augmentedImageDatastore
Transformar lotes para aumentar datos de imágenes
Descripción
Un almacén de datos de imágenes aumentado transforma lotes de datos de entrenamiento, validación, prueba y predicción, con preprocesamientos opcionales como cambio de tamaño, rotación y reflexión. Cambie el tamaño de las imágenes para que sean compatibles con el tamaño de entrada de la red de deep learning. El aumento de datos de imágenes de entrenamiento con operaciones de preprocesamiento aleatorizadas ayuda a evitar que la red se sobreajuste y memorice los detalles exactos de las imágenes de entrenamiento.
Para entrenar una red usando imágenes aumentadas, proporcione el augmentedImageDatastore a la función trainnet. Para obtener más información, consulte Preprocesar imágenes para deep learning.
Cuando utiliza un almacén de datos de imágenes aumentado como fuente de imágenes de entrenamiento, el almacén de datos perturba aleatoriamente los datos de entrenamiento de cada época, para que cada época utilice un conjunto de datos ligeramente diferente. El número real de imágenes de entrenamiento de cada época no cambia. Las imágenes transformadas no se almacenan en la memoria.
Una
imageInputLayernormaliza imágenes utilizando la media de las imágenes aumentadas, no la media del conjunto de datos original. Esta media se calcula una vez para la primera época aumentada. El resto de las épocas utilizan la misma media, de modo que la imagen media no cambia durante el entrenamiento.Use un almacén de datos de imágenes aumentado para preprocesar de forma eficiente las imágenes para deep learning, incluyendo el cambio de tamaño de estas. No use la opción
ReadFcnde objetosImageDatastore.ImageDatastorepermite leer lotes de archivos de imágenes JPG o PNG mediante precarga. Si establece la opciónReadFcncomo una función personalizada,ImageDatastoreno realiza la precarga y suele ser bastante más lenta.
De forma predeterminada, un augmentedImageDatastore solo cambia el tamaño de las imágenes para ajustarlas al tamaño de salida. Puede configurar opciones para transformar imágenes adicionales empleando un objeto imageDataAugmenter.
Creación
Sintaxis
Descripción
auimds = augmentedImageDatastore( crea un almacén de datos de imágenes aumentado para problemas de clasificación utilizando imágenes de un almacén de datos de imágenes outputSize,imds)imds. El almacén de datos cambia el tamaño de las imágenes a la altura y anchura especificadas por outputSize.
auimds = augmentedImageDatastore( crea un almacén de datos de imágenes aumentado para problemas de clasificación y regresión. El arreglo outputSize,X,Y)X contiene las variables predictoras y el arreglo Y contiene las etiquetas categóricas o repuestas numéricas.
auimds = augmentedImageDatastore( crea un almacén de datos de imágenes aumentado para predecir respuestas de datos de imágenes en el arreglo outputSize,X)X.
auimds = augmentedImageDatastore( crea un almacén de datos de imágenes aumentado para problemas de clasificación y regresión. La tabla outputSize,tbl)tbl contiene predictores y respuestas.
auimds = augmentedImageDatastore( crea un almacén de datos de imágenes aumentado para problemas de clasificación y regresión. La tabla outputSize,tbl,responseNames)tbl contiene predictores y respuestas. El argumento responseNames especifica las variables de respuesta en tbl.
auimds = augmentedImageDatastore(___, también establece propiedades de escritura utilizando argumentos nombre-valor. Por ejemplo, Name=Value)augmentedImageDatastore([28,28],imds,OutputSizeMode="centercrop") crea un almacén de datos de imágenes aumentado que recorta la parte central de las imágenes.
