rlSACAgent
Soft actor-critic (SAC) reinforcement learning agent
Description
The soft actor-critic (SAC) algorithm is an actor-critic off-policy method for environments with discrete, continuous, and hybrid action-spaces. The SAC algorithm attempts to learn the stochastic policy that maximizes a combination of the value of the optimal policy and its entropy. The policy entropy is a measure of policy uncertainty given the state. A higher entropy value promotes more exploration. Maximizing both the reward and the entropy balances exploration and exploitation of the environment. A soft actor-critic agent uses two critics to estimate the value of the optimal policy, while also featuring target critics and an experience buffer. SAC agents support offline training (training from saved data, without an environment), as well as training with evolutionary strategies.
Note
Soft actor-critic agents with a hybrid action space do not support training with an evolutionary strategy. Also, they cannot be used to build model based agents. Finally, while you can train offline (from existing data) any SAC agent, only SAC agents with continuous action space support batch data regularizer options.
For more information, see Soft Actor-Critic (SAC) Agent. For more information on the different types of reinforcement learning agents, see Reinforcement Learning Agents.
Creation
Syntax
Description
Create Agent from Observation and Action Specifications
agent = rlSACAgent(observationInfo,actionInfo)observationInfo and action specification
actionInfo. The ObservationInfo and
ActionInfo properties of agent are set to
the observationInfo and actionInfo input
arguments, respectively.
agent = rlSACAgent(observationInfo,actionInfo,initOptions)initOptions).
Create Agent from Actor and Critic
Specify Agent Options
agent = rlSACAgent(___,agentOptions)AgentOptions property for any of the previous syntaxes.
Input Arguments
Properties
Object Functions
train | Train reinforcement learning agents within a specified environment |
sim | Simulate trained reinforcement learning agents within specified environment |
getAction | Obtain action from agent, actor, or policy object given environment observations |
getActor | Extract actor from reinforcement learning agent |
setActor | Set actor of reinforcement learning agent |
getCritic | Extract critic from reinforcement learning agent |
setCritic | Set critic of reinforcement learning agent |
generatePolicyFunction | Generate MATLAB function that evaluates policy of an agent or policy object |
Examples
Create environment and obtain observation and action specifications. For this example, load the environment used in the example Compare DDPG Agent to LQR Controller. The observation from the environment is a vector containing the position and velocity of a mass. The action is a scalar representing a force, applied to the mass, ranging continuously from -2 to 2 Newton.
env = rlPredefinedEnv("DoubleIntegrator-Continuous");
obsInfo = getObservationInfo(env);
actInfo = getActionInfo(env);The agent creation function initializes the actor and critic networks randomly. Ensure reproducibility of the section by fixing the seed of the random generator.
rng(0)
Create a SAC agent from the environment observation and action specifications. Because actInfo is an rlNumericSpec object, rlSACAgent creates an agent with a continuous action space. When actInfo is an rlFiniteSetSpec object, rlSACAgent creates an agent with a discrete action space.
agent = rlSACAgent(obsInfo,actInfo);
To check your agent, use the getAction function to return the action batch from a batch of 5 random observations.
obs = rand([obsInfo(1).Dimension 5]);
act = getAction(agent,{obs});Display the third element of the batch.
act{1}(3)ans = -0.0042
You can now test and train the agent within the environment. You can also use getActor and getCritic to extract the actor and critic, respectively, and getModel to extract the approximator model (by default a deep neural network) from the actor or critic.
Create an environment with a discrete action space and obtain its observation and action specifications. For this example, load the environment used in the example Train PG Agent with Custom Actor and Baseline Networks to Control Discrete Double Integrator. The observation from the environment is a vector containing the position and velocity of a mass. The action is a scalar representing a force, applied to the mass, ranging continuously from -2 to 2 Newton.
env = rlPredefinedEnv("DoubleIntegrator-Discrete");
obsInfo = getObservationInfo(env);
actInfo = getActionInfo(env);Create an agent initialization option object, specifying that each hidden fully connected layer in the network must have 128 neurons.
initOpts = rlAgentInitializationOptions(NumHiddenUnit=128);
The agent creation function initializes the actor and critic networks randomly. Ensure reproducibility of the section by fixing the seed of the random generator.
