pca
Análisis de los componentes principales de datos sin procesar
Sintaxis
Descripción
coeff = pca(X)X. Las filas de X corresponden a observaciones y las columnas corresponden a variables. Cada columna de la matriz de coeficientes coeff contiene los coeficientes para un componente principal. Las columnas están en orden descendente según la varianza del componente principal. De forma predeterminada, pca centra los datos y utiliza el algoritmo de descomposición en valores singulares (SVD).
coeff = pca(X,Name,Value)Name,Value.
Por ejemplo, puede especificar el número de componentes principales que pca devuelve o el uso de un algoritmo distinto de SVD.
[ también devuelve las puntuaciones de los componentes principales en coeff,score,latent] = pca(___)score y las varianzas de los componentes principales en latent. Puede utilizar cualquiera de los argumentos de entrada de las sintaxis anteriores.
Las puntuaciones de los componentes principales son las representaciones de X en el espacio de los componentes principales. Las filas de score corresponden a observaciones y las columnas corresponden a los componentes.
Las varianzas de los componentes principales son valores propios de la matriz de covarianzas de X.
Ejemplos
Cargue el conjunto de datos de muestra.
load haldLos datos de los ingredientes tienen 13 observaciones de 4 variables.
Encuentre los componentes principales de los datos de los ingredientes.
coeff = pca(ingredients)
coeff = 4×4
-0.0678 -0.6460 0.5673 0.5062
-0.6785 -0.0200 -0.5440 0.4933
0.0290 0.7553 0.4036 0.5156
0.7309 -0.1085 -0.4684 0.4844
Las filas de coeff contienen los coeficientes de las cuatro variables de ingredientes y sus columnas corresponden a los cuatro componentes principales.
Busque los coeficientes de componentes principales cuando falten valores en un conjunto de datos.
Cargue el conjunto de datos de muestra.
load imports-85La matriz de datos X tiene 13 variables continuas en las columnas de la 3 a la 15: distancia entre ejes, longitud, anchura, altura, tara, cilindrada, diámetro, carrera, relación de compresión, potencia, RPM máximas, mpg en ciudad y mpg en autopista. A las variables diámetro y carrera les faltan cuatro valores en las filas de la 56 a la 59 y a las variables potencia y RPM máximas les faltan dos valores en las filas 131 y 132.
Realice los análisis de componentes principales.
coeff = pca(X(:,3:15));
De manera predeterminada, pca lleva a cabo la acción especificada por el argumento de par nombre-valor 'Rows','complete'. Esta opción elimina las observaciones con valores NaN antes del cálculo. Las filas de NaN se vuelven a insertar en score y tsquared en las ubicaciones correspondientes, es decir en las filas 56 a 59, 131 y 132.
Utilice 'pairwise' para realizar el análisis de componentes principales.
coeff = pca(X(:,3:15),'Rows','pairwise');
En este caso, pca computa el elemento (i, j) de la matriz de covarianzas utilizando la filas sin valores NaN en las columnas i o j de X. Tenga en cuenta que la matriz de covarianzas resultante puede no ser definida positiva. Esta opción se aplica cuando el algoritmo pca utiliza la descomposición en valores propios. Cuando no especifica el algoritmo, como en este ejemplo, pca lo establece en 'eig'. Si precisa 'svd' como el algoritmo, con la opción 'pairwise', entonces pca devuelve un mensaje de advertencia, establece el algoritmo en 'eig' y continúa.
Si utiliza el argumento de par nombre-valor 'Rows','all', pca se termina porque esta opción asume que no faltan valores en el conjunto de datos.
coeff = pca(X(:,3:15),'Rows','all');
Error using pca (line 180) Raw data contains NaN missing value while 'Rows' option is set to 'all'. Consider using 'complete' or pairwise' option instead.
Utilice las varianzas de la variable inversa como pesos cuando realice el análisis de componentes principales.
Cargue el conjunto de datos de muestra.
load haldRealice el análisis de componentes principales utilizando la inversa de las varianzas de los ingredientes como pesos variables.
