Predictive Maintenance for Industrial Robotics | Robotics for Smart Factory, Part 2
From the series: Robotics for Smart Factory
A predictive approach to maintenance operations guarantees advantages such as reducing machine downtime, eliminating unnecessary interventions, and adding revenue streams for equipment vendors with aftermarket services. These benefits are achievable, but there are challenges in implementing predictive maintenance in application fields such as industrial robotics. One obstacle is the limited availability of functioning data and the lack of failure data needed for accurate results. In addition, choosing the best models for monitoring and prediction can be time consuming, and integrating devised algorithms with existing tools and infrastructures can cause a bottleneck in the implementation process. In this talk, we will analyze the benefits and challenges of predictive maintenance, and describe, via the exploration of a real case-study, the solution proposed by MathWorks to overcome these obstacles and realize efficient predictive maintenance systems.
Published: 14 Feb 2022
Hi-yo. I am Gianfranco Fiore, application engineer at MathWorks. And today I will talk about predictive maintenance for industrial robotics. Specifically, I will discuss approaches to maintenance, highlighting the advantages of applying predictive maintenance to industrial assets. Then I will walk you through the typical workflow for implementing predictive maintenance applications, while exploring also the tools available in the MathWorks ecosystem to develop them. Moreover, I will also present a case study to show how the aforementioned tools can be applied to the solution of practical problems. And then I will conclude with final remarks.
Maintenance is as important as the operation of a machine itself. Because production assets can be very expensive, and their failures could be dangerous and have also negative impacts on the production process, and the budget as well. Moreover, maintenance operations could be also expensive and in some cases dangerous. Thus, approaches aiming at optimizing such activities could lead to the subsequent optimization of time or resources, and also pave the way to new business opportunities such as, for instance, services station
So let's see which are the main approaches to maintenance. As a first strategy, one could think of acting in a reactive manner. Reactive maintenance, as the name suggests, is indeed about forming an intervention on the apparatus when a failure occurs. Alternatively, it is possible to perform operations at regular time intervals according a predefined schedule. This approach is defined preventive or scheduled maintenance.
In both cases, reactive and preventive maintenance, timing materials are not optimized. In fact, with the first approach, a failure could surprise the plant management. With the latter instead, consumables and materials with still useful life could be substituted and then wasted.
Conversely, when strategies to forecast possible problems and failures are put in place, we can talk about predictive maintenance. And in the wide spectrum of predictive maintenance, it is possible to identify three main applications. The first is anomaly detection. It consists in automatically identifying, from real-time data, anomalies-- even those anomalies that are in general difficult to be found by experts via classic approaches. The second is condition monitoring. That is all about performing a sort of automatic root cause analysis on the identified anomalies. The third is remaining useful life estimation-- namely, estimating for how long a machine or its components will still operate safely.
These applications all employ abocked trained models to digest historical and real-time data to inform smarter decisions about maintenance operations. These model decisions can have significant impacts-- for instance, can make it possible to optimize planned operativity by reducing machine stop time; can make it possible to reach cost savings by increasing assets' average life and optimizing consumables and spare parts; and it could make it possible also to introduce new business opportunities via the offer of tailored additional services to customers.
Thus, at least moving towards predictive maintenance approaches has a positive impact on cost reduction and possibly increase of profits associated to maintenance services. But on the other hand, the design complexity increases a lot.
So to tame efficiently these increasing complexities, several things are needed. Above all, it is necessary to count on updated infrastructures for data acquisition and streaming, as well as specific skills, novel methods, and versatile tools. So in order to take a closer look at what it is needed to implement a predictive maintenance application, I'd like to dissect what is the predictive maintenance workflow.
So everything, as you may imagine, starts from the data. And now, in industrial plans, for instance, we acquire, stream, tag, and store more data than ever, thanks to modern communication protocols and availability of powerful hardware. But very often, one of the major obstacles to the use of data is represented by missing failure data. This is really limitative, as failure data are essential to capture dynamics to inform maintenance decisions.
In this case, model-based design shall be used to complement field data with synthetic data generated from other models. In fact, simulations become a fundamental tool to virtually reproduce several operating conditions, even those that are unknown, thus increasing the amount of available data while saving the time and money that instead will then be needed to carry out tests and trials on real assets.
