Time Series Modeler
Description
Use the Time Series Modeler app to train models for time series prediction.
Using this app, you can:
Import and visualize time series data. You can also specify data preprocessing options such as normalization and splitting the data into training and validation sets.
Train models for time series prediction. You can select and adapt predefined models or build custom deep neural networks using an interactive network editor.
Visualize training progress and monitor training metrics.
Automatically detect overfitting during training.
Use your trained model to predict values for the training and validation data sets.
Track and compare the performance of trained models.
Generate code to help you predict on new data.
Export your model to Simulink® layer blocks for integration of your model into a larger engineering system.
Available Models
Long short-term memory (LSTM) networks
Gated recurrent unit (GRU) networks
Multi-layer perceptron (MLP) networks
Convolutional neural networks (CNN)
Custom deep neural networks suitable for one-step-ahead time series modeling
Autoregressive moving average (ARMA) model. This model requires System Identification Toolbox™.
Open the Time Series Modeler App
MATLAB® Toolstrip: On the Apps tab, under Machine Learning and Deep Learning, click the app icon.
MATLAB command prompt: Enter
timeSeriesModeler.
Examples
- Compare Deep Learning and ARMA Models for Time Series Modeling
- Build Custom Network for Time Series Modeling of a Virtual Sensor
- Detect Overfitting When Training Model for Time Series Forecasting
- Denoise ECG Signals Using Deep Learning
- Autoregressive Time Series Prediction Using Deep Learning
- Build Transformer Network for Time Series Regression
- Create Virtual Sensors Interactively Using Deep Learning and Generate C Code for Deployment
- Estimate ARMA Model Using Time Series Modeler app (System Identification Toolbox)
- Predict Battery State-Of-Charge Using Time Series Modeler App (System Identification Toolbox)
Parameters
When you click New , the app opens the Import Data dialog box. Use the dialog box to specify these options: Data, Responses, Data Set Variable, Time step dimension, Predictors, Validation, and Randomize.
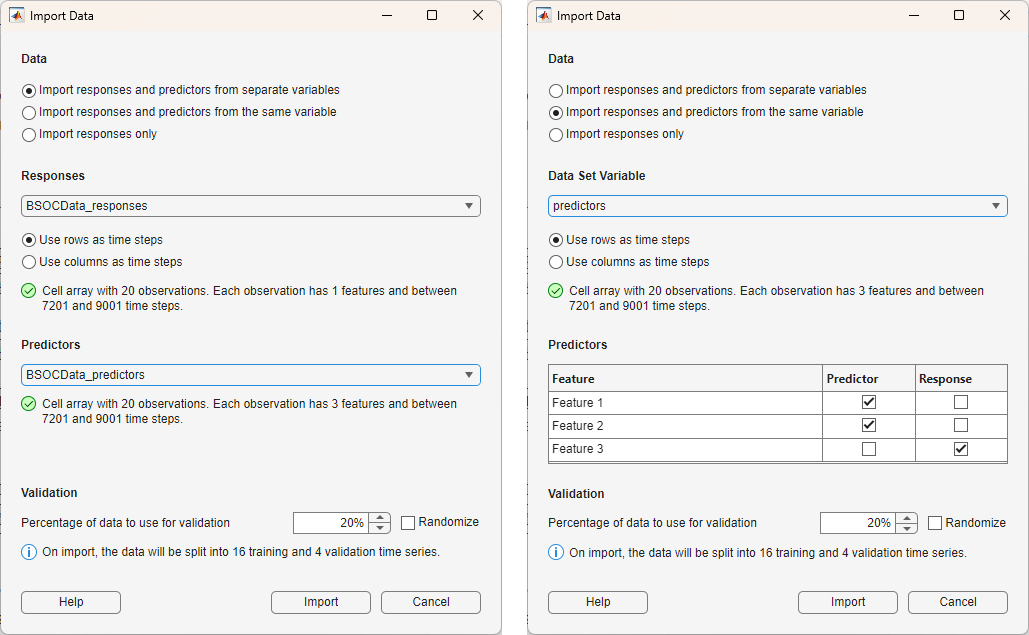
Specify the data type and location as one of these options:
Import responses and predictors from separate variables
Import responses and predictors from the same variable
Import responses only
If you import the responses and predictors from the same variable, then the app displays a table where you can select which features are responses and which features are predictors. For more information, see Predictors.
