classifySound
Classify sounds in audio signal
Syntax
Description
sounds = classifySound(audioIn,fs,Name,Value)Name,Value pair arguments.
Example: sounds = classifySound(audioIn,fs,'SpecificityLevel','low')
classifies sounds using low specificity.
[
also returns time stamps associated with each detected sound.sounds,timestamps] = classifySound(___)
[
also returns a table containing result details.sounds,timestamps,resultsTable] = classifySound(___)
classifySound(___) with no output arguments creates a
word cloud of the identified sounds in the audio signal.
This function requires both Audio Toolbox™ and Deep Learning Toolbox™.
Examples
Download and unzip the Audio Toolbox™ support for YAMNet.
If the Audio Toolbox support for YAMNet is not installed, then the first call to the function provides a link to the download location. To download the model, click the link. Unzip the file to a location on the MATLAB® path.
Alternatively, execute the following commands to download and unzip the YAMNet model to your temporary directory.
downloadFolder = fullfile(tempdir,'YAMNetDownload'); loc = websave(downloadFolder,'https://ssd.mathworks.com/supportfiles/audio/yamnet.zip'); YAMNetLocation = tempdir; unzip(loc,YAMNetLocation) addpath(fullfile(YAMNetLocation,'yamnet'))
Generate 1 second of pink noise assuming a 16 kHz sample rate.
fs = 16e3; x = pinknoise(fs);
Call classifySound with the pink noise signal and the sample rate.
identifiedSound = classifySound(x,fs)
identifiedSound = "Pink noise"
Read in an audio signal. Call classifySound to return the detected sounds and corresponding time stamps.
[audioIn,fs] = audioread('multipleSounds-16-16-mono-18secs.wav');
[sounds,timeStamps] = classifySound(audioIn,fs);Plot the audio signal and label the detected sound regions.
t = (0:numel(audioIn)-1)/fs; plot(t,audioIn) xlabel('Time (s)') axis([t(1),t(end),-1,1]) textHeight = 1.1; for idx = 1:numel(sounds) patch([timeStamps(idx,1),timeStamps(idx,1),timeStamps(idx,2),timeStamps(idx,2)], ... [-1,1,1,-1], ... [0.3010 0.7450 0.9330], ... 'FaceAlpha',0.2); text(timeStamps(idx,1),textHeight+0.05*(-1)^idx,sounds(idx)) end
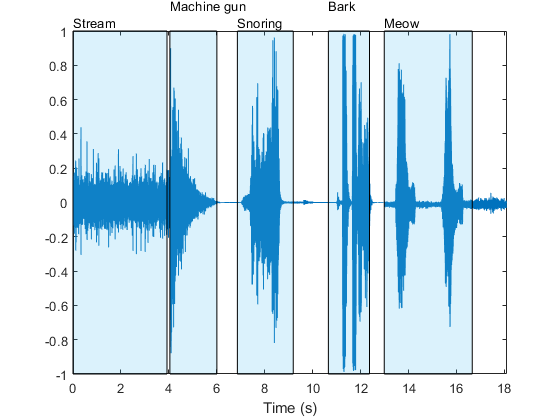
Select a region and listen only to the selected region.
sampleStamps = floor(timeStamps*fs)+1; soundEvent =3; isolatedSoundEvent = audioIn(sampleStamps(soundEvent,1):sampleStamps(soundEvent,2)); sound(isolatedSoundEvent,fs); display('Detected Sound = ' + sounds(soundEvent))
"Detected Sound = Snoring"
Read in an audio signal containing multiple different sound events.
[audioIn,fs] = audioread('multipleSounds-16-16-mono-18secs.wav');Call classifySound with the audio signal and sample rate.
