Introducción a la predicción de series de tiempo
Este ejemplo muestra cómo crear una red de memoria de corto-largo plazo (LSTM) para pronosticar datos de series de tiempo con la app Deep Network Designer.
Una red de LSTM es una red neuronal recurrente (RNN) que procesa datos de entrada formando un lazo con las unidades de tiempo y actualizando el estado de la RNN. El estado de la RNN contiene información recordada durante todas las unidades de tiempo anteriores. Puede utilizar una red neuronal de LSTM para pronosticar valores posteriores de una serie de tiempo o secuencia utilizando las unidades de tiempo anteriores como entrada.
Cargar datos secuenciales
Cargue los datos de ejemplo de WaveformData. Para acceder a los datos, abra el ejemplo como un script en vivo. El conjunto de datos con forma de onda contiene formas de onda generadas de forma sintética de diferentes longitudes con tres canales. En el ejemplo se entrena una red neuronal de LSTM para pronosticar valores futuros de las formas de onda, dados los valores de unidades de tiempo anteriores.
load WaveformDataVisualice algunas de las secuencias.
idx = 1;
numChannels = size(data{idx},2);
figure
stackedplot(data{idx},DisplayLabels="Channel " + (1:numChannels))Para este ejemplo, use la función de ayuda prepareForecastingData, incluida en este ejemplo como un archivo de soporte, para preparar los datos para el entrenamiento. Esta función prepara los datos usando estos pasos:
Para pronosticar los valores de unidades de tiempo futuras de una secuencia, especifique los objetivos como las secuencias de entrenamiento con valores desplazados una unidad de tiempo. En cada unidad de tiempo de la secuencia de entrada, la red neuronal de LSTM aprende a predecir el valor de la siguiente unidad de tiempo. No incluya la unidad de tiempo final en las secuencias de entrenamiento.
Divida los datos en un conjunto de entrenamiento que contenga el 90% de los datos y en un conjunto de prueba que contenga el 10% de los datos.
[XTrain,TTrain,XTest,TTest] = prepareForecastingData(data,[0.9 0.1]);
Para un mejor ajuste y para evitar que el entrenamiento diverja, puede normalizar los predictores y los objetivos para que los canales tengan media cero y varianza unitaria. Cuando haga predicciones, también deberá normalizar los datos de prueba con las mismas estadísticas que los datos de entrenamiento. Para obtener más información, consulte Crear una red para el pronóstico de series de tiempo con Deep Network Designer.
Definir la arquitectura de red
Para crear la red, abra la app Deep Network Designer.
deepNetworkDesigner
Para crear una red de secuencias, en la sección Sequence-to-Sequence Classification Networks (Untrained), haga clic en LSTM.
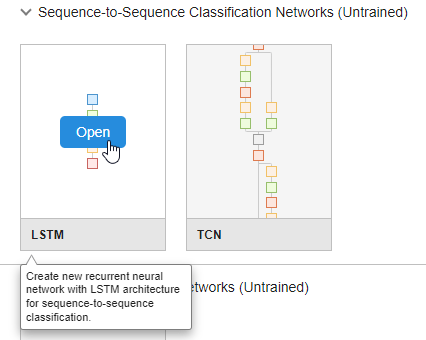
Se abrirá una red preconstruida adecuada para problemas de clasificación de secuencias. Puede convertir la red de clasificación en una red de regresión editando las capas finales.
Primero, elimine la capa softmax.
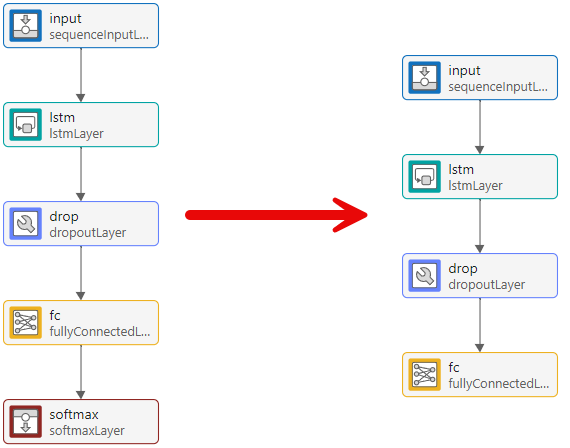
A continuación, ajuste las propiedades de las capas para que sean adecuadas para el conjunto de datos con forma de onda. Dado que el objetivo es pronosticar puntos de datos futuros en una serie de tiempo, el tamaño de salida debe ser igual que el tamaño de entrada. En este ejemplo, los datos de entrada tienen tres canales de entrada, por lo que la salida de la red también debe tener tres canales de salida.