In the Responses list, select the variable to use to
train your model to predict, specified as a numeric array, cell array, table, or
timetable object. For timetable data, the data
must be sampled at regular intervals. For other input types, the app assumes that
the data is sampled at regular intervals.
Dependencies
This option is only available if Data is Import responses and predictors from separate variables or Import responses only.
In the Data Set Variable list, select the variable to use
to train your model, specified as a numeric array, cell array, table, or
timetable object. For timetable data, the data
must be sampled at regular intervals. For other input types, the app assumes that
the data is sampled at regular intervals.
Dependencies
This option is only available if Data is Import responses and predictors from the same variable.
Specify the format for the time series data. The app accepts time series data
in either "TC" (time, channel) or "CT"
(channel, time) format.
For
"TC"data, select Use rows as time steps.For
"CT"data, select Use columns as time steps.
Tips
For each option, the app displays information about your data, such as the number of time series, number of features, and length of the time steps. Use this information to check that you have specified the correct time dimension.
In the Predictors list, specify additional variables that are related, but are not part of, the time series you want to model.
If Data is Import responses and predictors from the same variable, then select the predictors variable. The predictor data must be specified as a numeric array, cell array, table, or
timetableobject that is compatible with the response data. The app assumes that the input data is sampled at regular intervals.If Data is Import responses and predictors from the same variable, then use the table to select which features are responses and which features are predictors.
Dependencies
This option is only available if Data is Import responses and predictors from the same variable or Import responses and predictors from the same variable.
If you import a separate predictor variable, then the data type of the response variable and the predictors must match. For example, if you specify the responses as a table, then the predictors must also be a table.
In the Validation section, specify the percentage of data to use for validation.
The validation split depends on how many time series you have. Suppose that
you specify Validation as a value val:
If you have a single time series, then the validation data is the last
val% of the time steps. For example, if you have a single time series with 100 time steps and a validation split of 30%, then the app uses the first 70 time steps for training and the last 30 time steps for validation.If you have multiple time series, then the validation data is
val% of the time series. For example, if you have 100 time series and a validation split of 30%, then the app uses 70 time series for training and 30 time series for validation.
Tips
Monitoring the performance of the model on the validation data is important for detecting overfitting. For more information, see Training Diagnostics.
Select the Randomize check box to randomly assign the specified proportion of observations to the validation data set.
Tips
Randomizing the validation data can improve the accuracy of networks trained on data stored in a nonrandom order.
Dependencies
This option is only available if your data contains multiple observations.
After you import data, the app displays a summary of the data in the Data tab. You can also preview individual observations.
