Speed Up Simulations | New Ways to Work in Simulink, Part 5
From the series: New Ways to Work in Simulink
Maximize the performance of your simulations with the latest developments in solver technology, cached simulation artifacts, and other enhancements in the simulation workflow. You can also use parallelism to scale up your large-scale simulations.
Published: 30 Aug 2020
In this video, let's see what's new in Simulink to speed up your simulations. We'll talk about running simulations in parallel, solver technology, cached simulation artifacts, and other enhancements in the simulational workflow.
One easy way to speed up your simulations is to run them in parallel with the parsim command. Running simulations in parallel is one of those really simple techniques that gives you huge gains in productivity. Our goal with making this simple is that you can focus on solving the design problem rather than setting up the parallel simulations. It's just as easy to use multiple cores on your machine as it is to scale-up to use hundreds and thousands of workers in clusters.
To run in parallel, you just need to use a few lines of MATLAB code to create a simulation input object. You specify the parameters you want to vary. And then simulate with the parsim command to run hundreds, thousands, and millions of simulations. You also have the option to run parallel simulations in batch mode using the batchsim command. This way, you offload your simulation jobs to compute clusters. And these batch simulation jobs can run in the background, which means you can close your MATLAB session and get the results from the cluster the next day or when you need them.
Once you run your simulations in parallel, you will need to monitor them and visualize them. The simulation manager is the interface for these parallel simulation workflows. So you can monitor progress and analyze results as the simulations run, with plots you can configure. All you have to do to see the simulation manager is add this name-value pair to the parsim command. And here, you can add other name value pairs for things like fast restart, which can help you run simulations even faster.
With this code, we get visuals of the simulation progress. We get scatter plots-- in this case, of the simulation status. Surface plots of variables of interest. And we can change those variables. And you can customize how that information is presented to you. You can also save this session for later analysis.
To run the simulations in parallel with parsim, you need the Parallel Computing Toolbox for local workers. In addition, you can use MATLAB Parallel Server for multiple compute clusters, clouds, and grids.
Here is a quick big-picture summary of parallel simulation capabilities. You set up the parallel simulations with a simulation input object. Then you can execute with parsim, parsim while running in background, or batchsim. And these are the type of output objects and their properties based on how you choose to execute your parallel simulations. For more details on multiple simulation workflows, you can check out our documentation.
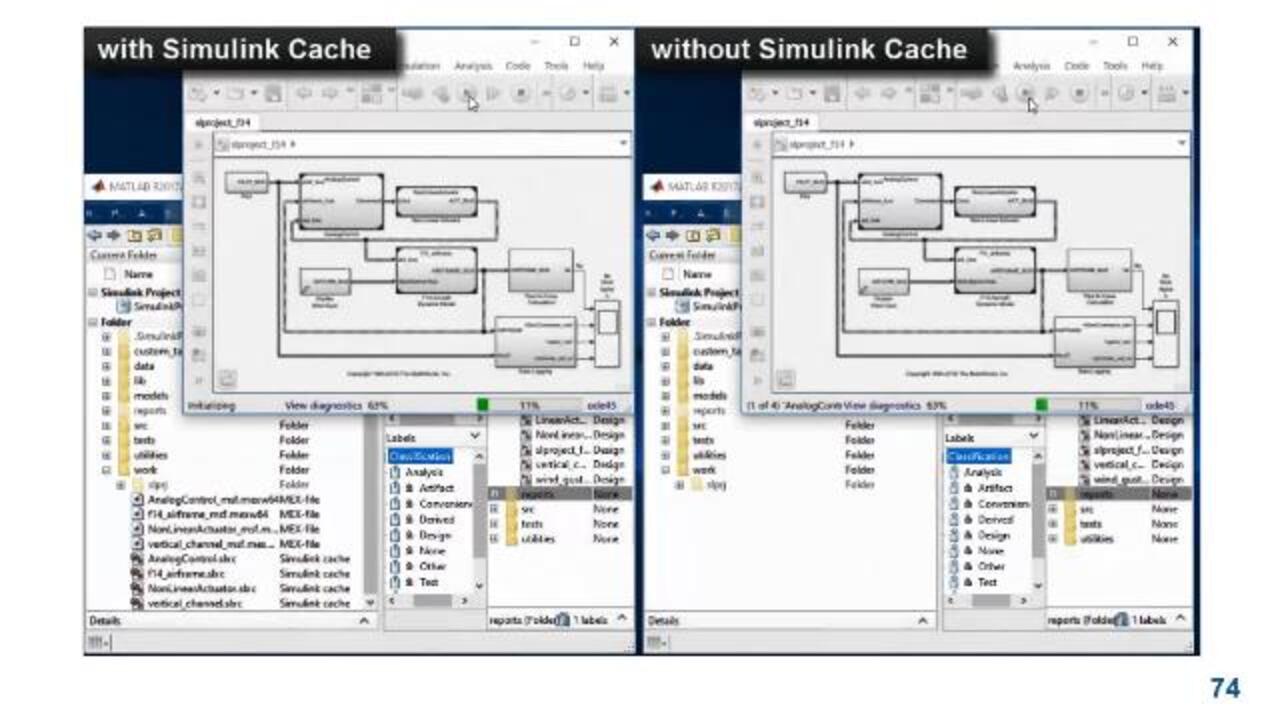
Another way to speed up simulations and co-generation is with Simulink cache files. These cache files are autogenerated during model update. You can share them across teams to skip model rebuilds. So let's see a comparison. Here, I have two instances of the same model. And we also see that the model contains things like model references. So the one on the left is using the cache files. And you also see that the simulation starts much faster. In fact, it's done while the model on the right with other cache files is still compiling.
