valor ValidationData. ValidationPatience está establecido en 4 para detener el entrenamiento antes de tiempo cuando la precisión de validación converge. Esto evita que la red se sobreajuste al conjunto de datos de entrenamiento.
Se utiliza un tamaño de minilote de 4 para reducir el uso de memoria durante el entrenamiento. Puede aumentar o disminuir este valor en función de la cantidad de memoria GPU disponible en el sistema.
Además, CheckpointPath está establecido en una ubicación temporal. Este argumento nombre-valor permite guardar puntos de control de la red al final de cada época de entrenamiento. Si el entrenamiento se ve interrumpido por un fallo del sistema o un corte de suministro eléctrico, podrá retomarlo a partir del punto de control guardado. Asegúrese de que la ubicación especificada por CheckpointPath tenga suficiente espacio para almacenar los puntos de control de la red. Por ejemplo, guardar 100 puntos de control de Deeplab v3+ requiere aproximadamente 6 GB de espacio en disco, ya que cada punto de control ocupa 61 MB.
options = trainingOptions("sgdm",... LearnRateSchedule="piecewise",... LearnRateDropPeriod=6,... LearnRateDropFactor=0.1,... Momentum=0.9,... InitialLearnRate=1e-2,... L2Regularization=0.005,... ValidationData=dsVal,... MaxEpochs=18,... MiniBatchSize=4,... Shuffle="every-epoch",... CheckpointPath=tempdir,... VerboseFrequency=10,... ValidationPatience=4);
Comenzar el entrenamiento
Para entrenar la red, establezca la variable doTraining del siguiente código en true. Entrene la red neuronal con la función trainnet. Utilice una función de pérdida personalizada, especificada por la función de ayuda modelLoss. De forma predeterminada, la función trainnet usa una GPU en caso de que esté disponible. Para entrenar en una GPU se requiere una licencia de Parallel Computing Toolbox™ y un dispositivo GPU compatible. Para obtener información sobre los dispositivos compatibles, consulte GPU Computing Requirements (Parallel Computing Toolbox). De lo contrario, la función trainnet usa la CPU. Para especificar el entorno de ejecución, utilice la opción de entrenamiento ExecutionEnvironment.
Nota: El entrenamiento se ha verificado en una NVIDIA™ GeForce RTX 3090 Ti con 24 GB de memoria. Si su GPU tiene menos memoria, es posible que esta se agote durante el entrenamiento. Si esto ocurre, pruebe a establecer MiniBatchSize en 1 en trainingOptions o a reducir el tamaño de entrada de la red y cambiar el tamaño de los datos de entrenamiento. Se tarda unos 50 minutos en entrenar esta red. En función del hardware de la GPU, puede tardar algo más.
doTraining = false; if doTraining [net,info] = trainnet(dsTrain,network,@(Y,T) modelLoss(Y,T,classWeights),options); end
Probar la red con una imagen
Ejecute la red entrenada en una imagen de prueba.
I = readimage(imdsTest,35); C = semanticseg(I,net,Classes=classes);
Muestre los resultados.
B = labeloverlay(I,C,Colormap=cmap,Transparency=0.4); imshow(B) pixelLabelColorbar(cmap, classes);

Compare los resultados de C con la validación esperada almacenada en pxdsTest. Las regiones verde y magenta resaltan áreas donde los resultados de segmentación difieren de la validación esperada.
expectedResult = readimage(pxdsTest,35); actual = uint8(C); expected = uint8(expectedResult); imshowpair(actual, expected)

Visualmente, los resultados de la segmentación semántica se solapan bien para clases como carretera, cielo, árbol y edificio. No obstante, los objetos más pequeños, como peatones y coches, no son tan precisos. La cantidad de solapamiento por clase puede medirse con la métrica de intersección sobre la unión (IoU), también conocida como índice de Jaccard. Utilice la función jaccard (Image Processing Toolbox) para medir la IoU.
iou = jaccard(C,expectedResult); table(classes,iou)
ans=11×2 table
classes iou
____________ _______
"Sky" 0.93632
"Building" 0.87722
"Pole" 0.40461
"Road" 0.95334
"Pavement" 0.85586
"Tree" 0.92632
"SignSymbol" 0.6295
"Fence" 0.82388
"Car" 0.75391
"Pedestrian" 0.26717
"Bicyclist" 0.70585
La métrica IoU confirma los resultados visuales. Las clases carretera, cielo, árbol y edificio tienen puntuaciones IoU altas, mientras que clases como peatón y coche tienen puntuaciones bajas. Otras métricas de segmentación comunes incluyen dice (Image Processing Toolbox) y la puntuación de coincidencia de contorno bfscore (Image Processing Toolbox).