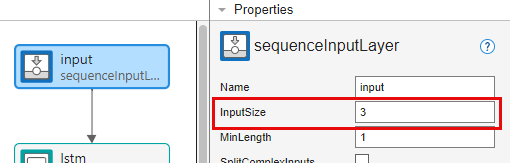
Seleccione la capa de entrada de secuencias input y establezca InputSize en 3.
Seleccione la capa totalmente conectada fc y establezca OutputSize en 3.
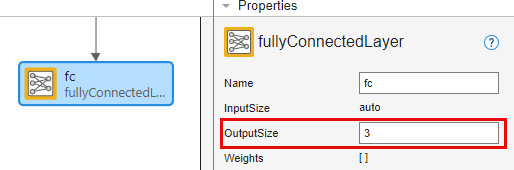
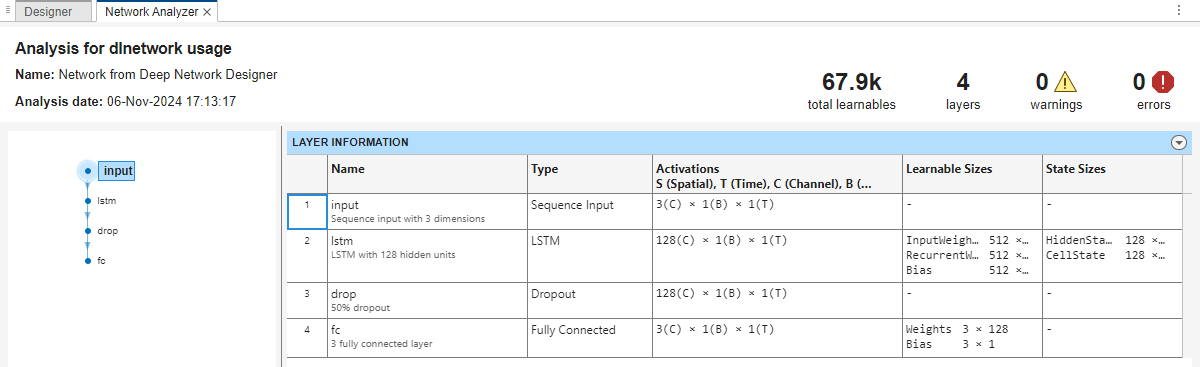
Para comprobar que la red está preparada para el entrenamiento, haga clic en Analyze. Dado que el analizador Deep Learning Network Analyzer no detecta ningún error o advertencia, la red está preparada para el entrenamiento. Para exportar la red, haga clic en Export. La app guarda la red en la variable net_1.
Especificar las opciones de entrenamiento
Especifique las opciones de entrenamiento. Para escoger entre las opciones se requiere un análisis empírico. Para explorar diferentes configuraciones de opciones de entrenamiento mediante la ejecución de experimentos, puede utilizar la app Experiment Manager. Dado que las capas recurrentes procesan los datos secuenciales en una unidad de tiempo cada vez, cualquier relleno en las unidades de tiempo finales puede influir negativamente en la salida de la capa. Rellene o trunque datos secuenciales a la izquierda, estableciendo la opción SequencePaddingDirection en "left".
options = trainingOptions("adam", ... MaxEpochs=300, ... SequencePaddingDirection="left", ... Shuffle="every-epoch", ... Plots="training-progress", ... Verbose=false);
Entrenar una red neuronal
Entrene la red neuronal con la función trainnet. Como el objetivo es la regresión, utilice la pérdida de error cuadrático medio (MSE).
