trainingOptions
Opciones para entrenar una red neuronal de deep learning
Descripción
options = trainingOptions(solverName)solverName. Para entrenar una red neuronal, use las opciones de entrenamiento como un argumento de entrada para la función trainnet.
options = trainingOptions(solverName,Name=Value)
Ejemplos
Cree un conjunto de opciones para entrenar una red mediante gradiente descendente estocástico con momento. Reduzca la tasa de aprendizaje por un factor de 0.2 cada 5 épocas. Establezca el número máximo de épocas para entrenamiento en 20 y use un minilote con 64 observaciones en cada iteración. Active la gráfica de progreso del entrenamiento.
options = trainingOptions("sgdm", ... LearnRateSchedule="piecewise", ... LearnRateDropFactor=0.2, ... LearnRateDropPeriod=5, ... MaxEpochs=20, ... MiniBatchSize=64, ... Plots="training-progress")
options =
TrainingOptionsSGDM with properties:
Momentum: 0.9000
MaxEpochs: 20
InitialLearnRate: 0.0100
LearnRateSchedule: 'piecewise'
LearnRateDropFactor: 0.2000
LearnRateDropPeriod: 5
MiniBatchSize: 64
Shuffle: 'once'
CheckpointFrequencyUnit: 'epoch'
PreprocessingEnvironment: 'serial'
Verbose: 1
VerboseFrequency: 50
ValidationData: []
ValidationFrequency: 50
ValidationPatience: Inf
Metrics: []
ObjectiveMetricName: 'loss'
ExecutionEnvironment: 'auto'
Plots: 'training-progress'
OutputFcn: []
SequenceLength: 'longest'
SequencePaddingValue: 0
SequencePaddingDirection: 'right'
InputDataFormats: "auto"
TargetDataFormats: "auto"
ResetInputNormalization: 1
BatchNormalizationStatistics: 'auto'
OutputNetwork: 'auto'
Acceleration: "auto"
CheckpointPath: ''
CheckpointFrequency: 1
CategoricalInputEncoding: 'integer'
CategoricalTargetEncoding: 'auto'
L2Regularization: 1.0000e-04
GradientThresholdMethod: 'l2norm'
GradientThreshold: Inf
Este ejemplo muestra cómo monitorizar el proceso de entrenamiento en redes de deep learning.
Cuando entrena redes para deep learning, puede comprobar cómo progresa el entrenamiento representando varias métricas durante el proceso. Por ejemplo, puede determinar si la precisión de la red está mejorando y con qué rapidez, y si la red está empezando a sobreajustar los datos de entrenamiento.
En este ejemplo se muestra cómo monitorizar el progreso de entrenamiento para redes entrenadas usando la función trainnet. Para redes entrenadas con un bucle de entrenamiento personalizado, utilice un objeto trainingProgressMonitor para representar métricas durante el entrenamiento. Para obtener más información, consulte Monitor Custom Training Loop Progress.
Cuando establece la opción de entrenamiento Plots en "training-progress" para trainingOptions y comienza el entrenamiento de la red, la función trainnet crea una figura y muestra las métricas de entrenamiento en cada iteración. Cada iteración es una estimación del gradiente y una actualización de los parámetros de la red. Si se especifican los datos de validación en trainingOptions, la figura muestra las métricas de validación cada vez que trainnet valida la red. La figura representa la pérdida y cualquier métrica especificada por la opción nombre-valor Metrics. De manera predeterminada, el software utiliza una escala lineal para las gráficas. Para especificar una escala logarítmica para el eje y, seleccione el botón de escala logarítmica en la barra de herramientas de los ejes.

Durante el entrenamiento, puede detenerlo y devolver el estado actual de la red haciendo clic en el botón de stop de la esquina superior derecha. Una vez que haya hecho clic en el botón de stop, el entrenamiento podría tardar un poco antes de completarse. Una vez completado, trainnet devuelve la red entrenada.
Especifique la opción de entrenamiento OutputNetwork como "best-validation" para obtener valores finales que correspondan a la iteración con el mejor valor de métrica de validación, donde las opciones de entrenamiento ObjectiveMetricName especifican la métrica optimizada. Especifique la opción de entrenamiento OutputNetwork como "last-iteration" para obtener métricas finalizadas que correspondan a la última iteración de entrenamiento.
A la derecha del panel, vea la información sobre el tiempo de entrenamiento y los ajustes. Para obtener más información sobre las opciones de entrenamiento, consulte Configurar parámetros y entrenar una red neuronal convolucional.
Para guardar la gráfica del progreso de entrenamiento, haga clic en Export as Image en la ventana del entrenamiento. Puede guardar la gráfica como archivo PNG, JEPG, TIFF o PDF. También puede guardar de forma individual las gráficas con la barra de herramientas de los ejes.

Representar el progreso del entrenamiento durante el mismo
Entrene una red y represente el progreso de entrenamiento durante el mismo.