Evaluar la red entrenada
Para medir la precisión de varias imágenes de prueba, ejecute semanticseg (Computer Vision Toolbox) en todo el conjunto de prueba. Se utiliza un tamaño de minilote de 4 para reducir el uso de memoria durante la segmentación de imágenes. Puede aumentar o disminuir este valor en función de la cantidad de memoria GPU disponible en el sistema.
pxdsResults = semanticseg(imdsTest,net, ... Classes=classes, ... MiniBatchSize=4, ... WriteLocation=tempdir, ... Verbose=false);
semanticseg devuelve los resultados para el conjunto de prueba como un objeto pixelLabelDatastore. Los datos reales de etiquetas de píxeles para cada imagen de prueba de imdsTest se escriben en el disco en la ubicación especificada por el argumento nombre-valor WriteLocation. Use evaluateSemanticSegmentation (Computer Vision Toolbox) para medir las métricas de segmentación semántica en los resultados del conjunto de prueba.
metrics = evaluateSemanticSegmentation(pxdsResults,pxdsTest,Verbose=false);
evaluateSemanticSegmentation devuelve varias métricas para el conjunto de datos completo, para casos individuales y para cada imagen de prueba. Para ver las métricas de nivel de conjunto de datos, inspeccione metrics.DataSetMetrics. Las métricas del conjunto de datos proporcionan una visión general de alto nivel del rendimiento de la red.
metrics.DataSetMetrics
ans=1×5 table
GlobalAccuracy MeanAccuracy MeanIoU WeightedIoU MeanBFScore
______________ ____________ _______ ___________ ___________
0.90749 0.88828 0.69574 0.84905 0.74305
Para ver el impacto de cada clase en el rendimiento general, inspeccione las métricas por clase con metrics.ClassMetrics.
Aunque el rendimiento general del conjunto de datos es bastante elevado, las métricas de clase muestran que las clases infrarrepresentadas, como Pedestrian, Bicyclist y Car, no están tan bien segmentadas como las clases Road, Sky, Tree y Building. Los datos adicionales que incluyan más muestras de las clases infrarrepresentadas pueden contribuir a mejorar los resultados.
metrics.ClassMetrics
ans=11×3 table
Accuracy IoU MeanBFScore
________ _______ ___________
Sky 0.9438 0.91456 0.91326
Building 0.84486 0.82404 0.69504
Pole 0.8251 0.29467 0.65176
Road 0.94803 0.93848 0.8438
Pavement 0.92135 0.7764 0.80394
Tree 0.89107 0.79122 0.76428
SignSymbol 0.81773 0.49377 0.59537
Fence 0.81991 0.62131 0.63431
Car 0.93653 0.81632 0.77842
Pedestrian 0.91097 0.50499 0.69312
Bicyclist 0.9117 0.67739 0.72121
Funciones de apoyo
function labelIDs = camvidPixelLabelIDs() % Return the label IDs corresponding to each class. % % The CamVid dataset has 32 classes. Group them into 11 classes following % the original SegNet training methodology [1]. % % The 11 classes are: % "Sky" "Building", "Pole", "Road", "Pavement", "Tree", "SignSymbol", % "Fence", "Car", "Pedestrian", and "Bicyclist". % % CamVid pixel label IDs are provided as RGB color values. Group them into % 11 classes and return them as a cell array of M-by-3 matrices. The % original CamVid class names are listed alongside each RGB value. Note % that the Other/Void class are excluded below. labelIDs = { ... % "Sky" [ 128 128 128; ... % "Sky" ] % "Building" [ 000 128 064; ... % "Bridge" 128 000 000; ... % "Building" 064 192 000; ... % "Wall" 064 000 064; ... % "Tunnel" 192 000 128; ... % "Archway" ] % "Pole" [ 192 192 128; ... % "Column_Pole" 000 000 064; ... % "TrafficCone" ] % Road [ 128 064 128; ... % "Road" 128 000 192; ... % "LaneMkgsDriv" 192 000 064; ... % "LaneMkgsNonDriv" ] % "Pavement" [ 000 000 192; ... % "Sidewalk" 064 192 128; ... % "ParkingBlock" 128 128 192; ... % "RoadShoulder" ] % "Tree" [ 128 128 000; ... % "Tree" 192 192 000; ... % "VegetationMisc" ] % "SignSymbol" [ 192 128 128; ... % "SignSymbol" 128 128 064; ... % "Misc_Text" 000 064 064; ... % "TrafficLight" ] % "Fence" [ 064 064 128; ... % "Fence" ] % "Car" [ 064 000 128; ... % "Car" 064 128 192; ... % "SUVPickupTruck" 192 128 192; ... % "Truck_Bus" 192 064 128; ... % "Train" 128 064 064; ... % "OtherMoving" ] % "Pedestrian" [ 064 064 000; ... % "Pedestrian" 192 128 064; ... % "Child" 064 000 192; ... % "CartLuggagePram" 064 128 064; ... % "Animal" ] % "Bicyclist" [ 000 128 192; ... % "Bicyclist" 192 000 192; ... % "MotorcycleScooter" ] }; end