rng(0)
Create a SAC agent from the environment observation and action specifications using the initialization options. Because actInfo is an rlFiniteSetSpec object, rlSACAgent creates an agent with a discrete action space. When actInfo is an rlNumericSpec object, rlSACAgent creates an agent with a continuous action space.
agent = rlSACAgent(obsInfo,actInfo,initOpts);
Extract the deep neural network from the actor.
actorNet = getModel(getActor(agent));
Extract the deep neural networks from the two critics. Note that getModel(critics) only returns the first critic network.
critics = getCritic(agent); criticNet1 = getModel(critics(1)); criticNet2 = getModel(critics(2));
Display the layers of the first critic network, and verify that each hidden fully connected layer has 128 neurons.
criticNet1.Layers
ans =
6×1 Layer array with layers:
1 'input_1' Feature Input 2 features
2 'fc_1' Fully Connected Fully connected layer with output size 128
3 'relu_body' ReLU ReLU
4 'fc_body' Fully Connected Fully connected layer with output size 128
5 'body_output' ReLU ReLU
6 'output' Fully Connected Fully connected layer with output size 3
Plot the networks of the actor and of the second critic, and display the number of weights.
plot(actorNet)
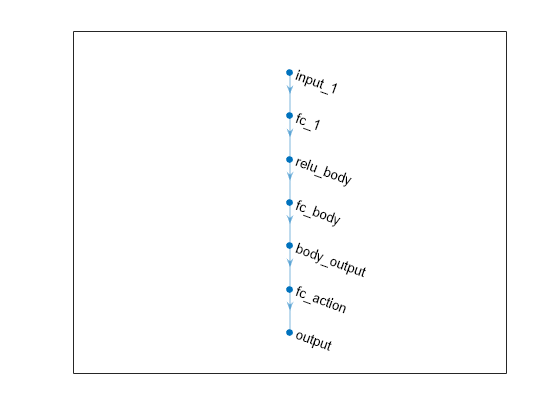
summary(actorNet)
Initialized: true
Number of learnables: 17.3k
Inputs:
1 'input_1' 2 features
plot(criticNet2)
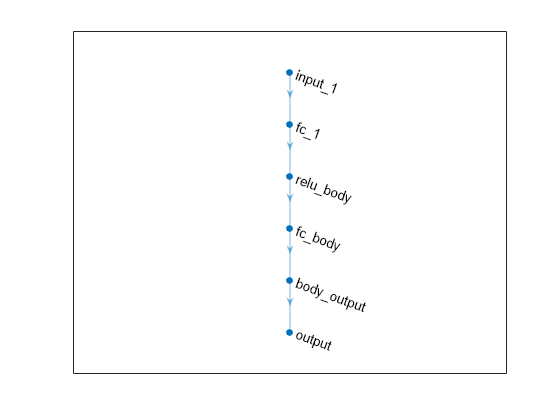
summary(criticNet2)
Initialized: true
Number of learnables: 17.3k
Inputs:
1 'input_1' 2 features
To check your agent, use the getAction function to return the action from a batch of 8 random observations.
act = getAction(agent,{rand([obsInfo(1).Dimension 8])});Display the seventh element in the batch.
act{1}(7)ans = -2
You can now test and train the agent within the environment.
Create an environment and obtain its observation and action specifications. For this example, load the environment used in the example Compare DDPG Agent to LQR Controller. The observation from the environment is a vector containing the position and velocity of a mass. The action is a scalar representing a force, applied to the mass, ranging continuously from -2 to 2 Newton.
env = rlPredefinedEnv("DoubleIntegrator-Continuous");
obsInfo = getObservationInfo(env);
actInfo = getActionInfo(env);Create an agent initialization option object, specifying that each hidden fully connected layer in the network must have 128 neurons.
initOpts = rlAgentInitializationOptions(NumHiddenUnit=128);
The agent creation function initializes the actor and critic networks randomly. Ensure reproducibility of the section by fixing the seed of the random generator.