Cargue los datos de entrenamiento y de prueba de los archivos MAT DigitsDataTrain.mat y DigitsDataTest.mat, respectivamente. Cada conjunto de datos de entrenamiento y de prueba contiene 5000 imágenes.
load DigitsDataTrain.mat load DigitsDataTest.mat
Cree un objeto dlnetwork.
net = dlnetwork;
Especifique las capas de la rama de clasificación y añádalas a la red.
layers = [
imageInputLayer([28 28 1])
convolution2dLayer(3,8,Padding="same")
batchNormalizationLayer
reluLayer
maxPooling2dLayer(2,Stride=2)
convolution2dLayer(3,16,Padding="same")
batchNormalizationLayer
reluLayer
maxPooling2dLayer(2,Stride=2)
convolution2dLayer(3,32,Padding="same")
batchNormalizationLayer
reluLayer
fullyConnectedLayer(10)
softmaxLayer];
net = addLayers(net,layers);Especifique opciones para el entrenamiento de la red. Para validar la red a intervalos regulares durante el entrenamiento, especifique los datos de validación. Registre los valores de las métricas de precisión y puntuación F. Para representar el progreso del entrenamiento durante el mismo, establezca la opción de entrenamiento Plots en "training-progress".
options = trainingOptions("sgdm", ... MaxEpochs=8, ... Metrics = ["accuracy","fscore"], ... ValidationData={XTest,labelsTest}, ... ValidationFrequency=30, ... Verbose=false, ... Plots="training-progress");
Entrene la red.
net = trainnet(XTrain,labelsTrain,net,"crossentropy",options);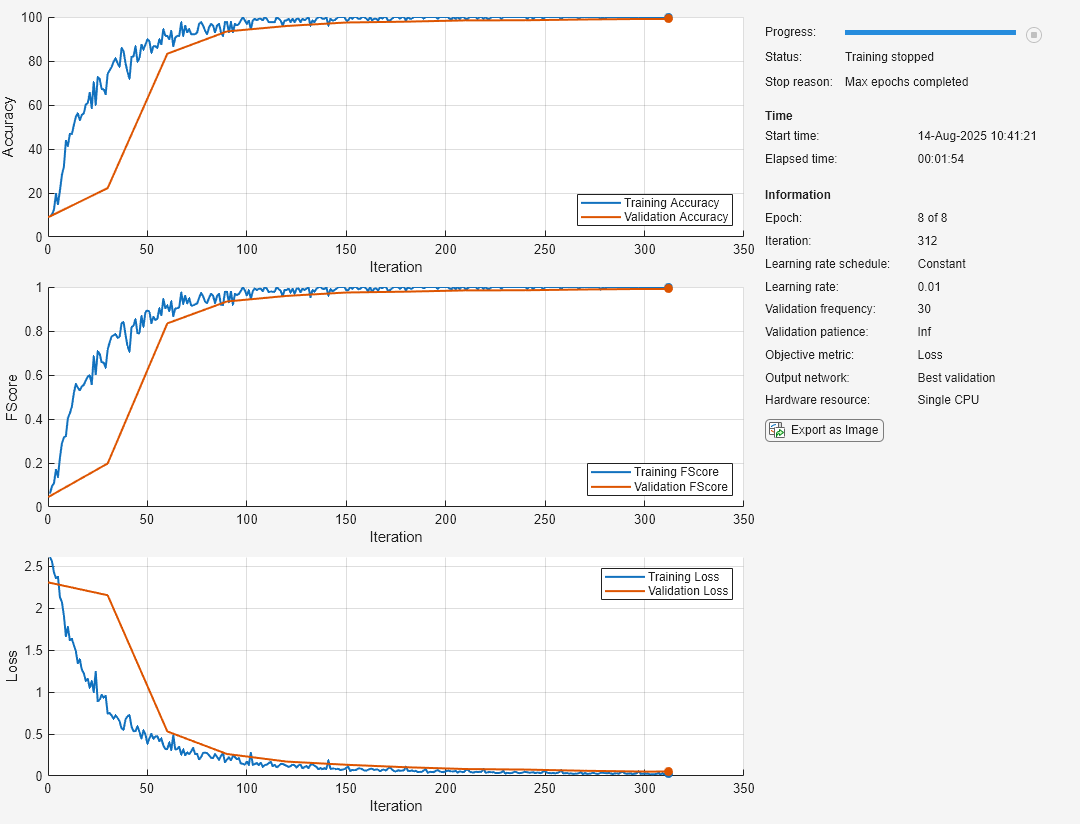
Utilice métricas para detener el entrenamiento antes de tiempo y devolver la mejor red.
Cargue los datos de entrenamiento, que contienen 5000 imágenes de dígitos. Reserve 1000 de las imágenes para la validación de la red.
[XTrain,YTrain] = digitTrain4DArrayData; idx = randperm(size(XTrain,4),1000); XValidation = XTrain(:,:,:,idx); XTrain(:,:,:,idx) = []; YValidation = YTrain(idx); YTrain(idx) = [];
Construya una red para clasificar los datos de las imágenes de los dígitos.
net = dlnetwork;
layers = [
imageInputLayer([28 28 1])
convolution2dLayer(3,8,Padding="same")
batchNormalizationLayer
reluLayer
fullyConnectedLayer(10)
softmaxLayer];
net = addLayers(net,layers);Especifique las opciones de entrenamiento:
Usar un solver SGDM para el entrenamiento.
Monitorizar el rendimiento del entrenamiento especificando los datos de validación y la frecuencia de validación.