[wcoeff,~,latent,~,explained] = pca(ingredients,'VariableWeights','variance')
wcoeff = 4×4
-2.7998 2.9940 -3.9736 1.4180
-8.7743 -6.4411 4.8927 9.9863
2.5240 -3.8749 -4.0845 1.7196
9.1714 7.5529 3.2710 11.3273
latent = 4×1
2.2357
1.5761
0.1866
0.0016
explained = 4×1
55.8926
39.4017
4.6652
0.0406
Tenga en cuenta que la matriz de coeficientes, wcoeff, no es ortonormal.
Calcule la matriz de coeficientes ortonormal.
coefforth = diag(std(ingredients))\wcoeff
coefforth = 4×4
-0.4760 0.5090 -0.6755 0.2411
-0.5639 -0.4139 0.3144 0.6418
0.3941 -0.6050 -0.6377 0.2685
0.5479 0.4512 0.1954 0.6767
Compruebe la ortonormalidad de la nueva matriz de coeficientes, coefforth.
coefforth*coefforth'
ans = 4×4
1.0000 0.0000 -0.0000 0.0000
0.0000 1.0000 0.0000 0
-0.0000 0.0000 1.0000 -0.0000
0.0000 0 -0.0000 1.0000
Encuentre los componentes principales con el algoritmo de mínimos cuadrados alternos (ALS) donde haya valores faltantes en los datos.
Cargue los datos de muestra.
load haldLos datos de los ingredientes tienen 13 observaciones de 4 variables.
Realice el análisis de componentes principales con el algoritmo ALS y muestre los coeficientes de componentes.
[coeff,score,latent,tsquared,explained] = pca(ingredients); coeff
coeff = 4×4
-0.0678 -0.6460 0.5673 0.5062
-0.6785 -0.0200 -0.5440 0.4933
0.0290 0.7553 0.4036 0.5156
0.7309 -0.1085 -0.4684 0.4844
Introduzca los valores faltantes de forma aleatoria.
y = ingredients; rng('default'); % for reproducibility ix = random('unif',0,1,size(y))<0.30; y(ix) = NaN
y = 13×4
7 26 6 NaN
1 29 15 52
NaN NaN 8 20
11 31 NaN 47
7 52 6 33
NaN 55 NaN NaN
NaN 71 NaN 6
1 31 NaN 44
2 NaN NaN 22
21 47 4 26
NaN 40 23 34
11 66 9 NaN
10 68 8 12
⋮
Aproximadamente al 30% de los datos le faltan valores, indicado por NaN.
Realice el análisis de componentes principales con el algoritmo ALS y muestre los coeficientes de componentes.
[coeff1,score1,latent,tsquared,explained,mu1] = pca(y,... 'algorithm','als'); coeff1
coeff1 = 4×4
-0.0362 0.8215 -0.5252 0.2190
-0.6831 -0.0998 0.1828 0.6999
0.0169 0.5575 0.8215 -0.1185
0.7292 -0.0657 0.1261 0.6694
Muestre la media estimada.
mu1
mu1 = 1×4
8.9956 47.9088 9.0451 28.5515
Reconstruya los datos observados.
t = score1*coeff1' + repmat(mu1,13,1)
t = 13×4
7.0000 26.0000 6.0000 51.5250
1.0000 29.0000 15.0000 52.0000
10.7819 53.0230 8.0000 20.0000
11.0000 31.0000 13.5500 47.0000
7.0000 52.0000 6.0000 33.0000
10.4818 55.0000 7.8328 17.9362
3.0982 71.0000 11.9491 6.0000
1.0000 31.0000 -0.5161 44.0000
2.0000 53.7914 5.7710 22.0000
21.0000 47.0000 4.0000 26.0000
21.5809 40.0000 23.0000 34.0000
11.0000 66.0000 9.0000 5.7078
10.0000 68.0000 8.0000 12.0000
⋮
El algoritmo ALS estima los valores faltantes en los datos.