rng(0)
Create a SAC agent from the environment observation and action specifications using the initialization options. Because actInfo is an rlNumericSpec object, rlSACAgent creates an agent with a continuous action space. When actInfo is an rlFiniteSetSpec object, rlSACAgent creates an agent with a discrete action space.
agent = rlSACAgent(obsInfo,actInfo,initOpts);
Extract the deep neural network from the actor.
actorNet = getModel(getActor(agent));
Extract the deep neural networks from the two critics. Note that getModel(critics) only returns the first critic network.
critics = getCritic(agent); criticNet1 = getModel(critics(1)); criticNet2 = getModel(critics(2));
Display the layers of the first critic network, and verify that each hidden fully connected layer has 128 neurons.
criticNet1.Layers
ans =
9×1 Layer array with layers:
1 'concat' Concatenation Concatenation of 2 inputs along dimension 1
2 'relu_body' ReLU ReLU
3 'fc_body' Fully Connected Fully connected layer with output size 128
4 'body_output' ReLU ReLU
5 'input_1' Feature Input 2 features
6 'fc_1' Fully Connected Fully connected layer with output size 128
7 'input_2' Feature Input 1 features
8 'fc_2' Fully Connected Fully connected layer with output size 128
9 'output' Fully Connected Fully connected layer with output size 1
Plot the networks of the actor and of the second critic, and display the number of weights.
plot(actorNet)

summary(actorNet)
Initialized: true
Number of learnables: 17.2k
Inputs:
1 'input_1' 2 features
plot(criticNet2)
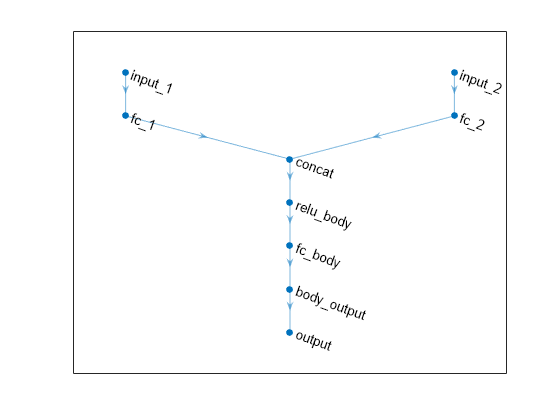
summary(criticNet2)
Initialized: true
Number of learnables: 33.7k
Inputs:
1 'input_1' 2 features
2 'input_2' 1 features
To check your agent, use the getAction function to return the action from a batch of 5 random observations.
obs = rand([obsInfo(1).Dimension 5]);
act = getAction(agent,{obs})act = 1×1 cell array
{1×1×5 double}
Display the third element of the batch.
act{1}(3)ans = 0.0153
You can now test and train the agent within the environment.
Create an environment and obtain observation and action specifications. For this example, load the environment used in the example Compare DDPG Agent to LQR Controller. The observation from the environment is a vector containing the position and velocity of a mass. The action is a scalar representing a force, applied to the mass, ranging continuously from -2 to 2 Newton.
env = rlPredefinedEnv("DoubleIntegrator-Continuous");
obsInfo = getObservationInfo(env);
actInfo = getActionInfo(env);Define bounds on the action. The SAC agent automatically uses these values to internally scale the distribution and bound the action properly.
actInfo.LowerLimit=-2; actInfo.UpperLimit=2;
SAC agents use two Q-value function critics. A Q-value function critic takes the current observation and an action as inputs and returns a single scalar as output (the estimated discounted cumulative long-term reward for taking the action from the state corresponding to the current observation, and following the policy thereafter).
To model the parameterized Q-value function within the critics, use a neural network with two input layers (one for the observation channel, as specified by obsInfo, and the other for the action channel, as specified by actInfo) and one output layer (which returns the scalar value). Note that prod(obsInfo.Dimension) and prod(actInfo.Dimension) return the number of dimensions of the observation and action spaces, respectively, regardless of whether they are arranged as row vectors, column vectors, or matrices.
Define each network path as an array of layer objects. Assign names to the input and output layers of each path. These names allow you to connect the paths and then later explicitly associate the network input layers with the appropriate environment channel.
