ttest
Prueba t de una muestra y muestras emparejadas
Sintaxis
Descripción
h = ttest(x)x proceden de una distribución normal con una media igual a 0 y una varianza desconocida, usando la prueba t de una muestra. La hipótesis alternativa es que la distribución de la población no tiene una media igual a 0. El resultado h es 1 si la prueba rechaza la hipótesis nula al nivel de significación del 5%, y 0 en el caso contrario.
h = ttest(x,y,Name,Value)
h = ttest(x,m,Name,Value)
Ejemplos
Cargue los datos de muestra. Cree un vector que contenga la tercera columna de los datos sobre la rentabilidad de las acciones.
load stockreturns
x = stocks(:,3);Pruebe la hipótesis nula de que los datos de muestra proceden de una población con una media igual a 0.
[h,p,ci,stats] = ttest(x)
h = 1
p = 0.0106
ci = 2×1
-0.7357
-0.0997
stats = struct with fields:
tstat: -2.6065
df: 99
sd: 1.6027
El valor devuelto de h = 1 indica que ttest rechaza la hipótesis nula al nivel de significación del 5%.
Cargue los datos de muestra. Cree un vector que contenga la tercera columna de los datos sobre la rentabilidad de las acciones.
load stockreturns
x = stocks(:,3);Pruebe la hipótesis nula de que los datos de muestra proceden de una población con una media igual a cero al nivel de significación del 1%.
h = ttest(x,0,'Alpha',0.01)h = 0
El valor devuelto h = 0 indica que ttest no rechaza la hipótesis nula al nivel de significación del 1%.
Cargue los datos de muestra. Cree vectores que contengan la primera y la segunda columna de la matriz de datos para representar las notas de unos alumnos en dos exámenes.
load examgrades
x = grades(:,1);
y = grades(:,2);Pruebe la hipótesis nula de que la diferencia entre pares entre los vectores de datos x e y tiene una media igual a 0.
[h,p] = ttest(x,y)
h = 0
p = 0.9805
El valor devuelto de h = 0 indica que ttest no rechaza la hipótesis nula al nivel de significación predeterminado del 5%.
Cargue los datos de muestra. Cree vectores que contengan la primera y la segunda columna de la matriz de datos para representar las notas de unos alumnos en dos exámenes.
load examgrades
x = grades(:,1);
y = grades(:,2);Pruebe la hipótesis nula de que la diferencia entre pares entre los vectores de datos x e y tiene una media igual a 0 al nivel de significación del 1%.
[h,p] = ttest(x,y,'Alpha',0.01)h = 0
p = 0.9805
El valor devuelto de h = 0 indica que ttest no rechaza la hipótesis nula al nivel de significación del 1%.
Cargue los datos de muestra. Cree un vector que contenga la primera columna de los datos de las notas de los alumnos en un examen.
load examgrades
x = grades(:,1);Pruebe la hipótesis nula de que los datos de muestra proceden de una distribución con una media de m = 75.
h = ttest(x,75)
h = 0
El valor devuelto de h = 0 indica que ttest no rechaza la hipótesis nula al nivel de significación del 5%.
Cargue los datos de muestra. Cree un vector que contenga la primera columna de los datos de las notas de los alumnos en un examen.
load examgrades
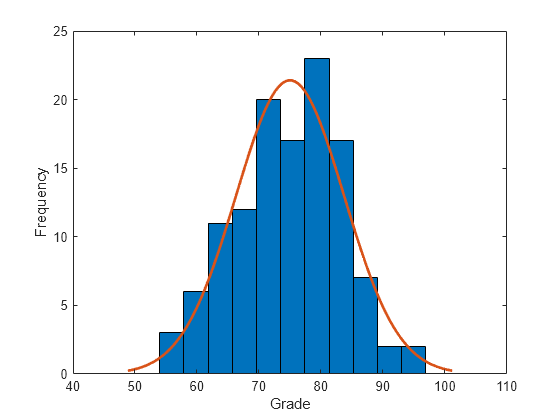
x = grades(:,1);Represente un histograma de los datos de las notas de los exámenes y ajuste una función de densidad normal.
histfit(x) xlabel("Grade") ylabel("Frequency")
Utilice una prueba t de cola derecha para probar la hipótesis nula de que los datos proceden de una población con una media igual a 65, frente a la alternativa de que la media es mayor que 65.
[h,~,~,stats] = ttest(x,65,"Tail","right")
h = 1
stats = struct with fields:
tstat: 12.5726
df: 119
sd: 8.7202
El valor devuelto de h = 1 indica que ttest rechaza la hipótesis nula al nivel de significación predeterminado del 5% en favor de la hipótesis alternativa de que los datos proceden de una población con una media mayor que 65.
Represente la distribución t de Student correspondiente, la estadística t devuelta y el valor de t crítico. Calcule el valor de t crítico para el nivel de confianza predeterminado del 95% usando tinv.
nu = stats.df; k = linspace(-15,15,300); tdistpdf = tpdf(k,nu); tval = stats.tstat
tval = 12.5726
tvalpdf = tpdf(tval,nu); tcrit = tinv(0.95,nu)
tcrit = 1.6578
plot(k,tdistpdf) hold on scatter(tval,tvalpdf,"filled") xline(tcrit,"--") legend(["Student's t pdf", "t-Statistic", ... "Critical Cutoff"])

El punto naranja representa la estadística t y se ubica a la derecha de la línea negra discontinua que representa el valor de t crítico.
Argumentos de entrada
Argumentos de par nombre-valor
Argumentos de salida
Más acerca de
Sugerencias
Use
sampsizepwrpara calcular:el tamaño de la muestra que corresponde a los valores especificados de los parámetros y las potencias;
la potencia alcanzada para un tamaño de muestra en particular, dado el valor real de los parámetros;
el valor detectable de los parámetros con el tamaño de muestra y la potencia especificados.
Capacidades ampliadas
Historial de versiones
Introducido antes de R2006a
Consulte también
ztest | ttest2 | sampsizepwr