[sounds,~,soundTable] = classifySound(audioIn,fs);
The sounds string array contains the most likely sound event in each region.
sounds
sounds = 1×5 string array
"Stream" "Machine gun" "Snoring" "Bark" "Meow"
The soundTable contains detailed information regarding the sounds detected in each region, including score means and maximums over the analyzed signal.
soundTable
soundTable=5×2 table
0,3.9200 4×3 table
4.0425,6.0025 3×3 table
6.8600,9.1875 2×3 table
10.6575,12.3725 4×3 table
12.9850,16.6600 4×3 table
View the last detected region.
soundTable.Results{end}ans=4×3 table
"Animal" 0.7951 0.9994
"Domestic animals, pets" 0.8024 0.9983
"Cat" 0.8048 0.9905
"Meow" 0.6342 0.9018
Call classifySound again. This time, set IncludedSounds to Animal so that the function retains only regions in which the Animal sound class is detected.
[sounds,timeStamps,soundTable] = classifySound(audioIn,fs, ... 'IncludedSounds','Animal');
The sounds array only returns sounds specified as included sounds. The sounds array now contains two instances of Animal that correspond to the regions declared as Bark and Meow previously.
sounds
sounds = 1×2 string array
"Animal" "Animal"
The sound table only includes regions where the specified sound classes were detected.
soundTable
soundTable=2×2 table
10.6575,12.3725 4×3 table
12.9850,16.6600 4×3 table
View the last detected region in soundTable. The results table still includes statistics for all detected sounds in the region.
soundTable.Results{end}ans=4×3 table
"Animal" 0.7951 0.9994
"Domestic animals, pets" 0.8024 0.9983
"Cat" 0.8048 0.9905
"Meow" 0.6342 0.9018
To explore which sound classes are supported by classifySound, use yamnetGraph.
Read in an audio signal and call classifySound to inspect the most likely sounds arranged in chronological order of detection.
[audioIn,fs] = audioread("multipleSounds-16-16-mono-18secs.wav");
sounds = classifySound(audioIn,fs)sounds = 1×5 string array
"Stream" "Machine gun" "Snoring" "Bark" "Meow"
Call classifySound again and set ExcludedSounds to Meow to exclude the sound Meow from the results. The segment previously classified as Meow is now classified as Cat, which is its immediate predecessor in the AudioSet ontology.
sounds = classifySound(audioIn,fs,"ExcludedSounds","Meow")
sounds = 1×5 string array
"Stream" "Machine gun" "Snoring" "Bark" "Cat"
Call classifySound again, and set ExcludedSounds to Cat. When you exclude a sound, all successors are also excluded. This means that excluding the sound Cat also excludes the sound Meow. The segment originally classified as Meow is now classified as Domestic animals, pets, which is the immediate predecessor to Cat in the AudioSet ontology.
sounds = classifySound(audioIn,fs,"ExcludedSounds","Cat")
sounds = 1×5 string array
"Stream" "Machine gun" "Snoring" "Bark" "Domestic animals, pets"
Call classifySound again and set ExcludedSounds to Domestic animals, pets. The sound class, Domestic animals, pets is a predecessor to both Bark and Meow, so by excluding it, the sounds previously identified as Bark and Meow are now both identified as the predecessor of Domestic animals, pets, which is Animal.
sounds = classifySound(audioIn,fs,"ExcludedSounds","Domestic animals, pets")
sounds = 1×5 string array
"Stream" "Machine gun" "Snoring" "Animal" "Animal"
Call classifySound again and set ExcludedSounds to Animal. The sound class Animal has no predecessors.
sounds = classifySound(audioIn,fs,"ExcludedSounds","Animal")
sounds = 1×3 string array
"Stream" "Machine gun" "Snoring"
If you want to avoid detecting Meow and its predecessors, but continue detecting successors under the same predecessors, use the IncludedSounds option. Call yamnetGraph to get a list of all supported classes. Remove Meow and its predecessors from the array of all classes, and then call classifySound again.
[~,classes] = yamnetGraph; classesToInclude = setxor(classes,["Meow","Cat","Domestic animals, pets","Animal"]); sounds = classifySound(audioIn,fs,"IncludedSounds",classesToInclude)
sounds = 1×4 string array
"Stream" "Machine gun" "Snoring" "Bark"
Read in an audio signal and listen to it.