Hacer un seguimiento de la precisión y la recuperación durante el entrenamiento. Para devolver la red con el mejor valor de recuperación, especifique
"recall"como métrica objetivo y establezca la red de salida como"best-validation".Especificar la paciencia de validación como 5 para que el entrenamiento se detenga si la recuperación no ha disminuido durante cinco iteraciones.
Visualizar la gráfica de progreso del entrenamiento de la red.
Suprimir la salida detallada.
options = trainingOptions("sgdm", ... ValidationData={XValidation,YValidation}, ... ValidationFrequency=35, ... ValidationPatience=5, ... Metrics=["accuracy","recall"], ... ObjectiveMetricName="recall", ... OutputNetwork="best-validation", ... Plots="training-progress", ... Verbose=false);
Entrene la red.
net = trainnet(XTrain,YTrain,net,"crossentropy",options);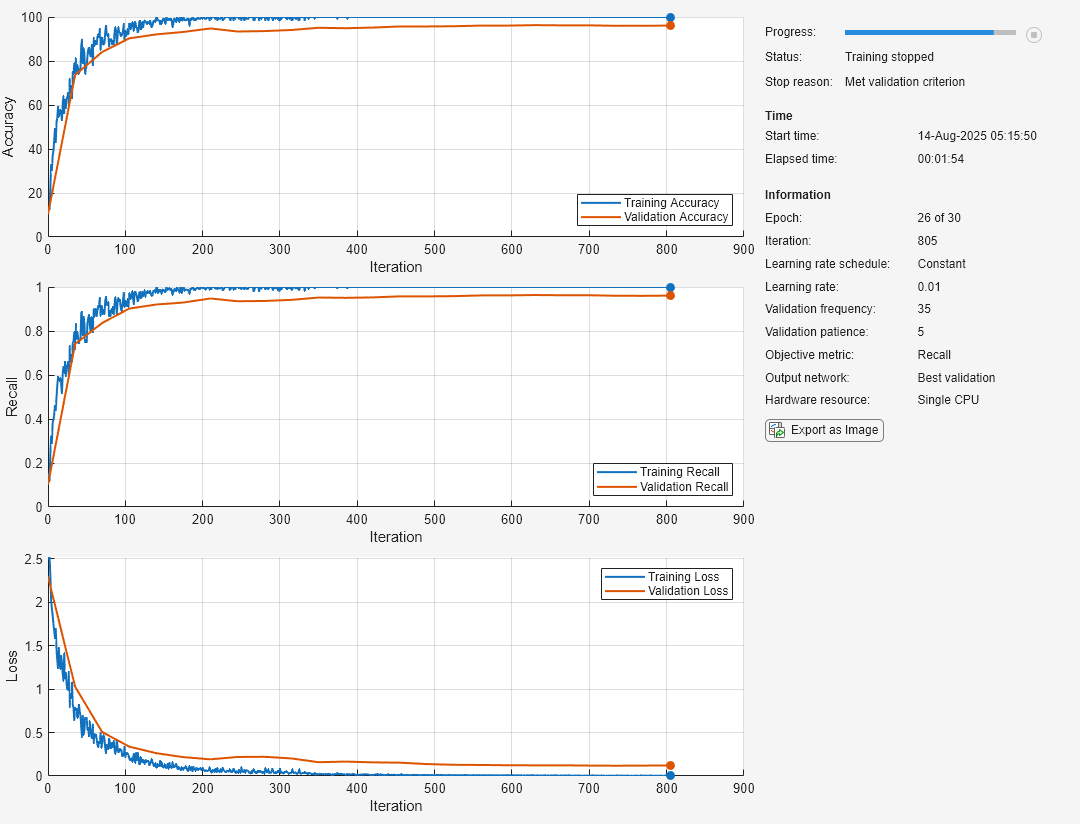
Argumentos de entrada
Argumentos de par nombre-valor
Especifique pares de argumentos opcionales como Name1=Value1,...,NameN=ValueN, donde Name es el nombre del argumento y Value es el valor correspondiente. Los argumentos de nombre-valor deben aparecer después de otros argumentos. Sin embargo, el orden de los pares no importa.
En las versiones anteriores a la R2021a, use comas para separar cada nombre y valor, y encierre Name entre comillas.
Ejemplo: Plots="training-progress",Metrics="accuracy",Verbose=false especifica que se deshabilite la salida detallada y muestra el progreso del entrenamiento en una gráfica que también incluye la métrica de precisión.
Monitorización
Gráficas que se desea visualizar durante el entrenamiento de red neuronal, especificadas como uno de los valores siguientes:
"none": no visualizar gráficas durante el entrenamiento."training-progress": representar el progreso del entrenamiento.
El contenido de la gráfica depende del solver que se use.
Cuando el argumento
solverNamees"sgdm","adam"o"rmsprop", la gráfica muestra la pérdida de minilotes, la pérdida de validación, el minilote de entrenamiento y las métricas de validación especificadas por la opciónMetrics, así como información adicional sobre el progreso del entrenamiento.Cuando el argumento
solverNamees"lbfgs"o"lm", la gráfica muestra la pérdida de validación y entrenamiento, las métricas de validación y entrenamiento especificadas por la opciónMetrics, así como información adicional sobre el progreso del entrenamiento.