Otra manera de comparar los resultados es encontrar el ángulo entre los dos espacios comprendidos por los vectores de coeficientes. Encuentre el ángulo entre los coeficientes encontrados para los datos completos y los datos con valores faltantes utilizando ALS.
subspace(coeff,coeff1)
ans = 8.7537e-16
Este es un valor pequeño. Indica que los resultados, si usa pca con el argumento de par nombre-valor 'Rows','complete' cuando no faltan datos y si usa pca con el argumento de par nombre-valor 'algorithm','als' cuando faltan datos, están cerca.
Realice el análisis de componentes principales con el argumento de par nombre-valor 'Rows','complete' y muestre los coeficientes de los componentes.
[coeff2,score2,latent,tsquared,explained,mu2] = pca(y,... 'Rows','complete'); coeff2
coeff2 = 4×3
-0.2054 0.8587 0.0492
-0.6694 -0.3720 0.5510
0.1474 -0.3513 -0.5187
0.6986 -0.0298 0.6518
En este caso, pca elimina las filas con valores faltantes e y tiene solo cuatro filas sin valores faltantes. pca devuelve solo los otros componentes principales. No puede utilizar la opción 'Rows','pairwise' porque la matriz de covarianzas no es semidefinida positiva y pca devuelve un mensaje de error.
Encuentre el ángulo entre los coeficientes encontrados para los datos completos y los datos con valores faltantes utilizando la eliminación por lista (cuando 'Rows','complete').
subspace(coeff(:,1:3),coeff2)
ans = 0.3576
El ángulo entre los dos espacios es sustancialmente más grande. Esto indica que estos dos resultados son diferentes.
Muestre la media estimada.
mu2
mu2 = 1×4
7.8889 46.9091 9.8750 29.6000
En este caso, la media es solo la media de muestra de y.
Reconstruya los datos observados.
score2*coeff2'
ans = 13×4
NaN NaN NaN NaN
-7.5162 -18.3545 4.0968 22.0056
NaN NaN NaN NaN
NaN NaN NaN NaN
-0.5644 5.3213 -3.3432 3.6040
NaN NaN NaN NaN
NaN NaN NaN NaN
NaN NaN NaN NaN
NaN NaN NaN NaN
12.8315 -0.1076 -6.3333 -3.7758
NaN NaN NaN NaN
NaN NaN NaN NaN
1.4680 20.6342 -2.9292 -18.0043
⋮
Esto muestra que las filas que contienen valores NaN no funcionan tan bien como el algoritmo ALS. Utilizar ALS es mejor cuando a los datos les faltan demasiados valores.
Encuentre los coeficientes, las puntuaciones y las varianzas de los componentes principales.
Cargue el conjunto de datos de muestra.
load haldLos datos de los ingredientes tienen 13 observaciones de 4 variables.
Encuentre los coeficientes, las puntuaciones y las varianzas de los componentes principales para los datos de los ingredientes.
[coeff,score,latent] = pca(ingredients)
coeff = 4×4
-0.0678 -0.6460 0.5673 0.5062
-0.6785 -0.0200 -0.5440 0.4933
0.0290 0.7553 0.4036 0.5156
0.7309 -0.1085 -0.4684 0.4844
score = 13×4
36.8218 -6.8709 -4.5909 0.3967
29.6073 4.6109 -2.2476 -0.3958
-12.9818 -4.2049 0.9022 -1.1261
23.7147 -6.6341 1.8547 -0.3786
-0.5532 -4.4617 -6.0874 0.1424
-10.8125 -3.6466 0.9130 -0.1350
-32.5882 8.9798 -1.6063 0.0818
22.6064 10.7259 3.2365 0.3243
-9.2626 8.9854 -0.0169 -0.5437
-3.2840 -14.1573 7.0465 0.3405
9.2200 12.3861 3.4283 0.4352
-25.5849 -2.7817 -0.3867 0.4468
-26.9032 -2.9310 -2.4455 0.4116
⋮
latent = 4×1
517.7969
67.4964
12.4054
0.2372
Cada columna de score corresponde a un componente principal. El vector latent almacena las varianzas de los cuatro componentes principales.
Reconstruya los datos de ingredientes centrados.