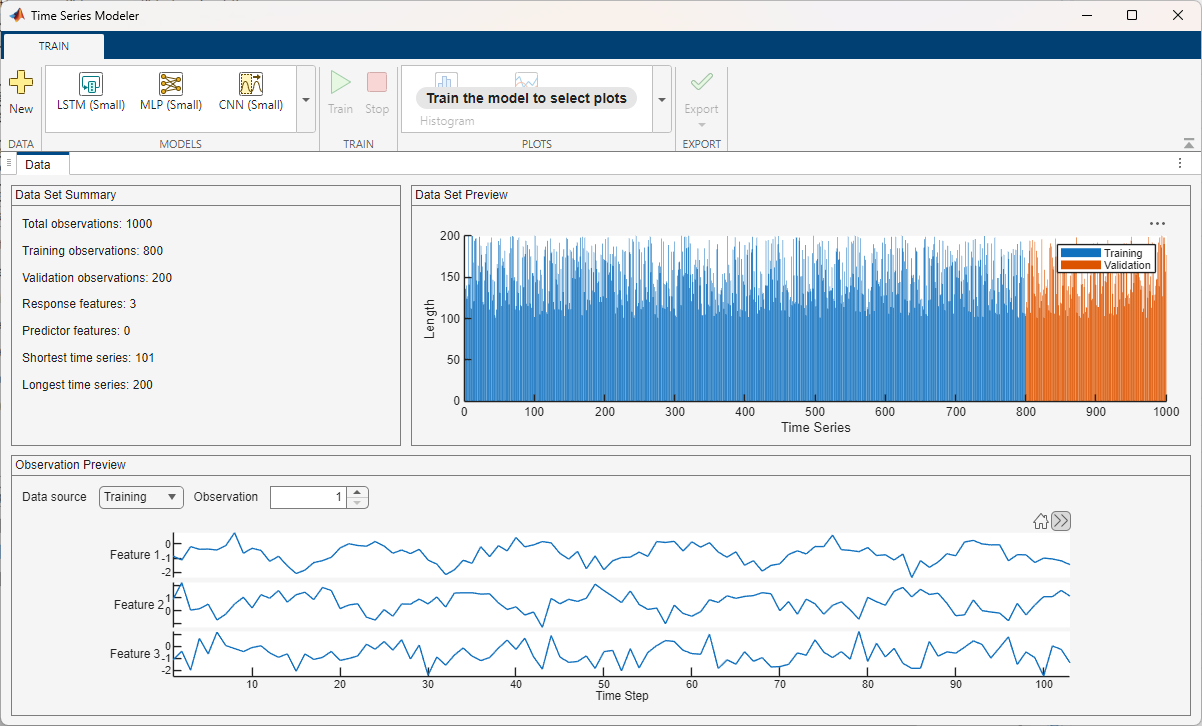
Dependencies
The plots you see in the Data tab depend on whether your data contains a single observation or multiple observations.
In the model gallery, select a model to train for time series modeling.
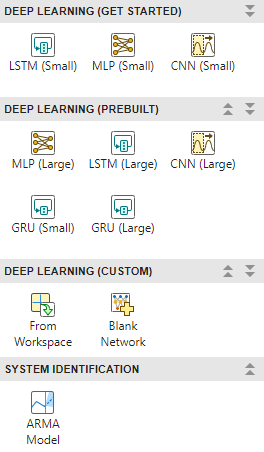
The model gallery contains template models that you can use or adapt for your task.
The app includes several built-in deep learning models in small and large variants. You
can customize these models by changing their parameters or by using the interactive
editor. If you require more customization, then you can import a
dlnetwork object from the workspace or create a network from scratch
using the network editor. For more information, see Customize Network. When you choose a deep learning model, the app
displays a plot of the network architecture. If you have System Identification Toolbox, then the app also includes the ARMA model. When you choose the ARMA
model, the app displays the equation of the model structure along with the structure
configuration options.
For deep learning models, in the Model tab, you can specify Data Preprocessing, Model Hyperparameters, and Training Options. To make custom edits to your model, see Customize Network. For the ARMA model, in the Summary tab under Model, you can specify Model Structure and Training Options.
You can duplicate your model options into a new draft by clicking the Duplicate button . You can also delete a model by clicking the Delete button .
Predefined Models
Most of the predefined deep learning models have a small and a large version. The small versions have fewer learnable parameters and layers and do not include dropout layers. The large versions have more learnable parameters and layers and include dropout layers. The small models are faster to train, whereas the large models can learn more complex features.
The app supports small and large versions of these models:
LSTM — Long short-term memory network, a type of recurrent network that can capture long-term dependencies in sequence data.
MLP — Multi-layer perceptron, a type of feedforward network where each layer is fully connected to the next.
GRU — Gated recurrent unit, a type of recurrent network that can capture long-term dependencies in sequence data. GRU networks are simplified and potentially more computationally efficient versions of LSTM networks.