[audioIn,fs] = audioread('multipleSounds-16-16-mono-18secs.wav');
sound(audioIn,fs)Call classifySound with no output arguments to generate a word cloud of the detected sounds.
classifySound(audioIn,fs);

Modify default parameters of classifySound to explore the effect on the word cloud.
threshold =0.1; minimumSoundSeparation =
0.92; minimumSoundDuration =
1.02; classifySound(audioIn,fs, ... 'Threshold',threshold, ... 'MinimumSoundSeparation',minimumSoundSeparation, ... 'MinimumSoundDuration',minimumSoundDuration);

Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
The classifySound function uses YAMNet to classify audio segments
into sound classes described by the AudioSet ontology. The classifySound
function preprocesses the audio so that it is in the format required by YAMNet and
postprocesses YAMNet's predictions with common tasks that make the results more
interpretable.
Pass each of the 521 confidence signals through a moving mean filter with a window length of 7.
Pass each of the signals through a moving median filter with a window length of 3.
Convert the confidence signals to binary masks using the specified
Threshold.Discard any sound shorter than
MinimumSoundDuration.Merge regions that are closer than
MinimumSoundSeparation.
Consolidate identified sound regions that overlap by 50% or more into single regions.
The region start time is the smallest start time of all sounds in the group. The region
end time is the largest end time of all sounds in the group. The function returns time
stamps, sounds classes, and the mean and maximum confidence of the sound classes within
the region in the resultsTable.
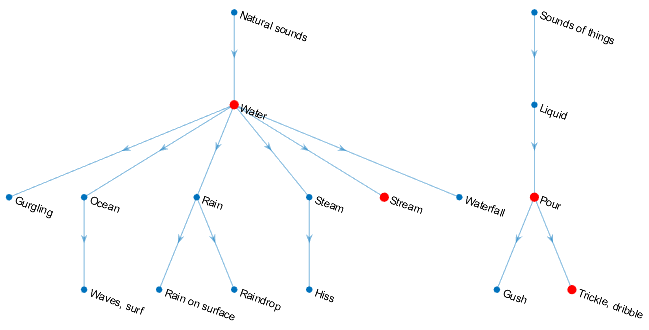
You can set the specificity level of your sound classification using the
SpecificityLevel option. For example, assume there are four sound
classes in a sound group with the following corresponding mean scores over the sound
region:
Water––0.82817Stream––0.81266Trickle, dribble––0.23102Pour––0.20732
The sound classes, Water, Stream,
Trickle, dribble, and Pour are situated in
AudioSet ontology as indicated by the graph:
The functions returns the sound class for the sound group in the
sounds output argument depending on the
SpecificityLevel:
"high"(default) –– In this mode,Streamis preferred toWater, andTrickle, dribbleis preferred toPour.Streamhas a higher mean score over the region, so the function returnsStreamin thesoundsoutput for the region."low"–– In this mode, the most general ontological category for the sound class with the highest mean confidence over the region is returned. ForTrickle, dribbleandPour, the most general category isSounds of things. ForStreamandWater, the most general category isNatural sounds. BecauseWaterhas the highest mean confidence over the sound region, the function returnsNatural sounds."none"–– In this mode, the function returns the sound class with the highest mean confidence score, which in this example isWater.
References
[1] Gemmeke, Jort F., et al. “Audio Set: An Ontology and Human-Labeled Dataset for Audio Events.” 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2017, pp. 776–80. DOI.org (Crossref), doi:10.1109/ICASSP.2017.7952261.
[2] Hershey, Shawn, et al. “CNN Architectures for Large-Scale Audio Classification.” 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2017, pp. 131–35. DOI.org (Crossref), doi:10.1109/ICASSP.2017.7952132.
Extended Capabilities
Version History
Introduced in R2020b