Xcentered = score*coeff'
Xcentered = 13×4
-0.4615 -22.1538 -5.7692 30.0000
-6.4615 -19.1538 3.2308 22.0000
3.5385 7.8462 -3.7692 -10.0000
3.5385 -17.1538 -3.7692 17.0000
-0.4615 3.8462 -5.7692 3.0000
3.5385 6.8462 -2.7692 -8.0000
-4.4615 22.8462 5.2308 -24.0000
-6.4615 -17.1538 10.2308 14.0000
-5.4615 5.8462 6.2308 -8.0000
13.5385 -1.1538 -7.7692 -4.0000
-6.4615 -8.1538 11.2308 4.0000
3.5385 17.8462 -2.7692 -18.0000
2.5385 19.8462 -3.7692 -18.0000
⋮
Los nuevos datos en Xcentered son los datos de ingredientes originales centrados restando las medias de la columna de las columnas correspondientes.
Visualice los coeficientes de los componentes principales ortonormales para cada variable y las puntuaciones de componentes principales para cada observación en una sola gráfica.
biplot(coeff(:,1:2),'scores',score(:,1:2),'varlabels',{'v_1','v_2','v_3','v_4'});
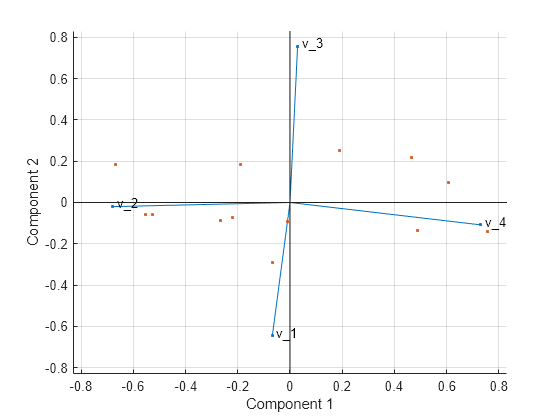
Las cuatro variables están representadas en este biplot por un vector, y la dirección y la longitud del vector indican cómo contribuye cada variable a los dos componentes principales en la gráfica. Por ejemplo, el primer componente principal, que se encuentra en el eje horizontal, tiene coeficientes positivos para la tercera y cuarta variable. Por lo tanto, los vectores y se indican en la mitad derecha de la gráfica. El mayor coeficiente en el primer componente principal es el cuarto, lo que corresponde con la variable .
El segundo componente principal, que está en el eje vertical, tiene coeficientes negativos para las variables , y , y un coeficiente positivo para la variable .
Este biplot en 2D también incluye un punto para cada una de las 13 observaciones, con coordenadas que indican la puntuación de cada observación para los dos componentes principales de la gráfica. Por ejemplo, los puntos cerca del borde izquierdo de la gráfica tienen las puntuaciones más bajas para el primer componente principal. Los puntos están escalados con respecto al valor de puntuación máximo y a la longitud máxima del coeficiente, por lo que solo se pueden determinar sus ubicaciones relativas a partir de la gráfica.
Encuentre los valores de la estadística de T-cuadrado de Hotelling.
Cargue el conjunto de datos de muestra.
load haldLos datos de los ingredientes tienen 13 observaciones de 4 variables.
Realice el análisis de los componentes principales y solicite los valores de T-cuadrado.
[coeff,score,latent,tsquared] = pca(ingredients); tsquared
tsquared = 13×1
5.6803
3.0758
6.0002
2.6198
3.3681
0.5668
3.4818
3.9794
2.6086
7.4818
4.1830
2.2327
2.7216
⋮
Solicite solo los primeros dos componentes principales y calcule los valores de T-cuadrado en el espacio reducido de los componentes principales solicitados.
[coeff,score,latent,tsquared] = pca(ingredients,'NumComponents',2);
tsquaredtsquared = 13×1
5.6803
3.0758
6.0002
2.6198
3.3681
0.5668
3.4818
3.9794
2.6086
7.4818
4.1830
2.2327
2.7216
⋮
Tenga en cuenta que incluso cuando especifica un espacio de componente reducido, pca calcula los valores de T-cuadrado en el espacio completo, utilizando los cuatro componentes.