CNN — Convolutional neural network, a type of feedforward network that learns features by applying sliding convolutional filters to 1-D input.
The app also supports the linear autoregressive moving average (ARMA) model, which requires System Identification Toolbox. This model combines autoregression and moving average components to capture temporal dependencies and noise. For more information on training ARMA models, see Estimate ARMA Model Using Time Series Modeler app (System Identification Toolbox).
Custom Deep Learning Networks
You can use the app to create and train custom deep learning models. Using the app, you can:
Adapt any of the predefined models. To adapt a model, click Customize Network.
Import a
dlnetworkobject suitable for time series modeling tasks. To import adlnetworkobject, click From Workspace.Open a blank canvas for network creation. To open a canvas, click Blank Network .
Custom models must be compatible with your data. For a list of requirements, see Customize Network.
Model Options
Use the Data Preprocessing options to control how the network processes the data. These options are available only for deep learning models.
Use past values of responses as inputs (default
'off') — Select this option to use an autoregressive model. Consider using an autoregressive model when past values of the response time series influence future predictions. Autoregressive models are often slower than nonautoregressive models at predicting on new data.Normalize observations (default
'on') — Select this option to normalize the training and validation data. When you select this option, the network normalizes the input data at the sequence input layer and denormalizes it at the inverse normalization layer. By default, the app normalizes the data, X, using z-score normalization:where μ is the mean and σ is the standard deviation of the training data across each channel.
When training neural networks, normalization helps stabilize and speeds up network training using gradient descent. If your data is poorly scaled, then during training, the loss can become
NaNand the network parameters can diverge.Sort observations by length (default
'on') — Select this option to enable sorting the time series by length. By default, the app sets the SequenceLength training option tolongest. This setting causes the software to pad the sequences so that all the sequences in a mini-batch have the same length as the longest sequence in the mini-batch. Sorting observations by length reduces the amount of padding or discarded data when padding or truncating sequences. For more information, seeSequenceLength.This option is only available if your time series data contains multiple observations.
Split time series into windows — Split the time series training data into windows (chunks). Splitting the training data into shorter windows can improve training time and accuracy. This option is only available if you have a single, long observation. If you enable this option, then the app might not use all of the data for training. The amount of discarded data depends on the length of the time series, the window length, and the window stride. For example, for a time series with 1,010 time steps, a window length of 200, and a stride of 200, the app will split the time series into five windows and discards the final 10 time steps.
Window options
Window length — Number of time steps to include in each window of data. The window length needs to be long enough to capture relevant patterns but not too long to dilute them.
Window stride — Number of time steps between each window. When the stride is less than the window length, then windows will overlap. Smaller strides give more overlap (more data, slower training); larger strides reduce overlap (faster, but less data).
Use the Model Hyperparameters options to control the network architecture. These options are only available for the predefined deep neural networks. If you customize the network using the Customize Network button, then these options are not available.
Network depth (blocks) — This option specifies the number of repeating blocks, where the blocks depend on which network you select. For example, for an LSTM network with a dropout probability greater than 0, the repeating blocks are an LSTM layer followed by a dropout layer.
Hidden units — This option specifies the number of hidden units (also known as the hidden size) in each of the layers with learnable parameters. The number of hidden units corresponds to the amount of information that the layer remembers between time steps. If the number of hidden units is too large, then the layer can overfit to the training data.
This option is supported for LSTM, GRU, and MLP networks only.
Filter size — This option specifies the width of the filters in the 1-D convolutional layers.
This option is supported for CNNs only.
Filters — This option specifies the number of filters in the 1-D convolutional layers. This number corresponds to the number of neurons in the layer that connect to the same region in the input. This parameter determines the number of channels (feature maps) in the layer output.
This option is supported for CNNs only.
Dropout probability — This option specifies the dropout probability for each of the dropout layers in the network.
If the dropout probability is 0, then the network does not contain any dropout layers.