function classes = getClassNames() classes = [ "Sky" "Building" "Pole" "Road" "Pavement" "Tree" "SignSymbol" "Fence" "Car" "Pedestrian" "Bicyclist" ]; end
function pixelLabelColorbar(cmap, classNames) % Add a colorbar to the current axis. The colorbar is formatted % to display the class names with the color. colormap(gca,cmap) % Add colorbar to current figure. c = colorbar(gca); % Use class names for tick marks. c.TickLabels = classNames; numClasses = size(cmap,1); % Center tick labels. c.Ticks = 1/(numClasses*2):1/numClasses:1; % Remove tick mark. c.TickLength = 0; end
function cmap = camvidColorMap() % Define the colormap used by CamVid dataset. cmap = [ 128 128 128 % Sky 128 0 0 % Building 192 192 192 % Pole 128 64 128 % Road 60 40 222 % Pavement 128 128 0 % Tree 192 128 128 % SignSymbol 64 64 128 % Fence 64 0 128 % Car 64 64 0 % Pedestrian 0 128 192 % Bicyclist ]; % Normalize between [0 1]. cmap = cmap ./ 255; end
function [imdsTrain, imdsVal, imdsTest, pxdsTrain, pxdsVal, pxdsTest] = partitionCamVidData(imds,pxds) % Partition CamVid data by randomly selecting 60% of the data for training. The % rest is used for testing. % Set initial random state for example reproducibility. rng(0); numFiles = numpartitions(imds); shuffledIndices = randperm(numFiles); % Use 60% of the images for training. numTrain = round(0.60 * numFiles); trainingIdx = shuffledIndices(1:numTrain); % Use 20% of the images for validation numVal = round(0.20 * numFiles); valIdx = shuffledIndices(numTrain+1:numTrain+numVal); % Use the rest for testing. testIdx = shuffledIndices(numTrain+numVal+1:end); % Create image datastores for training and test. imdsTrain = subset(imds,trainingIdx); imdsVal = subset(imds,valIdx); imdsTest = subset(imds,testIdx); % Create pixel label datastores for training and test. pxdsTrain = subset(pxds,trainingIdx); pxdsVal = subset(pxds,valIdx); pxdsTest = subset(pxds,testIdx); end
function data = augmentImageAndLabel(data, xTrans, yTrans) % Augment images and pixel label images using random reflection and % translation. for i = 1:size(data,1) tform = randomAffine2d(... XReflection=true,... XTranslation=xTrans, ... YTranslation=yTrans); % Center the view at the center of image in the output space while % allowing translation to move the output image out of view. rout = affineOutputView(size(data{i,1}), tform, BoundsStyle='centerOutput'); % Warp the image and pixel labels using the same transform. data{i,1} = imwarp(data{i,1}, tform, OutputView=rout); data{i,2} = imwarp(data{i,2}, tform, OutputView=rout); end end
function loss = modelLoss(Y,T,classWeights) weights = dlarray(classWeights,"C"); mask = ~isnan(T); T(isnan(T)) = 0; loss = crossentropy(Y,T,weights,Mask=mask,NormalizationFactor="mask-included"); end
Referencias
[1] Chen, Liang-Chieh et al. "Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation". ECCV (2018).
[2] Brostow, G. J., J. Fauqueur y R. Cipolla. "Semantic object classes in video: A high-definition ground truth database". Pattern Recognition Letters. Vol. 30, n.º 2, 2009, págs. 88-97.
Consulte también
pixelLabelDatastore (Computer Vision Toolbox) | semanticseg (Computer Vision Toolbox) | labeloverlay (Image Processing Toolbox) | countEachLabel (Computer Vision Toolbox) | trainnet | trainingOptions | dlnetwork | imageDataAugmenter | evaluateSemanticSegmentation (Computer Vision Toolbox)
Temas
- Semantic Segmentation of Multispectral Images Using Deep Learning (Computer Vision Toolbox)
- Semantic Segmentation Using Dilated Convolutions
- Get Started with Semantic Segmentation Using Deep Learning (Computer Vision Toolbox)
- Label Pixels for Semantic Segmentation (Computer Vision Toolbox)
- Redes neuronales profundas preentrenadas