El valor de T-cuadrado en el espacio reducido se corresponde con la distancia de Mahalanobis en el espacio reducido.
tsqreduced = mahal(score,score)
tsqreduced = 13×1
3.3179
2.0079
0.5874
1.7382
0.2955
0.4228
3.2457
2.6914
1.3619
2.9903
2.4371
1.3788
1.5251
⋮
Calcule los valores T-cuadrado en el espacio descartado tomando la diferencia de los valores T-cuadrado en el espacio completo y la distancia de Mahalanobis en el espacio reducido.
tsqdiscarded = tsquared - tsqreduced
tsqdiscarded = 13×1
2.3624
1.0679
5.4128
0.8816
3.0726
0.1440
0.2362
1.2880
1.2467
4.4915
1.7459
0.8539
1.1965
⋮
Encuentre la variabilidad del porcentaje explicada por los componentes principales. Muestre la representación de los datos en el espacio de componentes principales.
Cargue el conjunto de datos de muestra.
load imports-85La matriz de datos X tiene 13 variables continuas en las columnas de la 3 a la 15: distancia entre ejes, longitud, anchura, altura, tara, cilindrada, diámetro, carrera, relación de compresión, potencia, RPM máximas, mpg en ciudad y mpg en autopista.
Encuentre la variabilidad del porcentaje explicada por los componentes principales de estas variables.
[coeff,score,latent,tsquared,explained] = pca(X(:,3:15)); explained
explained = 13×1
64.3429
35.4484
0.1550
0.0379
0.0078
0.0048
0.0013
0.0011
0.0005
0.0002
0.0002
0.0000
0.0000
⋮
Los tres primeros componentes explican el 99,95% de toda la variabilidad.
Visualice la representación de datos en el espacio de los tres primeros componentes principales.
scatter3(score(:,1),score(:,2),score(:,3)) axis equal xlabel('1st Principal Component') ylabel('2nd Principal Component') zlabel('3rd Principal Component')

Los datos muestran la mayor variabilidad a lo largo del primer eje de componentes principales. Esta es la mayor varianza posible entre todas las opciones posibles del primer eje. La variabilidad a lo largo del segundo eje de componentes principales es la mayor entre todas las posibles opciones restantes del segundo eje. El tercer eje de componentes principales tiene la tercera mayor variabilidad, que es significativamente menor que la variabilidad a lo largo del segundo eje de componentes principales. No merece la pena examinar los ejes de componentes principales cuarto a decimotercero, porque solo explican el 0,05% de toda la variabilidad de los datos.
Para omitir cualquiera de las salidas, puede utilizar ~ en vez del elemento correspondiente. Por ejemplo, si no quiere obtener los valores de T-cuadrado, especifique:
[coeff,score,latent,~,explained] = pca(X(:,3:15));
Encuentre los componentes principales para un conjunto de datos y aplique el PCA a otro conjunto de datos. Este procedimiento es útil cuando tiene un conjunto de datos de entrenamiento y un conjunto de datos de prueba para un modelo de machine learning. Por ejemplo, puede procesar previamente el conjunto de datos de entrenamiento utilizando el PCA y después formando un modelo. Para probar el modelo formado utilizando el conjunto de datos de prueba, tiene que aplicar la transformación del PCA obtenida de los datos de entrenamiento al conjunto de datos de prueba.
Este ejemplo también describe cómo generar código C/C++. Debido a que pca es compatible con la generación de código, puede generar código que lleve a cabo el PCA con un conjunto de datos de entrenamiento y aplica el PCA al conjunto de datos de prueba. Después implemente el código en un dispositivo. En este flujo de trabajo, debe pasar los datos de entrenamiento, que pueden tener un tamaño considerable. Para ahorrar memoria en el dispositivo, puede separar el entrenamiento y la predicción. Utilice pca en MATLAB® y aplique PCA a datos nuevos en el código generado en el dispositivo.
Generar código C/C++ requiere MATLAB® Coder™.