If the dropout probability is greater than 0, then the network contains dropout layers with the specified dropout probability. The number of dropout layers depends on the network depth.
For more information, see
dropoutLayer.
This button is only available for deep learning models.
After you select a predefined deep learning network, click Customize Network to open a window for network editing. The app opens the network editing window with input and output layers suitable for your task. The network editor is a simplified version of the Deep Network Designer app that is tailored for constructing and configuring networks for time series modeling tasks. For more information about building deep neural networks, see Build Networks with Deep Network Designer.
You can use the Customize Network window to add or delete layers and to change network parameters. To check the edited network for issues, click Analyze. When you are happy with your changes, click Accept Changes to accept the network changes.
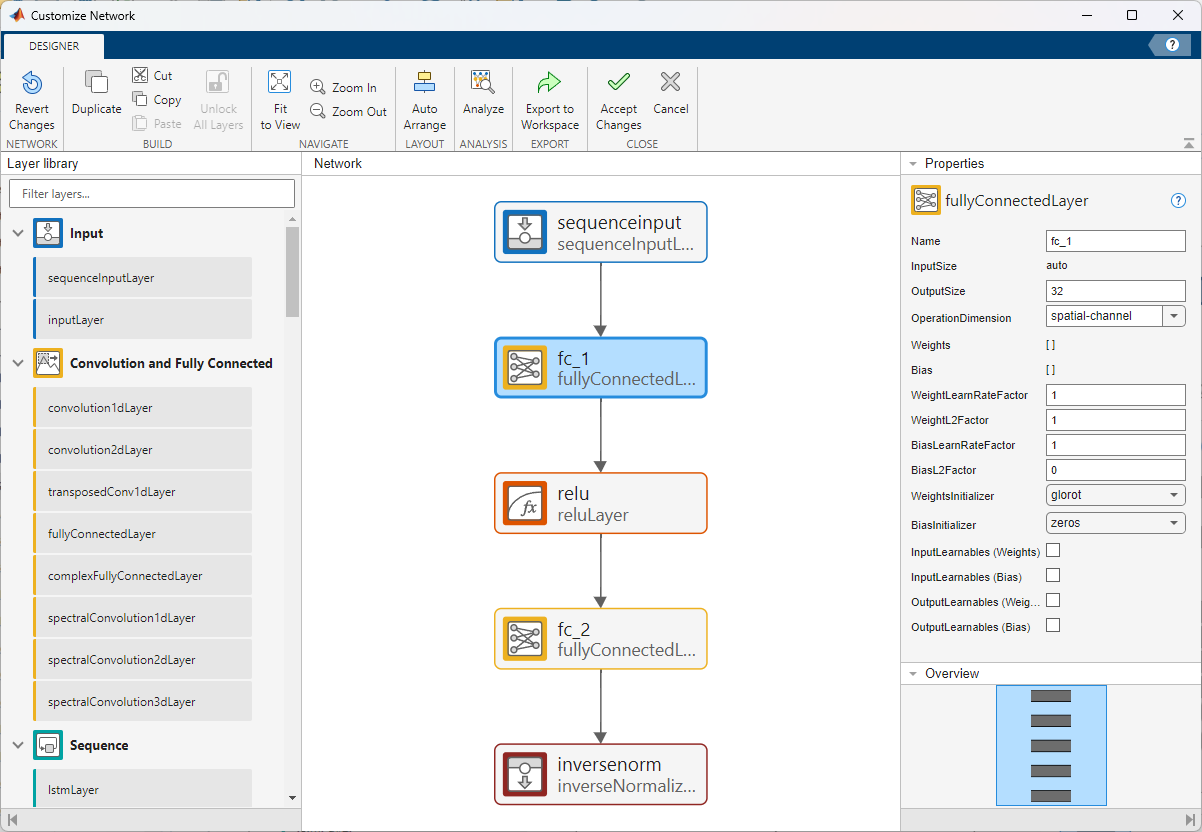
Dependencies
If you edit a network or create one from scratch, then the network must be suitable for sequence-to-sequence regression tasks. If you select Use past values of responses as inputs, then the network must also be suitable for tasks where you also use the responses as predictors with a time lag of 1.