% Observation path obsPath = [ featureInputLayer(prod(obsInfo.Dimension),Name="obsInLyr") fullyConnectedLayer(32) reluLayer fullyConnectedLayer(16,Name="obsPathOutLyr") ]; % Action path actPath = [ featureInputLayer(prod(actInfo.Dimension),Name="actInLyr") fullyConnectedLayer(32) reluLayer fullyConnectedLayer(16,Name="actPathOutLyr") ]; % Common path commonPath = [ concatenationLayer(1,2,Name="concat") reluLayer fullyConnectedLayer(1) ]; % Assemble dlnetwork object. criticNet = dlnetwork; criticNet = addLayers(criticNet,obsPath); criticNet = addLayers(criticNet,actPath); criticNet = addLayers(criticNet,commonPath); % Connect layers criticNet = connectLayers(criticNet,"obsPathOutLyr","concat/in1"); criticNet = connectLayers(criticNet,"actPathOutLyr","concat/in2");
Plot the network.
plot(criticNet)
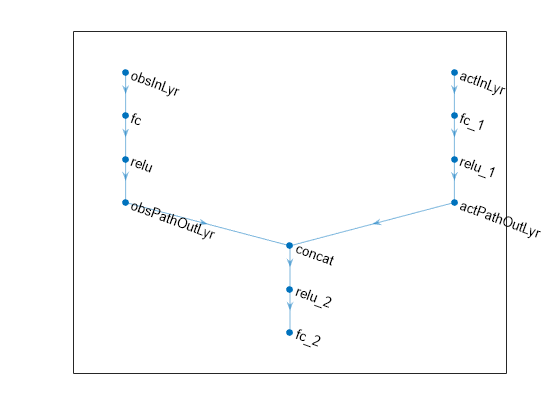
To initialize the network weights differently for the two critics, create two different dlnetwork objects. You must do this because the agent constructor function does not accept two identical critics.
criticNet1 = initialize(criticNet); criticNet2 = initialize(criticNet);
Display the number of weights.
summary(criticNet1)
Initialized: true
Number of learnables: 1.2k
Inputs:
1 'obsInLyr' 2 features
2 'actInLyr' 1 features
Create the two critics using the two networks with different weights and the names of the input layers. Alternatively, if you use exactly the same network with the same weights, you must explicitly initialize the network each time (to make sure weights are initialized differently) before passing it to rlQValueFunction. To do so, use initialize.
critic1 = rlQValueFunction(criticNet1,obsInfo,actInfo, ... ActionInputNames="actInLyr", ... ObservationInputNames="obsInLyr"); critic2 = rlQValueFunction(criticNet2,obsInfo,actInfo, ... ActionInputNames="actInLyr", ... ObservationInputNames="obsInLyr");
For more information about value function approximators, see rlQValueFunction.
Check the critics with a batch of 5 random observation and action inputs.
robs = rand([obsInfo.Dimension 5]);
ract = rand([actInfo.Dimension 5]);
getValue(critic1,{robs},{ract})ans = 1×5 single row vector
-0.1228 -0.0543 -0.0087 -0.0883 -0.2600
getValue(critic2,{robs},{ract})ans = 1×5 single row vector
-0.3008 -0.3237 -0.1304 -0.2995 -0.3389
SAC agents use a parameterized stochastic policy, which for continuous action spaces is implemented by a continuous Gaussian actor. This actor takes an observation as input and returns as output a random action sampled from a Gaussian probability distribution.
To approximate the mean values and standard deviations of the Gaussian distribution, you must use a neural network with two output layers, each having as many elements as the dimension of the action space. One output layer must return a vector containing the mean values for each action dimension. The other must return a vector containing the standard deviation for each action dimension.
The SAC agent automatically reads the action range from the UpperLimit and LowerLimit properties of actInfo (which is used to create the actor), and then internally scales the distribution and bounds the action.
Therefore, do not add a tanhLayer as the last nonlinear layer in the mean output path. If you bound the mean value output directly (for example by adding a tanhLayer right before the output), the agent does not calculate the entropy of the probability density distribution correctly. Note that you must still add a softplus or ReLU layer to the standard deviations path to enforce non-negativity. For more information, see Soft Actor-Critic (SAC) Agent.