Most teams can benefit from Simulink cache files, but these cache files are best suited for teams that have model hierarchies with reference models, a top model that simulates an accelerator or rapid accelerator mode, a standardized platform compiler Simulink release and paths for the whole team, and a source control to manage design files.
To speed up simulations, you can also tried different simulation modes like accelerator mode. Accelerator mode got even better because your simulations in this mode will start up faster than before, thanks so that just-in-time, or JIT, builds. JIT gives you the best performance for the generation of the accelerator target for a model because Simulink generates an execution engine in memory instead of generating code before running the simulations.
A critical piece for simulation performance is the solver. Now you have solver improvements available that make it easier for you to simulate and debug your models. One of these improvements is that Simulink can automatically select a solver in the step size that is optimized for your specific model. And it considers factors like the model stiffness and simulation performance.
All new Simulink models use the Automatic Solver Option, but you can lock down the solver so that it does not change from one simulation to another. Another solver improvement is the Solver Profiler. The Solver Profiler gives you a simple way to find issues that cause poor simulation performance through solver statistics rather than guessing what could be wrong with the model.
As an example, let's imagine we simulate this model here. When we've run it, we get an assertion error that points to a couple of places. We could click those links but we could also open up the Solver Profiler by clicking the graph icon in the solver shortcut. Now, we see solver statistics like the plot of the step size, solver exceptions, solver resets, zero crossings, and more.
If we select this condenser pipe block, we can highlight it in the model. We can open, and we see that the issue is that the units are in millimeters rather than meters. So once we fix that issue, we can run the model again. And you'll see that it runs all the way through. So the Solver Profiler gives you a simple way to find issues and bottlenecks affecting simulation performance through solver statistics. We saw that it makes it easy for you to pinpoint the specific parts of the model causing bottlenecks.
You can also improve your solver performance by specifying the execution domains of subsystems in your models. That means you set up parts of your model to simulate as discrete-time or nondiscrete-time This way, subsystems can remain discrete regardless of the surrounding blocks.
For instance, in this model on the right, the controller of the model has yellow sample time legend. Which means hybrid because there is a continuous signal going into blocks in that subsystem. As a better alternative, we can configure the subsystem to be discrete. By doing that, I can improve simulation speed and code quality because I reduce the number of solver resets. Now, solver resets are one of those solver statistics I can analyze with the Solver Profiler. And they occur when a model has a discrete signal driving a block with continuous states, like in this image.
There is a second aspect to this feature, which is data flow. And data flow is a new execution domain that can be used to simulate multirate signal processing systems that are computationally intensive. Data flow requires DSP System Toolbox. And you can use this new execution domain to leverage the multiple cores of a host computer because it automatically partitions the model and does the simulation using multiple threads. So one more new way to improve simulation performance.
Finally, if you have big data, you can bring it into Simulink without slowdowns. That's because Import File Streaming helps you work with that data without having to load all of it into memory. You just load a small chunk.
So in this example, I have a MAT-file with 17 gigabytes of data. To work with that data in Simulink, all I have to do is create a data set reference object that points to the data in that file. I assign values from the data set reference to these variables. Then, I create a new data set object and place references into it. Now, in the model, I specified the data set as an input. And when I run the model, you see that the simulation is not consuming all of my resources because it's not loading all the data to memory. So this gives you a way to speed up your simulations when you have workflows with big data.
That brings us to the end of new capabilities in Simulink to speed up your simulations. I'll see you in the next video.








Seleccione un país/idioma
Seleccione un país/idioma para obtener contenido traducido, si está disponible, y ver eventos y ofertas de productos y servicios locales. Según su ubicación geográfica, recomendamos que seleccione: United States.
También puede seleccionar uno de estos países/idiomas:
América
- América Latina (Español)
- Canada (English)
- United States (English)
Europa
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)