Para abrir y cerrar de forma programática la gráfica del progreso del entrenamiento después del entrenamiento, use las funciones show y close con la segunda salida de la función trainnet. Puede usar la función show para ver el progreso del entrenamiento, incluso si la opción de entrenamiento Plots está especificada como "none".
Para cambiar la escala del eje y a logarítmica, utilice la barra de herramientas de los ejes. 
Para obtener más información sobre la gráfica, consulte Monitorizar el progreso del entrenamiento de deep learning.
Desde R2023b
Métricas para monitorizar, especificadas como uno de estos valores:
Nombre de métrica integrada o de la función de pérdida: especifique las métricas como un escalar de cadena, un vector de caracteres o un arreglo de celdas o un arreglo de cadena de uno o varios de estos nombres:
Métricas:
"accuracy": precisión (también conocida como precisión principal)"auc": área bajo la curva ROC (AUC)"fscore": puntuación F (también conocida como puntuación F1)"precision": precisión"recall": recuperación"rmse": raíz del error cuadrático medio"mape": error porcentual absoluto medio (MAPE) (desde R2024b)"rsquared": R2 (R cuadrado o coeficiente de determinación) (desde R2025a)
Funciones de pérdida:
"crossentropy": pérdida de entropía cruzada para tareas de clasificación. (desde R2024b)"indexcrossentropy": índice de pérdida de entropía cruzada para tareas de clasificación. (desde R2024b)"binary-crossentropy": pérdida de entropía cruzada binaria para tareas de clasificación binarias y multietiqueta. (desde R2024b)"mae"/"mean-absolute-error"/"l1loss": error medio absoluto para tareas de regresión. (desde R2024b)"mse"/"mean-squared-error"/"l2loss": error cuadrático medio para tareas de regresión. (desde R2024b)"huber": pérdida de Huber para tareas de regresión (desde R2024b)
Tenga en cuenta que no se puede establecer la función de pérdida como
"crossentropy"y especificar"index-crossentropy"como métrica ni establecer la función de pérdida como"index-crossentropy"y especificar"crossentropy"como métrica.Para obtener más información sobre las métricas de deep learning y las funciones de pérdida, consulte Deep Learning Metrics.
Objeto métrico integrado: si necesita más flexibilidad, puede usar objetos métricos integrados. El software admite estos objetos métricos integrados:
MAPEMetric(desde R2024b)RSquaredMetric(desde R2025a)
Al crear un objeto métrico integrado, puede especificar opciones adicionales, como el tipo promediador y si la tarea es de una sola o de varias etiquetas.
Identificador de función métrica personalizada: si la métrica que necesita no es una métrica integrada, puede especificar métricas personalizadas mediante un identificador de función. La función debe tener la sintaxis
metric = metricFunction(Y,T), dondeYcorresponde a las predicciones de la red yTcorresponde a las respuestas objetivo. Para redes con varias salidas, la sintaxis debe sermetric = metricFunction(Y1,…,YN,T1,…TM), dondeNes el número de salidas yMes el número de objetivos. Para obtener más información, consulte Define Custom Metric Function.Nota
Cuando tiene datos en minilotes, el software calcula la métrica para cada minilote y luego devuelve el promedio de esos valores. Para algunas métricas, este comportamiento puede dar como resultado un valor de métrica diferente que si calcula la métrica usando todo el conjunto de datos a la vez. En la mayoría de los casos, los valores son similares. Para usar una métrica personalizada que no sea un promedio por lotes para los datos, debe crear un objeto métrico personalizado. Para obtener más información, consulte Define Custom Deep Learning Metric Object.
Objeto
deep.DifferentiableFunction(desde R2024a): objeto de función con una función de retropropagación personalizada. Para los objetivos categóricos, el software convierte automáticamente los valores categóricos en vectores codificados one-hot y los pasa a la función métrica. Para obtener más información, consulte Define Custom Deep Learning Operations.Objeto métrico personalizado: si necesita mayor personalización, puede definir su propio objeto métrico personalizado. Para ver un ejemplo de cómo crear una métrica personalizada, consulte Define Custom Metric Object. Para obtener información general sobre la creación de métricas personalizadas, consulte Define Custom Deep Learning Metric Object.
Si especifica una métrica como un identificador de función, un objeto deep.DifferentiableFunction o un objeto métrico personalizado y entrena la red neuronal utilizando la función trainnet, la distribución de los objetivos que el software pasa a la métrica depende del tipo de datos de los objetivos y de la función de pérdida que especifique en la función trainnet y de las otras métricas que especifique:
Si los objetivos son arreglos numéricos, el software pasa los objetivos a la métrica directamente.
Si la función de pérdida es
"index-crossentropy"y los objetivos son arreglos categóricos, el software convierte automáticamente los objetivos en índices de clase numéricos y los pasa a la métrica.Para otras funciones de pérdida, si los objetivos son arreglos categóricos, el software convierte automáticamente los objetivos en vectores codificados one-hot y luego los pasa a la métrica.
Esta opción solo admite las funciones trainnet y trainBERTDocumentClassifier (Text Analytics Toolbox).