Argumentos de entrada
Argumentos de par nombre-valor
Propiedades
Funciones del objeto
combine | Combine data from multiple datastores |
hasdata | Determine if data is available to read |
numpartitions | Number of datastore partitions |
partition | Partition a datastore |
partitionByIndex | Partition augmentedImageDatastore according to
indices |
preview | Preview subset of data in datastore |
read | Read data from augmentedImageDatastore |
readall | Read all data in datastore |
readByIndex | Read data specified by index from
augmentedImageDatastore |
reset | Reset datastore to initial state |
shuffle | Shuffle data in augmentedImageDatastore |
subset | Create subset of datastore or FileSet |
transform | Transform datastore |
isPartitionable | Determine whether datastore is partitionable |
isShuffleable | Determine whether datastore is shuffleable |
Ejemplos
Entrene una red neuronal convolucional con datos de imágenes aumentadas. El aumento de datos ayuda a evitar que la red se sobreajuste y memorice los detalles exactos de las imágenes de entrenamiento.
Cargue los datos de muestra, que están formados por imágenes sintéticas de dígitos manuscritos. XTrain es un arreglo de 28 por 28 por 1 por 5000, donde:
28 es la altura y la anchura de las imágenes.
1 es el número de canales.
5000 es el número de imágenes sintéticas de dígitos manuscritos.
labelsTrain es un vector categórico que contiene las etiquetas para cada observación.
load DigitsDataTrainReserve 1000 de las imágenes para la validación de la red.
idx = randperm(size(XTrain,4),1000); XValidation = XTrain(:,:,:,idx); XTrain(:,:,:,idx) = []; TValidation = labelsTrain(idx); labelsTrain(idx) = [];
Cree un objeto imageDataAugmenter que especifique las opciones de preprocesamiento para el aumento de imágenes, como el cambio de tamaño, la rotación, la traslación y la reflexión. Traslade aleatoriamente las imágenes hasta tres píxeles horizontal y verticalmente, y rote las imágenes con un ángulo de hasta 20 grados.
imageAugmenter = imageDataAugmenter( ... 'RandRotation',[-20,20], ... 'RandXTranslation',[-3 3], ... 'RandYTranslation',[-3 3])
imageAugmenter =
imageDataAugmenter with properties:
FillValue: 0
RandXReflection: 0
RandYReflection: 0
RandRotation: [-20 20]
RandScale: [1 1]
RandXScale: [1 1]
RandYScale: [1 1]
RandXShear: [0 0]
RandYShear: [0 0]
RandXTranslation: [-3 3]
RandYTranslation: [-3 3]
Cree un objeto augmentedImageDatastore para utilizarlo durante el entrenamiento de la red y especifique el tamaño de salida de la imagen. Durante el entrenamiento, el almacén de datos lleva a cabo el aumento de imágenes y cambia su tamaño. El almacén de datos aumenta las imágenes sin guardar ninguna en la memoria. trainnet actualiza los parámetros de la red y descarta las imágenes aumentadas.
imageSize = [28 28 1];
augimds = augmentedImageDatastore(imageSize,XTrain,labelsTrain,'DataAugmentation',imageAugmenter);Especifique la arquitectura de la red neuronal convolucional.
layers = [
imageInputLayer(imageSize)
convolution2dLayer(3,8,'Padding','same')
batchNormalizationLayer
reluLayer
maxPooling2dLayer(2,'Stride',2)
convolution2dLayer(3,16,'Padding','same')
batchNormalizationLayer
reluLayer
maxPooling2dLayer(2,'Stride',2)
convolution2dLayer(3,32,'Padding','same')
batchNormalizationLayer
reluLayer
fullyConnectedLayer(10)
softmaxLayer];Especifique las opciones de entrenamiento. Para escoger entre las opciones se requiere un análisis empírico. Para explorar diferentes configuraciones de opciones de entrenamiento mediante la ejecución de experimentos, puede utilizar la app Experiment Manager.
opts = trainingOptions('sgdm', ... 'MaxEpochs',15, ... 'Shuffle','every-epoch', ... 'Plots','training-progress', ... 'Metrics','accuracy', ... 'Verbose',false, ... 'ValidationData',{XValidation,TValidation});
Entrene la red neuronal con la función trainnet. Para la clasificación, utilice la pérdida de entropía cruzada. De forma predeterminada, la función trainnet usa una GPU en caso de que esté disponible. Para entrenar en una GPU se requiere una licencia de Parallel Computing Toolbox™ y un dispositivo GPU compatible. Para obtener información sobre los dispositivos compatibles, consulte GPU Computing Requirements (Parallel Computing Toolbox). De lo contrario, la función trainnet usa la CPU. Para especificar el entorno de ejecución, utilice la opción de entrenamiento ExecutionEnvironment.