Aplicar PCA a nuevos datos
Cargue el conjunto de datos a una tabla mediante readtable. El conjunto de datos está en el archivo CreditRating_Historical.dat, que contiene los datos históricos de calificación de crédito.
creditrating = readtable('CreditRating_Historical.dat');
creditrating(1:5,:)ans=5×8 table
ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA Industry Rating
_____ _____ _____ _______ ________ _____ ________ _______
62394 0.013 0.104 0.036 0.447 0.142 3 {'BB' }
48608 0.232 0.335 0.062 1.969 0.281 8 {'A' }
42444 0.311 0.367 0.074 1.935 0.366 1 {'A' }
48631 0.194 0.263 0.062 1.017 0.228 4 {'BBB'}
43768 0.121 0.413 0.057 3.647 0.466 12 {'AAA'}
La primera columna es un ID de cada observación y la última columna es una calificación. Especifique las columnas de la segunda a la séptima como datos predictores y especifique la última columna (Rating) como la respuesta.
X = table2array(creditrating(:,2:7)); Y = creditrating.Rating;
Utilice las 100 primeras observaciones como datos de prueba y el resto como datos de entrenamiento.
XTest = X(1:100,:); XTrain = X(101:end,:); YTest = Y(1:100); YTrain = Y(101:end);
Encuentre los componentes principales para el conjunto de datos de entrenamiento XTrain.
[coeff,scoreTrain,~,~,explained,mu] = pca(XTrain);
Este código devuelve cuatro salidas: coeff, scoreTrain, explained y mu. Utilice explained (porcentaje de la varianza total explicada) para encontrar el número de componentes necesarios para explicar una variabilidad de al menos un 95%. Utilice coeff (coeficientes de componentes principales) y mu (medias estimadas de XTrain) para aplicar el PCA a un conjunto de datos de prueba. Utilice scoreTrain (puntuaciones de componentes principales) en vez de XTrain cuando entrene un modelo.
Muestre la variabilidad del porcentaje explicada por los componentes principales.
explained
explained = 6×1
58.2614
41.2606
0.3875
0.0632
0.0269
0.0005
Los dos primeros componentes explican más del 95% de toda la variabilidad. Encuentre el número de componentes necesario para explicar al menos el 95% de la variabilidad.
idx = find(cumsum(explained)>95,1)
idx = 2
Forme un árbol de clasificación con los primeros dos componentes.
scoreTrain95 = scoreTrain(:,1:idx); mdl = fitctree(scoreTrain95,YTrain);
mdl es un modelo de ClassificationTree.
Para utilizar el modelo formado para el conjunto de prueba, tiene que transformar el conjunto de datos con el PCA obtenido del conjunto de datos de entrenamiento. Obtenga las puntuaciones de componentes principales del conjunto de datos de prueba restando mu de XTest y multiplicándolo por coeff. Solo son necesarias las puntuaciones de los dos primeros componentes, por lo que se utilizan los dos primeros coeficientes coeff(:,1:idx).
scoreTest95 = (XTest-mu)*coeff(:,1:idx);
Pase el modelo formado mdl y el conjunto de datos de prueba transformado scoreTest a la función predict para predecir las calificaciones para el conjunto de prueba.
YTest_predicted = predict(mdl,scoreTest95);
Generar código
Genere código que aplique PCA a los datos y prediga la calificación con el modelo formado. Tenga en cuenta que generar código C/C++ requiere MATLAB® Coder™.
Guarde el modelo de clasificación en el archivo myMdl.mat con saveLearnerForCoder.
saveLearnerForCoder(mdl,'myMdl');Defina una función de punto de entrada nombrado myPCAPredict que acepta un conjunto de datos de prueba (XTest) e información del PCA (coeff y mu) y devuelve las calificaciones de los datos de prueba.