net = trainnet(XTrain,TTrain,net_1,"mse",options);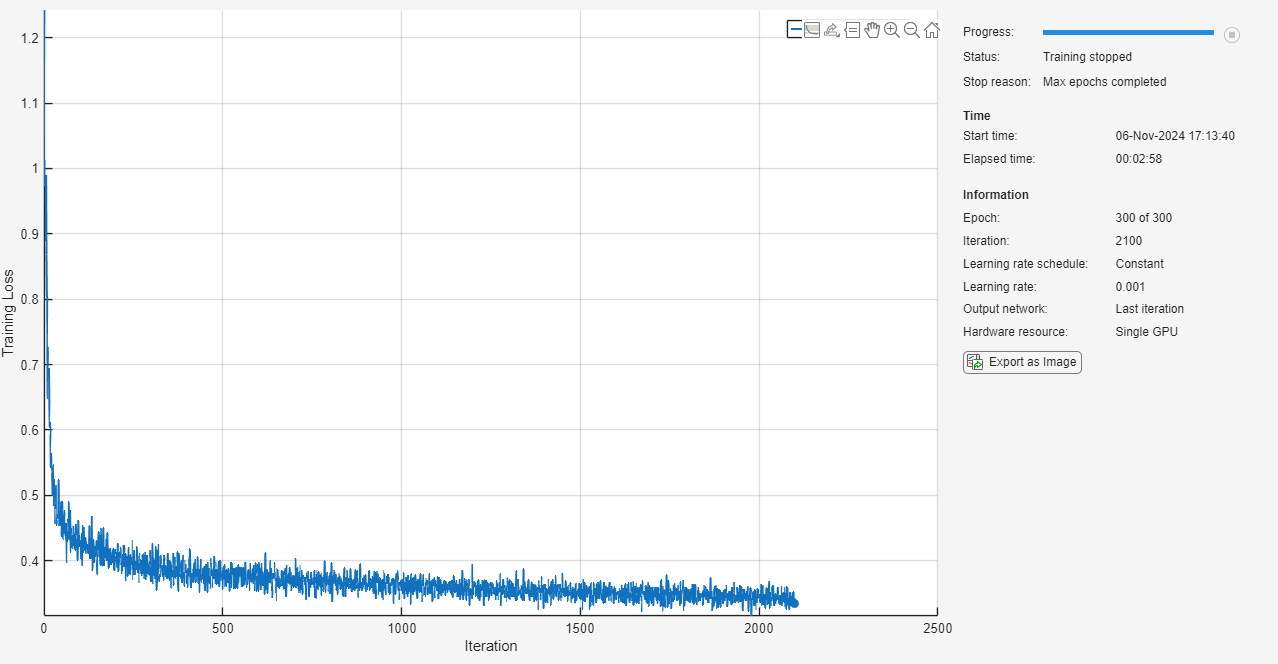
Pronosticar unidades de tiempo futuras
El pronóstico de lazo cerrado predice unidades de tiempo posteriores en una secuencia utilizando las predicciones previas como entrada.
Seleccione la primera observación de prueba. Inicialice el estado de la RNN restableciendo el estado mediante la función resetState. Luego, use la función predict para hacer una predicción inicial Z. Actualice el estado de la RNN con todas las unidades de tiempo de los datos de entrada.
X = XTest{1};
T = TTest{1};
net = resetState(net);
offset = size(X,1);
[Z,state] = predict(net,X(1:offset,:));
net.State = state;Para pronosticar más predicciones, forme un bucle con las unidades de tiempo y haga predicciones usando la función predict y el valor predicho para la unidad de tiempo anterior. Después de cada predicción, actualice el estado de la RNN. Pronostique las próximas 200 unidades de tiempo pasando iterativamente el valor predicho anteriormente a la RNN. Dado que la RNN no requiere los datos de entrada para realizar más predicciones, puede especificar cualquier número de unidades de tiempo que desee pronosticar. La última unidad de tiempo de la predicción inicial es la primera unidad de tiempo pronosticada.
numPredictionTimeSteps = 200; Y = zeros(numPredictionTimeSteps,numChannels); Y(1,:) = Z(end,:); for t = 2:numPredictionTimeSteps [Y(t,:),state] = predict(net,Y(t-1,:)); net.State = state; end numTimeSteps = offset + numPredictionTimeSteps;
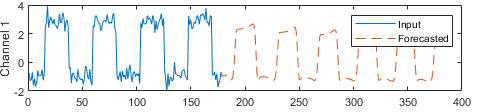
Compare las predicciones con los valores de entrada.
figure l = tiledlayout(numChannels,1); title(l,"Time Series Forecasting") for i = 1:numChannels nexttile plot(X(1:offset,i)) hold on plot(offset+1:numTimeSteps,Y(:,i),"--") ylabel("Channel " + i) end xlabel("Time Step") legend(["Input" "Forecasted"])
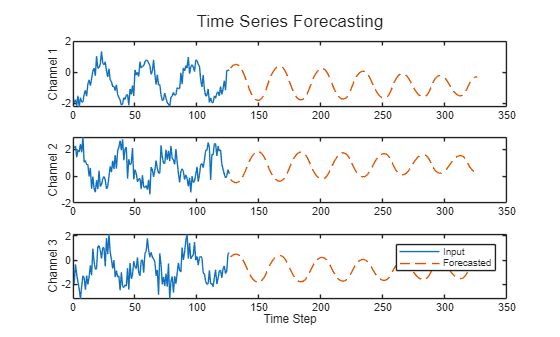
Este método de predicción se llama pronóstico de lazo cerrado. Para obtener más información sobre el pronóstico de series de tiempo y realizar pronósticos de lazo abierto, consulte Pronóstico de series de tiempo mediante deep learning.
Consulte también
dlnetwork | trainingOptions | trainnet | scores2label | Deep Network Designer