Ejemplo: Metrics=["accuracy","fscore"]
Ejemplo: Metrics={"accuracy",@myFunction,precisionObj}
Desde R2024a
Nombre de la métrica objetivo para su uso en la detención temprana y la devolución de la mejor red, especificado como escalar de cadena o vector de caracteres.
El nombre de la métrica debe ser "loss" o coincidir con el nombre de una métrica especificada por el argumento Metrics. Las métricas especificadas mediante identificadores de función no son compatibles. Para especificar el valor ObjectiveMetricName como el nombre de una métrica personalizada, el valor de la propiedad Maximize del objeto métrico personalizado no debe estar vacío. Para obtener más información, consulte Define Custom Deep Learning Metric Object.
Para obtener más información sobre la especificación de la métrica objetivo para la detención temprana, consulte ValidationPatience. Para obtener más información sobre la devolución de la mejor red mediante la métrica objetivo, consulte OutputNetwork.
Tipos de datos: char | string
Indicador para mostrar información sobre el progreso del entrenamiento en la ventana de comandos, especificado como 1 (true) o 0 (false).
El contenido de la salida detallada depende del tipo de solver.
Para los solvers estocásticos (SGDM, Adam y RMSProp), la tabla contiene estas variables:
| Variable | Descripción |
|---|---|
Iteration | Número de iteraciones. |
Epoch | Número de épocas. |
TimeElapsed | Tiempo transcurrido en horas, minutos y segundos. |
LearnRate | Tasa de aprendizaje. |
TrainingLoss | Pérdida de entrenamiento. |
ValidationLoss | Pérdida de validación. Si no especifica datos de validación, el software no muestra esta información. |
Para los solvers por lotes (L-BFGS y LM), la tabla contiene estas variables:
| Variable | Descripción |
|---|---|
Iteration | Número de iteraciones. |
TimeElapsed | Tiempo transcurrido en horas, minutos y segundos. |
TrainingLoss | Pérdida de entrenamiento. |
ValidationLoss | Pérdida de validación. Si no especifica datos de validación, el software no muestra esta información. |
GradientNorm | Norma de los gradientes. |
StepNorm | Norma de los pasos. |
Si especifica métricas adicionales en las opciones de entrenamiento, también aparecerán en la salida detallada. Por ejemplo, si configura la opción de entrenamiento Metrics como "accuracy", la información incluye las variables TrainingAccuracy y ValidationAccuracy.
Cuando el aprendizaje se detiene, la salida detallada muestra la razón de la detención.
Para especificar datos de validación, use la opción de entrenamiento ValidationData.
Tipos de datos: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64 | logical
Frecuencia de la impresión detallada, que es el número de iteraciones entre cada impresión en la ventana de comandos, especificada como un entero positivo.
Si valida la red neuronal durante el entrenamiento, el software también imprime en la ventana de comandos cada vez que tiene lugar la validación.
Para habilitar esta propiedad, establezca la opción de entrenamiento Verbose en 1 (true).
Tipos de datos: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Funciones de salida a las que llamar durante el entrenamiento, especificadas como identificador de función o arreglo de celdas de identificadores de función. El software llama a las funciones una vez antes del inicio del entrenamiento, después de cada iteración y una vez cuando ha finalizado el entrenamiento.
Las funciones deben tener la sintaxis stopFlag = f(info), donde info es una estructura que contiene información sobre el progreso del entrenamiento y stopFlag es un escalar que indica que se debe detener el entrenamiento antes de tiempo. Si stopFlag es 1 (true), el software detiene el entrenamiento. En caso contrario, el software continúa el entrenamiento.
La función trainnet pasa a la función de salida la estructura info.
Para los solvers estocásticos (SGDM, Adam y RMSProp), info contiene estos campos:
| Campo | Descripción |
|---|---|
Epoch | Número de épocas |
Iteration | Número de iteraciones |
TimeElapsed | Tiempo desde el inicio del entrenamiento |
LearnRate | Tasa de aprendizaje de iteraciones |
TrainingLoss | Pérdida de entrenamiento de iteraciones |
ValidationLoss | Pérdida de validación, si se especifica y se evalúa en la iteración. |
State | Estado de entrenamiento de iteraciones, especificado como "start", "iteration" o "done". |
Para los solvers por lotes (L-BFGS y LM), info contiene estos campos:
| Campo | Descripción |
|---|---|
Iteration | Número de iteraciones |
TimeElapsed | Tiempo transcurrido en horas, minutos y segundos |
TrainingLoss | Pérdida de entrenamiento |
ValidationLoss | Pérdida de validación. Si no especifica datos de validación, el software no muestra esta información. |
GradientNorm | Norma de los gradientes |
StepNorm | Norma de los pasos |
State | Estado de entrenamiento de iteraciones, especificado como "start", "iteration" o "done". |
Si especifica métricas adicionales en las opciones de entrenamiento, también aparecerán en la información de entrenamiento. Por ejemplo, si configura la opción de entrenamiento Metrics como "accuracy", la información incluye los campos TrainingAccuracy y ValidationAccuracy.
Si un campo no se calcula o no es relevante para una determinada llamada a las funciones de salida, este contiene un arreglo vacío.
Para ver un ejemplo de cómo utilizar funciones de salida, consulte Custom Stopping Criteria for Deep Learning Training.