Añada la directiva del compilador (o pragma) %#codegen a la función de punto de entrada después de la firma de la función para indicar que intenta generar código para el algoritmo de MATLAB. Añadir esta directiva instruye al analizador de código de MATLAB para ayudarle a diagnosticar y arreglar vulneraciones que provocarían errores durante la generación de código.
function label = myPCAPredict(XTest,coeff,mu) %#codegen % Transform data using PCA scoreTest = bsxfun(@minus,XTest,mu)*coeff; % Load trained classification model mdl = loadLearnerForCoder('myMdl'); % Predict ratings using the loaded model label = predict(mdl,scoreTest);
myPCAPredict aplica el PCA a los nuevos datos con coeff y mu, y predice las calificaciones con los datos transformados. De esta manera, no tiene que pasar los datos de entrenamiento, que pueden ser de un tamaño considerable.
Nota: si hace clic en el botón ubicado en la zona superior derecha de esta página y abre este ejemplo en MATLAB®, MATLAB® abrirá la carpeta de ejemplo. Esta carpeta incluye el archivo de función de punto de entrada.
Genere código mediante codegen (MATLAB Coder). Dado que C y C++ son lenguajes de tipado estático, debe determinar las propiedades de todas las variables de la función de entrada en tiempo de compilación. Para especificar los tipos de datos y el tamaño de arreglo de entrada exacto, pase una expresión de MATLAB® que represente el conjunto de valores con un tipo de datos y un tamaño de arreglo determinado con la opción -args. Si el número de observaciones no se conoce en el momento de la compilación, también puede especificar la entrada como tamaño variable utilizando coder.typeof (MATLAB Coder). Para obtener más detalles, consulte Specify Variable-Size Arguments for Code Generation of Machine Learning Models.
codegen myPCAPredict -args {coder.typeof(XTest,[Inf,6],[1,0]),coeff(:,1:idx),mu}
Code generation successful.
codegen genera la función MEX de myPCAPredict_mex con una extensión dependiente de la plataforma.
Compruebe el código generado.
YTest_predicted_mex = myPCAPredict_mex(XTest,coeff(:,1:idx),mu); isequal(YTest_predicted,YTest_predicted_mex)
ans = logical
1
isequal devuelve una lógica 1 (true), lo que significa que todas las entradas son iguales. La comparación confirma que la función predict de mdl y la función myPCAPredict_mex devuelven las mismas calificaciones.
Para obtener más información sobre la generación de código, consulte Introduction to Code Generation for Statistics and Machine Learning Functions y Generate Code at Command Line Using Model Exported from Machine Learning App. Este último describe cómo realizar el PCA y entrenar un modelo mediante la app Classification Learner, y cómo generar código C/C++ que prediga las etiquetas de los nuevos datos basándose en el modelo formado.
Argumentos de entrada
Argumentos de par nombre-valor
Argumentos de salida
Más acerca de
Algoritmos
La función pca impone una convención de signos, forzando que el elemento con la mayor magnitud en cada columna de coefs sea positivo. Cambiar el símbolo de un vector de coeficientes no cambia su significado.
Funcionalidad alternativa
App
Para ejecutar pca de forma interactiva en Live Editor, utilice la tarea Reduce Dimensionality de Live Editor.
Referencias
[1] Jolliffe, I. T. Principal Component Analysis. 2nd ed., Springer, 2002.
[2] Krzanowski, W. J. Principles of Multivariate Analysis. Oxford University Press, 1988.
[3] Seber, G. A. F. Multivariate Observations. Wiley, 1984.
[4] Jackson, J. E. A. User's Guide to Principal Components. Wiley, 1988.
[5] Roweis, S. “EM Algorithms for PCA and SPCA.” In Proceedings of the 1997 Conference on Advances in Neural Information Processing Systems. Vol.10 (NIPS 1997), Cambridge, MA, USA: MIT Press, 1998, pp. 626–632.
[6] Ilin, A., and T. Raiko. “Practical Approaches to Principal Component Analysis in the Presence of Missing Values.” J. Mach. Learn. Res.. Vol. 11, August 2010, pp. 1957–2000.
Capacidades ampliadas
Historial de versiones
Introducido en R2012b
Consulte también
barttest | biplot | canoncorr | factoran | pcacov | pcares | rotatefactors | ppca | incrementalPCA | Reduce Dimensionality