Data, of course, could be messy and dirty and incomplete, for instance. Hence, data has to be pre-processed and made ready for the next steps of the workflow. This type of pre-processing can be really a time-consuming activity which requires a deep knowledge of the processes under investigation, as well as powerful tools for data visualization, inspection, and analysis.
The next step is that of identifying, among the data, the condition indicators which could be used to retrieve useful info from the process being monitored. Condition indicators are elaborated by a model trained for specific purposes-- anomaly detection, condition monitoring, or estimation of remaining useful life. Models are trained and validated in an iterative process that only ends when the performance of the model reaches a desired target.
The final step consists in deploying models and algorithms to the platforms and systems where the application is supposed to work. Embedded edge and cloud solutions can be combined, then, to get the most from each of them and take decisions faster and more reliably.
This is the general workflow, and variations to this scheme can occur, of course. In the remaining time on my talk, I'd like to show you how to work through this workflow with MATLAB, Simulink, and relevant add-ons-- above all, Predictive Maintenance Toolbox. And also, I will show by a case study a specific implementation of a condition-monitoring application.
So concerning data acquisition with MATLAB, it is possible to access data directly from different locations and repositories-- local files, cloud services, databases, and historians-- with support to standard industrial protocols. In case failure data is missing, or it could be necessary to explore a wide set of operating conditions, Simulink and Simscape, the set of libraries for multi-physics modeling, can be employed to build up a natural model of the processes being monitored; refine the model with field data; and also incorporate specific failures suggested, for instance, by domain experts; and then run simulations with also hardware acceleration to produce data corresponding to the widest possible set of operating conditions.
MATLAB and relevant add-ons make it possible to efficiently work with big data, providing all the tools and functionalities to visualize, inspect, sort, filter, and in general, manipulate as desired the data to prepare it for the next steps of the workflow. With this set of tools, domain experts can apply deep background knowledge of the process being studied, optimizing, then, the effort needed to manipulate the data, focusing only on gathering and selecting signals and quantities that are really relevant for the intended purpose.
When data is ready, the step of identifying condition indicators can be completed, exploiting the functionalities for the computation of signal statistics and for feature transformation and selection. In this way, the most discriminating characteristics and available signals can be highlighted and then used to train and validate models. Later on in the talk, we will see how it is possible to use an app or the Predictive Maintenance Toolbox to efficiently calculate and rank features from time series data.
To train models, then, MATLAB first of all guarantees interoperability with other development environments and languages, so that you can easily share and import algorithms and models that you have already available. Moreover, MATLAB offers libraries and apps, graphical user interfaces, to efficiently train and validate machine learning as well as deep learning models and assess their performance for their intended functions.
From the apps, it is indeed possible to access hardware acceleration in order to significantly speed up computation time, and also export trained models, some of them directly into the simulation environment Simulink, and also generate the MATLAB code corresponding to each step completed within the apps for inspection and future reviews. We will see in a bit how the Classification Learner app from the Statistics and Machine Learning Toolbox in MATLAB can be employed to train classification models using supervised machine learning.
Talking about deployment from MATLAB and linked tools, it is possible to deploy all the software developed on the desktop to enterprise as well as cloud systems. Moreover, with automatic code generation tools, you can target with the device the algorithms embedded in the edge devices.
Well, it's time to look closer at the tools and the workflow. So it's time to explore the case study. In the next few slides, we will see how this workflow from data-gathering and preparation till deployment can be completed with MathWorks tools to develop a condition-monitoring application of a packaging robot.
Imagine a flow pack machine whose task is that of continuously pushing or pulling packages on a conveyor belt in a completely automated packaging process. As you know, these machines are made of several mechanical and electrical parts subject to ware and failures. And this kind of assets are equipped with sensors providing measures relevant to the process of controlling and monitoring machine behavior.
For this specific setup, all the control algorithms for this robot were already implemented by automatic generated C code from Simulink on a PLC. The objective, then, of the condition-monitoring application is that of implementing a classification model able to read and measure signals in real time and translate them into info regarding the flow pack machine electrical and mechanical status. This classifier has to be deployed on the same PLC responsible for controlling the machine.