The network must also be compatible with the imported data in these ways.
The network must have a single input layer and a single output layer.
The input size must match the input size of the imported data. If you select Use past values of responses as inputs, then the input size must be Number of Response Channels + Number of Predictor Channels. If you do not select Use past values of responses as inputs, then the input size must be Number of Predictor Channels.
The output size must match the output size of the imported data, where the output size of the imported data is Number of Response Channels.
The input and output format must match the input and output format of the data.
If the input layer is a
sequenceInputLayerand you select Use past values of responses as inputs, then theMinLengthproperty must be less than the minimum sequence length in the imported data. If the input layer is asequenceInputLayerand you do not select Use past values of responses as inputs, then theMinLengthproperty must be less than or equal to the minimum sequence length in the imported data.If the input layer is an
inputLayer, then the time dimension of theInputSizeproperty must be less than or equal to the minimum sequence length in the imported data.The size of the time dimension on the input layer must match that of the output layer.
If the input layer has a
SplitComplexInputproperty, then this property must be set tofalse.
Use the Model Structure options to specify the structure of the model. These options are available only for the ARMA model.
Configuration choice — Select Configuration choice as either
Specify maximum lag onlyorSpecify orders. Each choice gives you a different set of options to configure.Include integration — This option specifies to include the integrator in the model structure.
Input-Output Delay — This option specifies the input-output delay, also known as the transport delay. It appears only when you import both responses and predictors.
For more information on the model structure options, see Model Structure Configuration (System Identification Toolbox).
Use the Training Options options to control how the app trains the model. These options are only available for deep learning models.
InitialLearnRate — This option specifies the initial learning rate to use for training. If the learning rate is too low, then training can take a long time. If the learning rate is too high, then training might reach a suboptimal result or diverge.
When the SolverName option is sgdm, the default value is
0.01. When SolverName is rmsprop or adam, the default value is0.001. To set the SolverName option, click Show advanced options and then click Solver.For more information, see
InitialLearnRate.MiniBatchSize — This option specifies the mini-batch size to use for training. A mini-batch is a subset of the training set that is used to evaluate the gradient of the loss function and update the weights. If the mini-batch size does not evenly divide the number of training samples, then the software discards the training data that does not fit into the last complete mini-batch of each epoch. If the mini-batch size is smaller than the number of training samples, then the software does not discard any data.
For more information, see
MiniBatchSize.MaxEpochs — This option specifies the maximum number of epochs (full passes of the data) to use for training.
For more information, see
MaxEpochs.Show advanced options — Select this option to specify additional training options. For more information about these training options, see
trainingOptions.
These options are only available for the ARMA model.
Focus on simulation (long time-horizon prediction) fidelity — Select this option to minimize the simulation error between measured and simulated outputs during estimation. As a result, the estimation focuses on making a good fit for simulation of model response with the current inputs. This option is available only when you import both responses and predictors.
Enforce model stability — Select this option to enforce stability of the estimated model.
Maximum iterations — This option specifies the maximum number of iterations during loss-function minimization, as a nonnegative integer. The iterations stop when MaxIterations is reached or another stopping criterion is satisfied, such as Tolerance. Specifying MaxIterations as
0returns the result of the start-up procedure.Tolerance — This option specifies the minimum percentage difference between the current value of the loss function and its expected improvement after the next iteration, as a positive scalar. When the percentage of expected improvement is less than Tolerance, the iterations stop. The estimate of the expected loss-function improvement at the next iteration is based on the Gauss-Newton vector computed for the current parameter value.
Robustify training against data outliers — Select this option to strengthen training against data outliers.
Use parallel computation — Select this option to enable parallel computing for model training. You use parallel computing to simultaneously train multiple candidate models based on the model structure you specify.