Define each network path as an array of layer objects, and assign names to the input and output layers of each path.
% Define common input path. commonPath = [ featureInputLayer(prod(obsInfo.Dimension),Name="obsInLyr") fullyConnectedLayer(32) reluLayer(Name="comPthOutLyr") ]; % Define path for mean value. meanPath = [ fullyConnectedLayer(32,Name="meanPthInLyr") reluLayer fullyConnectedLayer(16) reluLayer fullyConnectedLayer(prod(actInfo.Dimension),Name="meanOutLyr") ]; % Define path for standard deviation. stdPath = [ fullyConnectedLayer(32,Name="stdPthInLyr") reluLayer fullyConnectedLayer(16) reluLayer fullyConnectedLayer(prod(actInfo.Dimension)) softplusLayer(Name="stdOutLyr") ]; % Assemble dlnetwork object. actorNet = dlnetwork; actorNet = addLayers(actorNet,commonPath); actorNet = addLayers(actorNet,meanPath); actorNet = addLayers(actorNet,stdPath); % Connect layers. actorNet = connectLayers(actorNet,"comPthOutLyr","meanPthInLyr/in"); actorNet = connectLayers(actorNet,"comPthOutLyr","stdPthInLyr/in");
Plot the network.
plot(actorNet)
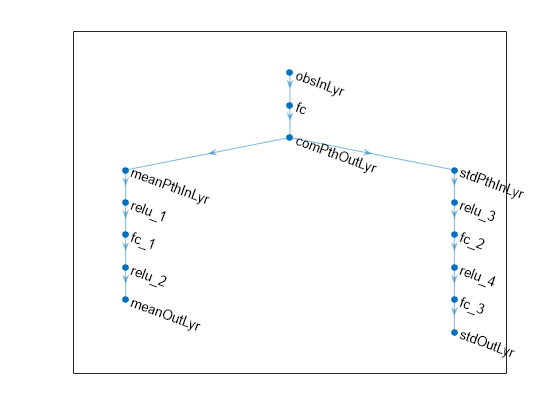
Initialize network and display the number of weights.
actorNet = initialize(actorNet); summary(actorNet)
Initialized: true
Number of learnables: 3.3k
Inputs:
1 'obsInLyr' 2 features
Create the actor using actorNet, the observation and action specification objects, and the names of the input and output layers.
actor = rlContinuousGaussianActor(actorNet, obsInfo, actInfo, ... ActionMeanOutputNames="meanOutLyr", ... ActionStandardDeviationOutputNames="stdOutLyr", ... ObservationInputNames="obsInLyr");
For more information about continuous Gaussian actors approximators, see rlContinuousGaussianActor.
Check your actor with a batch of 5 random input observations.
robs = rand([obsInfo.Dimension 5]);
act = getAction(actor,{robs})act = 1×1 cell array
{1×1×5 single}
Display the fourth element of the batch.
act{1}(4)ans = single
0.3759
Specify training options for the critics.
criticOptions = rlOptimizerOptions( ... Optimizer="adam", ... LearnRate=1e-3, ... GradientThreshold=1, ... L2RegularizationFactor=2e-4);
Specify training options for the actor.
actorOptions = rlOptimizerOptions( ... Optimizer="adam", ... LearnRate=1e-3, ... GradientThreshold=1, ... L2RegularizationFactor=1e-5);
Specify agent options, including training options for actor and critics.
agentOptions = rlSACAgentOptions; agentOptions.SampleTime = env.Ts; agentOptions.DiscountFactor = 0.99; agentOptions.TargetSmoothFactor = 1e-3; agentOptions.ExperienceBufferLength = 1e6; agentOptions.MiniBatchSize = 32; agentOptions.CriticOptimizerOptions = criticOptions; agentOptions.ActorOptimizerOptions = actorOptions;
Create the SAC agent using actor, critics, and options.
agent = rlSACAgent(actor,[critic1 critic2],agentOptions)
agent =
rlSACAgent with properties:
ExperienceBuffer: [1×1 rl.replay.rlReplayMemory]
AgentOptions: [1×1 rl.option.rlSACAgentOptions]
UseExplorationPolicy: 0
ObservationInfo: [1×1 rl.util.rlNumericSpec]
ActionInfo: [1×1 rl.util.rlNumericSpec]
SampleTime: 0.1000
UseGPUForLearning: 0
To check your agent, use the getAction function to return the action from a batch of 10 random observations.
obs = rand([obsInfo(1).Dimension 10]);
act = getAction(agent,{obs})act = 1×1 cell array
{1×1×10 double}
Display the seventh element of the batch.
act{1}(7)ans = 0.0336
You can now test and train the agent within the environment.