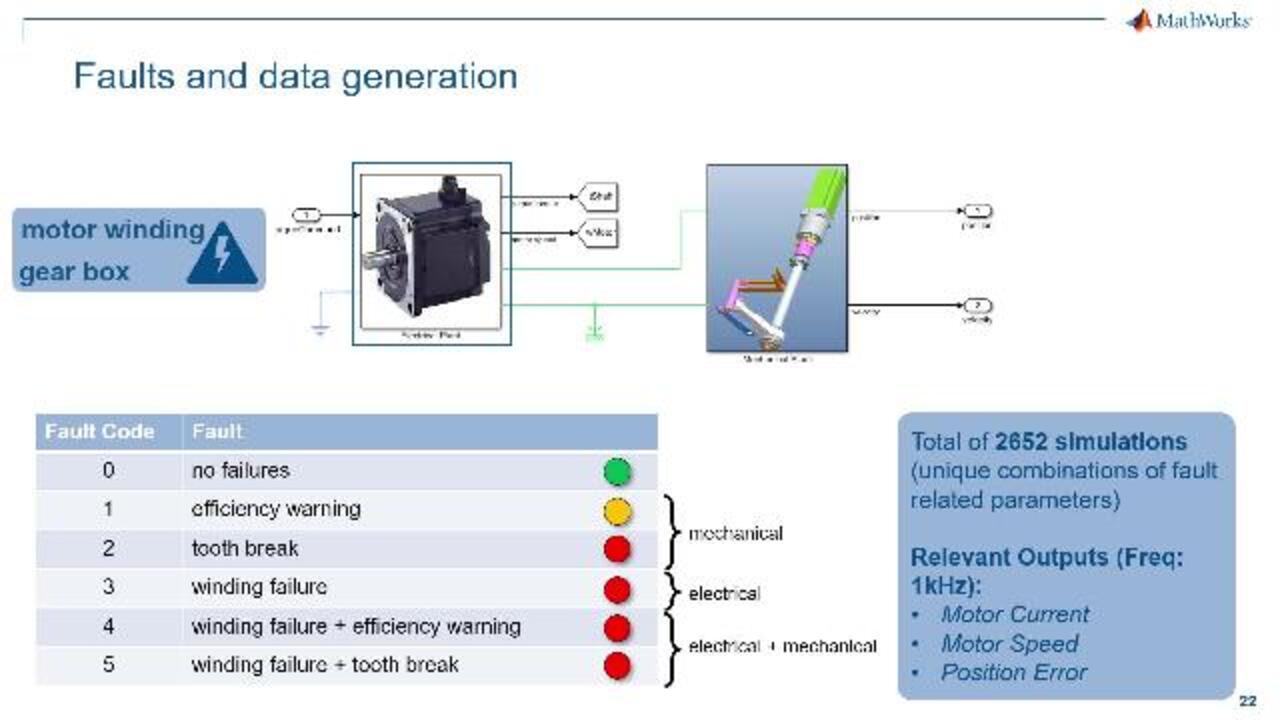
To work on this, I started from the model of the robot. I didn't have any failure data, but I had the model of the robot which was already employed to design and test control algorithms. This high-fidelity model was implemented in Simulink, with also Simscape blocks used to capture dynamics of electrical as well as mechanical components.
Working closely with domain experts and the designers of this machine, I considered the possibility of introducing failures on the motor winding and on the motor gearbox, thus data-mining realistic electrical and mechanical failures with different scales of severity. To explore the wide range of operating conditions corresponding to normal and abnormal functioning, I set up the model for running thousands of simulations, each of them corresponding to a unique combination of fault-related parameters.
Together with the designers of this apparatus, we decided for each simulation run to record the motor current, the motor speed, and the position error as the most relevant signals for the condition-monitoring application development. In fact, I then used this time series, as you will see in a bit, to identify the condition indicators to train the classification model able to inform decisions about maintenance.
And what I did was to arrange data in ensemble data source, specific data structures available in MATLAB, to efficiently organize the time series of each simulation run and prepare signals for all the subsequent processing operations. For the benefit of time on this presentation, I prepared a video to quickly show you the main parts of the work highlighting the process, from feature calculation till deployment, and then also the results achieved.
So here in the movie, you see again the model with the implementation of the electrical and mechanical part of the system made by means of Simscape blocks. So then after using the models to generate over 2,000 simulations and reorganizing and processing data as seen a while ago, I moved to the Diagnostic Feature Designer app from the Predictive Maintenance Toolbox. In this graphical user interface, it is possible to find all the functionalities and tools to visualize data, calculate features in time and frequency domain, and visualize them.