Use the Closed Loop Metric Evaluation Options to control how the app evaluates the metrics during closed loop evaluation. These options only apply to the metric evaluation after training. The results of the metric evaluation appear in the Training Results section. These options are only available for deep learning models.
Use stateful prediction — Update the network state every iteration during closed loop prediction. Select this option if your model architecture supports statefulness (for example, LSTM or GRU) and each prediction depends on the previous one.
Initial context length — Number of time steps of true values to use as the initial context of the first prediction during closed loop prediction.
Sliding window length — Number of time steps to use as input at each subsequent prediction step during closed loop prediction. After the initial prediction, the model slides through the time series as it makes predictions. Choose a window length that captures enough information to make the prediction. A window length that is too short can cause the model to miss trends, and a window length that is too long can add noise or complexity to the predictions. If you have only response data, then you might need a longer window length in order to make accurate predictions.
Dependencies
These options only appear when you select Use past values of responses as inputs that is, when you use an autoregressive model.
The default sliding window length depends on the network. For most networks, using stateful prediction with a sliding window length value greater than 1 will produce poor results. By default, the app does not use stateful prediction if the sliding window length is greater than one.
The Training Results appear in the
Summary tab after you have trained the model. For deep
learning models, the app displays the loss (RMSE) and MAE values. If the value of
Use past responses as input is true,
then the app also displays the closed loop RMSE and MAE values. For more
information, see Data Preprocessing. For the ARMA model, the app always
displays both the closed-loop and open-loop values for RMSE and MAE.
Click the Train button to train the model.
When training deep learning models, the app displays metrics for the MAE and the
model loss for both the training and validation data. The app also displays information
about the training and training diagnostics. When training the ARMA model, the app opens
the Model Selector panel and displays the statement Trying
various model structure and fitting algorithms... in the Training
Information section.
This panel is only available for deep learning models.
When training deep learning models, the app displays the Training Information panel.
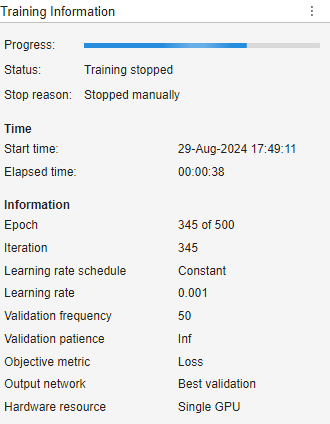
This panel contains this information:
Progress — Progress bar indicating the training progress.
Status — The training status. The status can be
"Running"or"Training stopped".Stop reason — The reason why training stopped, such as that the max epochs was reached.
Start time — The training start time.
Elapsed time — The elapsed time during training.
Epoch — The current epoch.
Iteration — The current iteration.
Learning rate schedule — The learning rate schedule used during training. This option is set using the advanced training option LearnRateSchedule.
Learning rate — The current learning rate. This option depends on the InitialLearnRate, LearnRateSchedule, LearnRateDropPeriod, and LearnRateDropFactor training options.
Validation frequency — Frequency of neural network validation. This option depends on the advanced training option ValidationFrequency.
Validation patience — Patience of validation stopping. This option depends on the advanced training option ValidationPatience.
Objective metric — Frequency of neural network validation. This option depends on the advanced training option ValidationFrequency.
Output Network — Neural network to return when training completes. The app always returns the network with the lowest validation loss during training.
Hardware resource — Hardware resource for training neural network. This option depends on the advanced training option ExecutionEnvironment.
For more information about the training options, see trainingOptions.
During training using the Time Series Modeler app, select the Training Diagnostics panel at the bottom of the app to see if your model is overfitting. It is difficult to determine why a model is overfitting, but the app provides a list of general suggestions to help prevent overfitting when training a deep neural network. This information is available only for deep learning models.