For this example, load the environment used in the example Compare DDPG Agent to LQR Controller. The observation from the environment is a vector containing the position and velocity of a mass. The action is a scalar representing a force, applied to the mass, ranging continuously from -2 to 2 Newton.
env = rlPredefinedEnv("DoubleIntegrator-Continuous");
obsInfo = getObservationInfo(env);
actInfo = getActionInfo(env);SAC agents use two Q-value function critics. To model the parameterized Q-value function within the critics, use a recurrent neural network, which must have two input layers one output layer.
Define each network path as an array of layer objects, and assign names to the input and output layers of each path. To create a recurrent neural network, use sequenceInputLayer as the input layer and include an lstmLayer as one of the other network layers.
% Define observation path. obsPath = [ sequenceInputLayer(prod(obsInfo.Dimension),Name="obsInLyr") fullyConnectedLayer(40) reluLayer fullyConnectedLayer(30,Name="obsOutLyr") ]; % Define action path. actPath = [ sequenceInputLayer(prod(actInfo.Dimension),Name="actInLyr") fullyConnectedLayer(30,Name="actOutLyr") ]; % Define common path. commonPath = [ concatenationLayer(1,2,Name="cat") lstmLayer(16) reluLayer fullyConnectedLayer(1) ]; % Create dlnetwork object and add layers. criticNet = dlnetwork; criticNet = addLayers(criticNet,obsPath); criticNet = addLayers(criticNet,actPath); criticNet = addLayers(criticNet,commonPath); % Connect paths. criticNet = connectLayers(criticNet,"obsOutLyr","cat/in1"); criticNet = connectLayers(criticNet,"actOutLyr","cat/in2");
To initialize the network weights differently for the two critics, create two different dlnetwork objects. You must do this because the agent constructor function does not accept two identical critics.
criticNet1 = initialize(criticNet); criticNet2 = initialize(criticNet);
Display the number of weights.
summary(criticNet1)
Initialized: true
Number of learnables: 6.4k
Inputs:
1 'obsInLyr' Sequence input with 2 channels
2 'actInLyr' Sequence input with 1 channels
Create the two critics using the two networks with different weights. Use the same network structure for both critics. The SAC agent initializes the two networks using different default parameters.
critic1 = rlQValueFunction(criticNet1,obsInfo,actInfo); critic2 = rlQValueFunction(criticNet2,obsInfo,actInfo);
Check the critics with a random observation and action input.
getValue(critic1,{rand(obsInfo.Dimension)},{rand(actInfo.Dimension)})ans = single
-0.0508
getValue(critic2,{rand(obsInfo.Dimension)},{rand(actInfo.Dimension)})ans = single
0.0762
Because the critic has a recurrent network, the actor must have a recurrent network too.
Do not add a tanhLayer or scalingLayer in the mean output path. The SAC agent internally transforms the unbounded Gaussian distribution to the bounded distribution to compute the probability density function and entropy properly. However, add a softplus or ReLU layer to the standard deviations path to enforce nonnegativity,
Define each network path as an array of layer objects and specify a name for the input and output layers, so you can later explicitly associate them with the appropriate channel.