Tipos de datos: function_handle | cell
Disposición de datos
Opciones de solvers estocásticos
Número máximo de épocas (pasos completos de los datos) que desea usar para el entrenamiento, especificado como un entero positivo.
Esta opción solo admite solvers estocásticos (cuando el argumento solverName es "sgdm", "adam" o "rmsprop").
Tipos de datos: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Tamaño de minilote que desea usar para cada iteración de entrenamiento, especificado como un entero positivo. Un minilote es un subconjunto del conjunto de entrenamiento que se usa para evaluar el gradiente de la función de pérdida y actualizar los pesos.
Si el tamaño de minilote no divide el número de muestras de entrenamiento de manera uniforme, el software descarta los datos de entrenamiento que no caben en el minilote final completo de cada época. Si el tamaño de minilote es más pequeño que el número de muestras de entrenamiento, el software no descarta ningún dato.
Esta opción solo admite solvers estocásticos (cuando el argumento solverName es "sgdm", "adam" o "rmsprop").
Sugerencia
Para obtener el mejor rendimiento, si está entrenando una red usando un almacén de datos con una propiedad ReadSize, como imageDatastore, establezca la propiedad ReadSize y la opción de entrenamiento MiniBatchSize en el mismo valor. Si está entrenando una red usando un almacén de datos con una propiedad MiniBatchSize, como augmentedImageDatastore, establezca la propiedad MiniBatchSize del almacén de datos y la opción de entrenamiento MiniBatchSize en el mismo valor.
Tipos de datos: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Opción para cambiar el orden de los datos, especificada como uno de estos valores:
"once": cambiar el orden de los datos de entrenamiento y validación una vez antes del entrenamiento."never": no cambiar el orden de los datos."every-epoch": cambiar el orden de los datos de entrenamiento antes de cada época de entrenamiento y cambiar el orden de los datos de validación antes de cada validación de la red neuronal. Si el tamaño de minilote no divide el número de muestras de entrenamiento de manera uniforme, el software descarta los datos de entrenamiento que no caben en el minilote final completo de cada época. Para evitar descartar los mismos datos cada época, establezca la opción de entrenamientoShuffleen"every-epoch".
Esta opción solo admite solvers estocásticos (cuando el argumento solverName es "sgdm", "adam" o "rmsprop").
Tasa de aprendizaje inicial usada para el entrenamiento, especificada como un escalar positivo.
Si la tasa de aprendizaje es demasiado baja, el entrenamiento puede tardar mucho tiempo. Si la tasa de aprendizaje es demasiado alta, el entrenamiento podría lograr un resultado subóptimo o divergir.
Esta opción solo admite solvers estocásticos (cuando el argumento solverName es "sgdm", "adam" o "rmsprop").
Cuando solverName es "sgdm", el valor predeterminado es 0.01. Cuando solverName es "rmsprop" o "adam", el valor predeterminado es 0.001.
Tipos de datos: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Programación de la tasa de aprendizaje, especificada como un vector de caracteres o escalar de cadena de una programación de la tasa de aprendizaje, un arreglo de cadena de nombres, un objeto de programación de la tasa de aprendizaje integrado o personalizado, un identificador de función o un arreglo de celdas de nombres, objetos métricos e identificadores de función.
Esta opción solo admite solvers estocásticos (cuando el argumento solverName es "sgdm", "adam" o "rmsprop").
Nombres de programación de la tasa de aprendizaje integrada
Especifique las programaciones de la tasa de aprendizaje como un escalar de cadena, un vector de caracteres o un arreglo de cadenas o de celdas de uno o más de estos nombres:
| Nombre | Descripción | Gráfica |
|---|---|---|
"none" | No hay ninguna programación de la tasa de aprendizaje. Esta programación mantiene la tasa de aprendizaje constante. |
|
"piecewise" | Programación de la tasa de aprendizaje por partes. Esta programación reduce la tasa de aprendizaje por un factor de 10 cada 10 épocas. |
|
"warmup" (desde R2024b) | Programación de la tasa de aprendizaje de calentamiento. Esta programación aumenta la tasa de aprendizaje hasta la tasa de aprendizaje base durante 5 iteraciones. |
|
"polynomial" (desde R2024b) | Programación de la tasa de aprendizaje polinómica. Esta programación reduce la tasa de aprendizaje utilizando una ley de potencia con un exponente unitario cada época. |
|
"exponential" (desde R2024b) | Programación de la tasa de aprendizaje exponencial. Esta programación reduce la tasa de aprendizaje por un factor de 10 cada época. |
|
"cosine" (desde R2024b) | Programación de la tasa de aprendizaje del coseno. Esta programación reduce la tasa de aprendizaje mediante una fórmula de coseno cada época. |
|
"cyclical" (desde R2024b) | Programación de la tasa de aprendizaje cíclica. Esta programación aumenta la tasa de aprendizaje a partir de la tasa de aprendizaje base durante 5 épocas y, luego, disminuye la tasa de aprendizaje durante 5 épocas, a lo largo de periodos de 10 épocas. |
|







Objeto de programación de la tasa de aprendizaje integrado (desde R2024b)
Si necesita más flexibilidad que la que ofrecen las opciones de cadena, puede utilizar objetos de programación de la tasa de aprendizaje integrados:
piecewiseLearnRate: un objeto de programación de la tasa de aprendizaje por partes disminuye la tasa de aprendizaje periódicamente multiplicándola por un factor especificado. Utilice este objeto para personalizar el factor y periodo de caída de la programación por partes.Antes de R2024b: Personalice el factor y periodo de caída por partes mediante las opciones de entrenamiento
LearnRateDropFactoryLearnRateDropPeriod, respectivamente.warmupLearnRate: un objeto de programación de la tasa de aprendizaje de calentamiento aumenta la tasa de aprendizaje durante un número especificado de iteraciones. Utilice este objeto para personalizar los factores de la tasa de aprendizaje inicial y final y el número de pasos de la programación de calentamiento.polynomialLearnRate: un objeto de programación de la tasa de aprendizaje polinómica reduce la tasa de aprendizaje utilizando una ley de potencia. Utilice este objeto para personalizar los factores de la tasa de aprendizaje inicial y final, el exponente y el número de pasos de la programación polinómica.exponentialLearnRate: un objeto de programación de la tasa de aprendizaje exponencial reduce la tasa de aprendizaje por un factor especificado. Utilice este objeto para personalizar el factor y periodo de caída de la programación exponencial.cosineLearnRate: un objeto de programación de la tasa de aprendizaje de coseno reduce la tasa de aprendizaje utilizando una curva coseno e incorpora reinicios en caliente. Utilice este objeto para personalizar los factores de la tasa de aprendizaje inicial y final, el periodo y el factor de crecimiento del periodo de la programación de coseno.cyclicalLearnRate: un objeto de programación de la tasa de aprendizaje cíclica aumenta y disminuye la tasa de aprendizaje de forma periódica. Utilice esta opción para personalizar el factor máximo, el periodo y la relación de paso de la programación cíclica.
Programación de la tasa de aprendizaje personalizada (desde R2024b)
Para mayor flexibilidad, puede definir una programación de la tasa de aprendizaje personalizada como un identificador de función o una clase personalizada que herede de deep.LearnRateSchedule.
Identificador de función de la programación de la tasa de aprendizaje: si la programación de la tasa de aprendizaje que necesita no es una programación de la tasa de aprendizaje integrada, puede especificar programaciones de la tasa de aprendizaje personalizadas mediante un identificador de función. Para especificar una programación personalizada, utilice un identificador de función con la sintaxis
learningRate = f(baseLearningRate,epoch), dondebaseLearningRatees la tasa de aprendizaje base yepoches el número de época.Objeto de programación de la tasa aprendizaje personalizada: si necesita más flexibilidad que la que proporcionan los identificadores de función, puede definir una clase de programación de la tasa de aprendizaje personalizada que herede de
deep.LearnRateSchedule.
Programaciones de la tasa de aprendizaje múltiples (desde R2024b)
Puede combinar varias programaciones de la tasa de aprendizaje especificando varias programaciones como un arreglo de cadenas o de celdas y, después, el software aplica las programaciones en orden, empezando por el primer elemento. Solo puede ser infinita una de las programaciones (programaciones que continúan indefinidamente, como "cyclical" y objetos con la propiedad NumSteps establecida en Inf) y la programación infinita debe ser el último elemento del arreglo.
Contribución del paso de actualización de parámetros de la iteración previa a la iteración actual del gradiente descendente estocástico con momento, especificada como un escalar de 0 a 1.
Un valor de 0 indica que no hay contribución desde el paso previo, mientras que un valor de 1 indica una contribución máxima desde el paso previo. El valor predeterminado funciona bien para la mayoría de tareas.
Esta opción solo admite el solver SGDM (cuando el argumento solverName es "sgdm").
Para obtener más información, consulte Gradiente descendente estocástico con momento.
Tipos de datos: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Tasa de decaimiento de la media móvil de gradiente para el solver Adam, especificada como un escalar no negativo menor que 1. La tasa de decaimiento del gradiente está denotada por β1 en la sección Estimación de momento adaptativo.
Esta opción solo admite el solver Adam (cuando el argumento solverName es "adam").
Para obtener más información, consulte Estimación de momento adaptativo.
Tipos de datos: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Tasa de decaimiento de la media móvil de gradiente cuadrado para los solvers Adam y RMSProp, especificada como un escalar no negativo menor que 1. La tasa de decaimiento del gradiente cuadrado está denotada por β2 en [4].
Valores típicos de la tasa de decaimiento son 0.9, 0.99 y 0.999, que corresponden a longitudes medias de 10, 100 y 1000 actualizaciones de parámetros, respectivamente.
Esta opción solo admite los solvers Adam y RMSProp (cuando el argumento solverName es "adam" o "rmsprop").
El valor predeterminado es 0.999 para el solver Adam. El valor predeterminado es 0.9 para el solver RMSProp.
Para obtener más información, consulte Estimación de momento adaptativo y Propagación del valor cuadrático medio.
Tipos de datos: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Desplazamiento del denominador para los solvers Adam y RMSProp, especificada como un escalar positivo.
El solver añade el desplazamiento al denominador en las actualizaciones de parámetros de la red neuronal para evitar una división por cero. El valor predeterminado funciona bien para la mayoría de tareas.