net = trainnet(augimds,layers,"crossentropy",opts);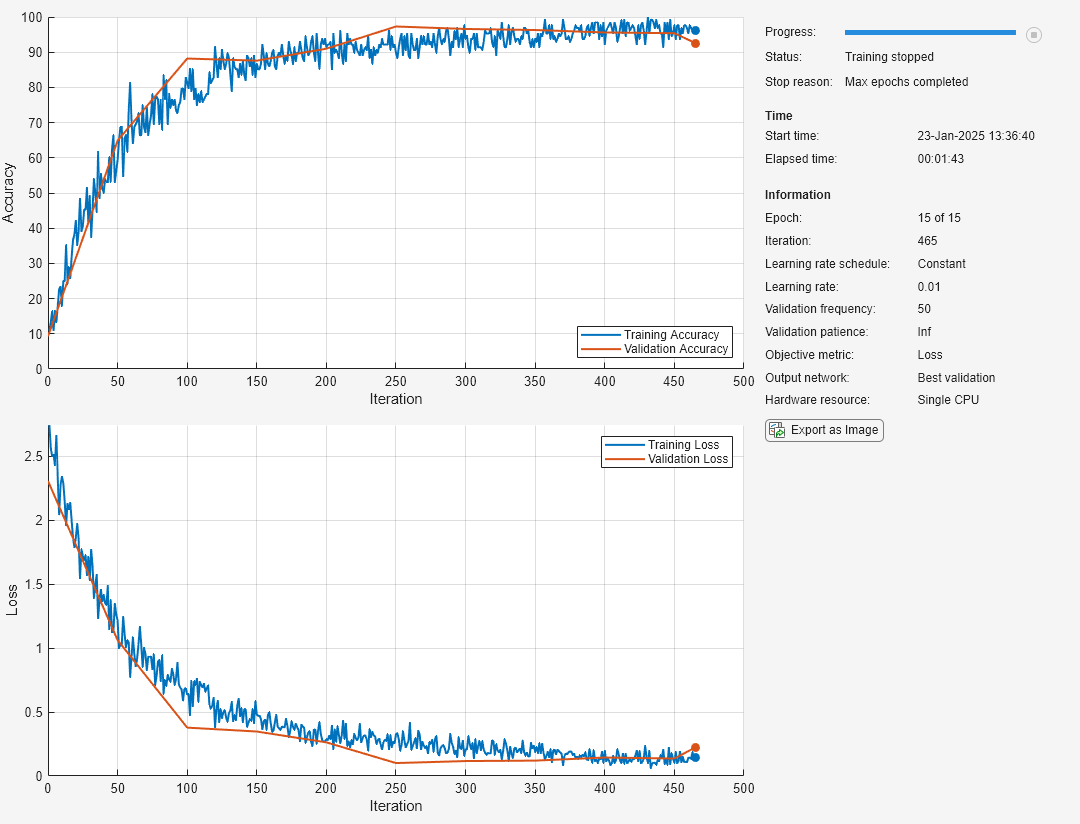
Sugerencias
Puede visualizar muchas imágenes transformadas en la misma figura utilizando la función
imtile. Por ejemplo, este código muestra un minilote de imágenes transformadas desde un almacén de datos de imágenes aumentado llamadoauimds.minibatch = read(auimds); imshow(imtile(minibatch.input))
De forma predeterminada, cambiar el tamaño es la única operación de preprocesamiento de imágenes que se realiza en las imágenes. Para habilitar operaciones de preprocesamiento adicionales, utilice el argumento nombre-valor
DataAugmentationcon un objetoimageDataAugmenter. Cada vez que se leen imágenes del almacén de datos de imágenes aumentado, se aplica una combinación aleatoria diferente de operaciones de preprocesamiento a cada imagen.
Historial de versiones
Introducido en R2018a
Consulte también
imageDataAugmenter | imageInputLayer | trainnet | trainingOptions | dlnetwork