% Define common path. commonPath = [ sequenceInputLayer(prod(obsInfo.Dimension),Name="obsInLyr") fullyConnectedLayer(400) lstmLayer(8) reluLayer(Name="CommonOutLyr") ]; % Define mean value path. meanPath = [ fullyConnectedLayer(300,Name="MeanInLyr") reluLayer fullyConnectedLayer(prod(actInfo.Dimension),Name="MeanOutLyr") ]; % Define standard deviation value path. stdPath = [ fullyConnectedLayer(300,Name="StdInLyr") reluLayer fullyConnectedLayer(prod(actInfo.Dimension)) softplusLayer(Name="StdOutLyr") ]; % Create dlnetwork object and add layers. actorNet = dlnetwork; actorNet = addLayers(actorNet,commonPath); actorNet = addLayers(actorNet,meanPath); actorNet = addLayers(actorNet,stdPath); % Connect layers. actorNet = connectLayers(actorNet,"CommonOutLyr","MeanInLyr/in"); actorNet = connectLayers(actorNet,"CommonOutLyr","StdInLyr/in"); % Initialize network and display the number of weights. actorNet = initialize(actorNet); summary(actorNet)
Initialized: true
Number of learnables: 20.3k
Inputs:
1 'obsInLyr' Sequence input with 2 channels
Create the actor using actorNet, the observation and action specification objects, and the names of the input and output layers.
actor = rlContinuousGaussianActor(actorNet, obsInfo, actInfo, ... ActionMeanOutputNames="MeanOutLyr", ... ActionStandardDeviationOutputNames="StdOutLyr", ... ObservationInputNames="obsInLyr");
Check your actor with a random input observation.
getAction(actor,{rand(obsInfo.Dimension)})ans = 1×1 cell array
{[-0.6304]}
Specify training options for the critics. For more information, see rlOptimizerOptions.
criticOptions = rlOptimizerOptions( ... Optimizer = "adam", LearnRate = 1e-3, ... GradientThreshold = 1, L2RegularizationFactor = 2e-4);
Specify training options for the actor.
actorOptions = rlOptimizerOptions( ... Optimizer = "adam", LearnRate = 1e-3, ... GradientThreshold = 1, L2RegularizationFactor = 1e-5);
Specify agent options. For more information, see rlSACAgentOptions.
agentOptions = rlSACAgentOptions;
To ensure that if you use the agent in an RL Agent block the block executes at the same sample time as the environment, set the agent sample time equal to the environment sample time. This also ensures that the time interval between consecutive elements in the returned experience is env.Ts.
agentOptions.SampleTime = env.Ts;
A large discount factor value of 0.99 promotes shorter term rewards.
agentOptions.DiscountFactor = 0.9;
Specify a larger smooth factor to promote a faster target critic update, possibly at the expense of noisier gradient estimate.
agentOptions.TargetSmoothFactor = 2e-3;
Specify a capacity of 1e6 for the experience buffer to store a diverse set of experiences.
agentOptions.ExperienceBufferLength = 1e6;
Use mini-batches of 256 experiences. Smaller mini-batches are computationally efficient but might introduce variance in training. By contrast, larger batch sizes can make the training stable but require higher memory.
agentOptions.MiniBatchSize = 32;
To use a recurrent neural network, you must specify a SequenceLength greater than 1.
agentOptions.SequenceLength = 32;
Include the actor and critic options in the agent options object.
agentOptions.CriticOptimizerOptions = criticOptions; agentOptions.ActorOptimizerOptions = actorOptions;
Create the SAC agent using actor, critics, and option objects.
agent = rlSACAgent(actor,[critic1 critic2],agentOptions);
To check your agent, use the getAction function to return the action from a random observation.
getAction(agent,{rand(obsInfo.Dimension)})ans = 1×1 cell array
{[-0.0085]}
To evaluate the agent using sequential observations, use the sequence length (time) dimension. For example, obtain actions for a sequence of 9 observations.
[action,state] = getAction(agent, ...
{rand([obsInfo.Dimension 1 9])});Display the action corresponding to the seventh element of the observation.
action = action{1};
action(1,1,1,7)ans = -0.0343
You can now test and train the agent within the environment.
Version History
Introduced in R2020b
See Also
Apps
Functions
getAction|getActor|getCritic|getModel|generatePolicyFunction|generatePolicyBlock|getActionInfo|getObservationInfo
Objects
rlSACAgentOptions|rlAgentInitializationOptions|rlQValueFunction|rlVectorQValueFunction|rlContinuousGaussianActor|rlHybridStochasticActor|rlDDPGAgent|rlTD3Agent|rlACAgent|rlPPOAgent