Esta opción solo admite los solvers Adam y RMSProp (cuando el argumento solverName es "adam" o "rmsprop").
Para obtener más información, consulte Estimación de momento adaptativo y Propagación del valor cuadrático medio.
Tipos de datos: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Factor para reducir la tasa de aprendizaje, especificado como un escalar de 0 a 1. Esta opción es válida solo cuando la opción de entrenamiento LearnRateSchedule es "piecewise".
LearnRateDropFactor es un factor multiplicativo para aplicar a la tasa de aprendizaje cada vez que pasa un determinado número de épocas. Especifique el número de épocas mediante la opción de entrenamiento LearnRateDropPeriod.
Esta opción solo admite solvers estocásticos (cuando el argumento solverName es "sgdm", "adam" o "rmsprop").
Sugerencia
Para personalizar la programación de la tasa de aprendizaje por partes, utilice un objeto piecewiseLearnRate. Se recomienda el uso de un objeto piecewiseLearnRate en lugar de las opciones de entrenamiento LearnRateDropFactor and LearnRateDropPeriod, ya que proporciona un control adicional sobre la frecuencia de caída. (desde R2024b)
Tipos de datos: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Número de épocas para reducir la tasa de aprendizaje, especificado como un entero positivo. Esta opción es válida solo cuando la opción de entrenamiento LearnRateSchedule es "piecewise".
El software multiplica la tasa de aprendizaje global por el factor de reducción cada vez que pasa el número de épocas especificado. Especifique el factor de reducción mediante la opción de entrenamiento LearnRateDropFactor.
Esta opción solo admite solvers estocásticos (cuando el argumento solverName es "sgdm", "adam" o "rmsprop").
Sugerencia
Para personalizar la programación de la tasa de aprendizaje por partes, utilice un objeto piecewiseLearnRate. Se recomienda el uso de un objeto piecewiseLearnRate en lugar de las opciones de entrenamiento LearnRateDropFactor and LearnRateDropPeriod, ya que proporciona un control adicional sobre la frecuencia de caída. (desde R2024b)
Tipos de datos: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Opciones de solver por lotes
Validación
Regularización y normalización
Recorte de gradiente
Secuencia
Hardware y aceleración
Puntos de control
Argumentos de salida
Sugerencias
Para la mayor parte de las tareas de deep learning, puede utilizar una red neuronal preentrenada y adaptarla a sus propios datos. Para ver un ejemplo de cómo usar la transferencia del aprendizaje para volver a entrenar una red neuronal convolucional para clasificar un nuevo conjunto de imágenes, consulte Volver a entrenar redes neuronales para clasificar nuevas imágenes. Como alternativa, puede crear y entrenar redes neuronales desde cero usando las funciones
trainnetytrainingOptions.Si la función
trainingOptionsno proporciona las opciones de entrenamiento que necesita para la tarea, puede crear un bucle de entrenamiento personalizado mediante diferenciación automática. Para obtener más información, consulte Entrenar una red con un bucle de entrenamiento personalizado.Si la función
trainnetno proporciona la función de pérdida que necesita para la tarea, puede especificar una función de pérdida personalizada paratrainnetcomo identificador de función. Para las funciones de pérdida que requieren más entradas que las predicciones y los objetivos (por ejemplo, funciones de pérdida que requieren acceso a la red neuronal o entradas adicionales), entrene el modelo usando un bucle de entrenamiento personalizado. Para obtener más información, consulte Entrenar una red con un bucle de entrenamiento personalizado.Si Deep Learning Toolbox™ no proporciona las capas que necesita para la tarea, puede crear una capa personalizada. Para obtener más información, consulte Definir capas de deep learning personalizadas. Para los modelos que no se pueden especificar como redes de capas, puede definir el modelo como una función. Para obtener más información, consulte Train Network Using Model Function.
Para obtener más información sobre qué método de entrenamiento usar para cada tarea, consulte Train Deep Learning Model in MATLAB.
Algoritmos
Referencias
[1] Bishop, C. M. Pattern Recognition and Machine Learning. Springer, New York, NY, 2006.
[2] Murphy, K. P. Machine Learning: A Probabilistic Perspective. The MIT Press, Cambridge, Massachusetts, 2012.
[3] Pascanu, R., T. Mikolov, and Y. Bengio. "On the difficulty of training recurrent neural networks". Proceedings of the 30th International Conference on Machine Learning. Vol. 28(3), 2013, pp. 1310–1318.
[4] Kingma, Diederik, and Jimmy Ba. "Adam: A method for stochastic optimization." arXiv preprint arXiv:1412.6980 (2014).
[5] Liu, Dong C., and Jorge Nocedal. "On the limited memory BFGS method for large scale optimization." Mathematical programming 45, no. 1 (August 1989): 503-528. https://doi.org/10.1007/BF01589116.
[6] Marquardt, Donald W. “An Algorithm for Least-Squares Estimation of Nonlinear Parameters.” Journal of the Society for Industrial and Applied Mathematics 11, no. 2 (June 1963): 431–41. https://doi.org/10.1137/0111030.
Historial de versiones
Introducido en R2016aConsulte también
trainnet | dlnetwork | analyzeNetwork | Deep Network Designer