So here in the movie, you are watching how it is possible to import data and visualize them. And now it is possible to extract features, calculate features in time and frequency domain, and visualize them in the visualizing dashboard that is available within the app.
Moreover, in the same environment, it is possible to normalize calculated features and filter them on the basis of mutual correlation, and eventually rank them to identify those that are more useful for classification purposes. So when feature ranking is completed, in this case via the Kruskal-Wallis test, the most significant features are then exported to another app, the Classification Learner app, used to train, test, and validate several classification models.
In this graphical user interface, in fact, it is possible to further reduce features by a principal component analysis and train models, taking also advantage of hardware acceleration. Then to evaluate performance, it is possible to compare the overall accuracy or to get deep into details, looking at confusion matrices and ROC curves to check classifier performance for each predicted class.
Here you have seen how the training process worked. It was accelerated for the sake of time. And here you are watching how it is possible to expect the prediction outcome of each of the models. The final selected model can be then exported and made ready for deployment directly from within the Classification Learner app.
In order to prepare the model for deployment, and all the functions, even for feature calculation, it is possible to plug the algorithm directly into Simulink by means of a MATLAB function block or a classification block directly available in Simulink. Here in this case, I prepared an entry-point function that I then plugged in a MATLAB function block.
So after the function is ready, it can be added to the Simulink model, in which it is also possible to add library blocks from the PLC manufacturer in order to set the code generation environment. And then after doing so, after selecting all the relevant options, it is then possible by means of Embedded Coder to automatically generate C code for the PLC target.
So here you will see the process of generation that, again, has been accelerated for the benefit of time. By means of the Embedded Coder app, in fact, it is possible by clicking on the Build button to automatically generate the C code for the available PLC target.
After the process is completed, you see the final generated code that can be then directly downloaded to the hardware target. And from this point onward, the devised algorithms and models will be available to classify and describe machine status in real time, and then provide useful info for maintenance operations.
So just a quick recap. A model of the system has been used in this case study to generate failure data by thousands of simulations executed in parallel for speeding up computation. Failures injected in the model were the result of the collaboration with the expert responsible for the design and the maintenance of the specific robot. Those experts were the authors of the model that was used to further analyze the system, so that the model became a natural virtual test bench for the evaluation of the widest possible range of operating conditions.
Then standard data structures available in MATLAB have been used to quickly arrange the data and prepare them for the subsequent processing. Feature calculation and ranking was then carried out automatically by means of the Diagnostic Feature Designer app from the Predictive Maintenance Toolbox, and then the most significant features were used to train and test several classification models using the Classification Learner app from the MATLAB Statistics and Machine Learning Toolbox. The final selected classification tree had a 90% overall accuracy in predicting the fault classes.
The final step was that of deploying on the PLC connected to the machine the condition-monitoring algorithm, from the calculation of selected features till classification. To do so, Simulink and Embedded Coder have been employed for automatic C-code generation for the specific selected target. This has made possible to then execute the device, the application, directly on the field, working on real-time data.
So this concludes the case study presentation. And before leaving, I'd like to wrap up with a few considerations on predictive maintenance for industrial processes, and robotics in particular. Well, given the availability of infrastructures and hardware for data acquisition, streaming, and processing, predictive approaches to maintenance represent a great system for optimizing time, resources, and possibly introducing new services. Moreover, we have seen that modeling and simulations are instrumental, not only for testing purposes at each stage of the design, but also for analyzing all possible operating conditions and then generating also failure data where missing.
Additionally, specific domain expertise-- we have seen that is key to deal with the data, select fault-relevant signals, identify the condition indicators, and assess model performance. In this scenario, MATLAB and Simulink represent an end-to-end platform, enabling domain experts with all the tools for the development of any predictive maintenance application, from anomaly detection till estimation of remaining useful life.
I hope my talk was of interest to you, and I look forward to hearing from you in case you have questions or would like to share feedback and comments. I also strongly encourage you to scan the QR code you see on this slide in case you like to get deep into details of predictive maintenance with MATLAB. Enjoy the rest of the workshop.







Seleccione un país/idioma
Seleccione un país/idioma para obtener contenido traducido, si está disponible, y ver eventos y ofertas de productos y servicios locales. Según su ubicación geográfica, recomendamos que seleccione: United States.
También puede seleccionar uno de estos países/idiomas:
América
- América Latina (Español)
- Canada (English)
- United States (English)
Europa
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)