To check for overfitting, at each validation frequency, the app checks by what percentage the
validation loss is higher than the average training loss. The software computes the average
training loss across the last miniBatchSize iterations. If the validation
loss is more than 10% higher than the average training loss for two or more validation
checks in a row, then the model is overfitting.
During training, the overfitting diagnostic indicates one of these states:
Not enough information available — This message appears during early training when the app is unable to determine if overfitting is occurring. You will also see this message if you have not specified any validation data.
No issues detected — This message means that the app found no signs of overfitting. The validation loss does not exceed the training loss by more than 10% for two consecutive validation checks.
Overfitting — This message means the app has detected overfitting.
If your model is overfitting, the app suggests these fixes:
| Fix | Where to Fix | Details |
|---|---|---|
| Increase the L2 regularization factor. For example, try increasing by a factor of 10. | In the Training Options section, select Show Advanced options. Then, expand Overfitting and change the L2Regularization training option. | Increasing L2 regularization penalizes large weights, encouraging
simpler models that generalize better to new data. For more information,
see L2Regularization. |
| Increase the dropout probability. For example, try increasing by 0.1. | Change the Dropout probability to a value greater than 0. This change is equivalent to adding dropout layers after each of the network blocks. | Adding dropout layers randomly deactivates neurons during training,
which prevents the model from becoming overly reliant on specific
pathways. For more information, see dropoutLayer |
| Use a decreasing learning rate schedule. For example, try using piecewise, polynomial, exponential, or cosine. | In the Training Options section, select
Show Advanced options. Then, expand
Learn Rate and change the
LearnRateSchedule training option. The
decreasing learn rate schedules are piecewise,
polynomial, exponential, and
cosine. | Using a decreasing learning rate schedule allows the model to make
smaller, more precise weight updates as training progresses. This type
of schedule helps the model to converge more smoothly and avoid
overshooting optimal solutions. For more information, see LearnRateSchedule. |
| Decrease the number of hidden units. For example, try decreasing the number of hidden units by 10%. | Reduce the Hidden units value. | Reducing the number of learnable parameters limits the capacity of the model to memorize training data, encouraging the model to capture only the most essential patterns that generalize well to new data. |
| Use a smaller network architecture. | In the Model gallery, select a different network. | Changing the network architecture allows you to choose a model that can learn relevant patterns while avoiding excessive memorization of training data. For example, choose one of the Small networks, which have fewer learnable parameters. |
Tips
By default, the app returns the model with the best validation loss. So, even if your network is overfitting at the end of training, the app can return a model at the point of no overfitting. The network returned by the app is equivalent to stopping training when the validation loss stops decreasing.
This panel is available only for the ARMA model.
After model training, the app produces anywhere between one to seven candidate
models. A plot displaying this set of candidate models and their respective metric
values appears on the Model Selector panel. At
the top of the plot, in the Metric menu, you can
choose the quality metric that you want the plot to display as
RMSE, NRMSE,
MAE, AIC, or
BIC. If you select Metric as RMSE,
NRMSE, or MAE, you can
select Open-loop or Closed-loop at the top right of the plot to display the respective
plots.
To the left of the plot, in the Models
section, you can choose all the models that you want to display. In the Datasets section, you can choose to display the
Training dataset,
Validation dataset, or both.
The plot automatically highlights the model with the lowest NRMSE value on training data in the closed-loop metric setting. You can also see that the app selects this model in the Select model list and displays its information in the text box below the plot. You can select a different model by clicking the model in the plot or selecting it in the Select model list.
After you select a model, click Apply to finalize the selection and complete the training process. After the app generates the candidate models, clicking Stop on the Train tab is equivalent to clicking Apply on the Model Selector panel.
For more information on model selection, see Train ARMA Model (System Identification Toolbox).
Click the Stop button to stop training the model. For deep learning models, you can still use the neural network even if you stop training early. The app returns the model with the best validation loss. For the ARMA model, if you click Stop before the app generates the candidate models, the app displays a training error. If you click Stop after the app generates the candidate models, the app finalizes the selected model and completes the training process.
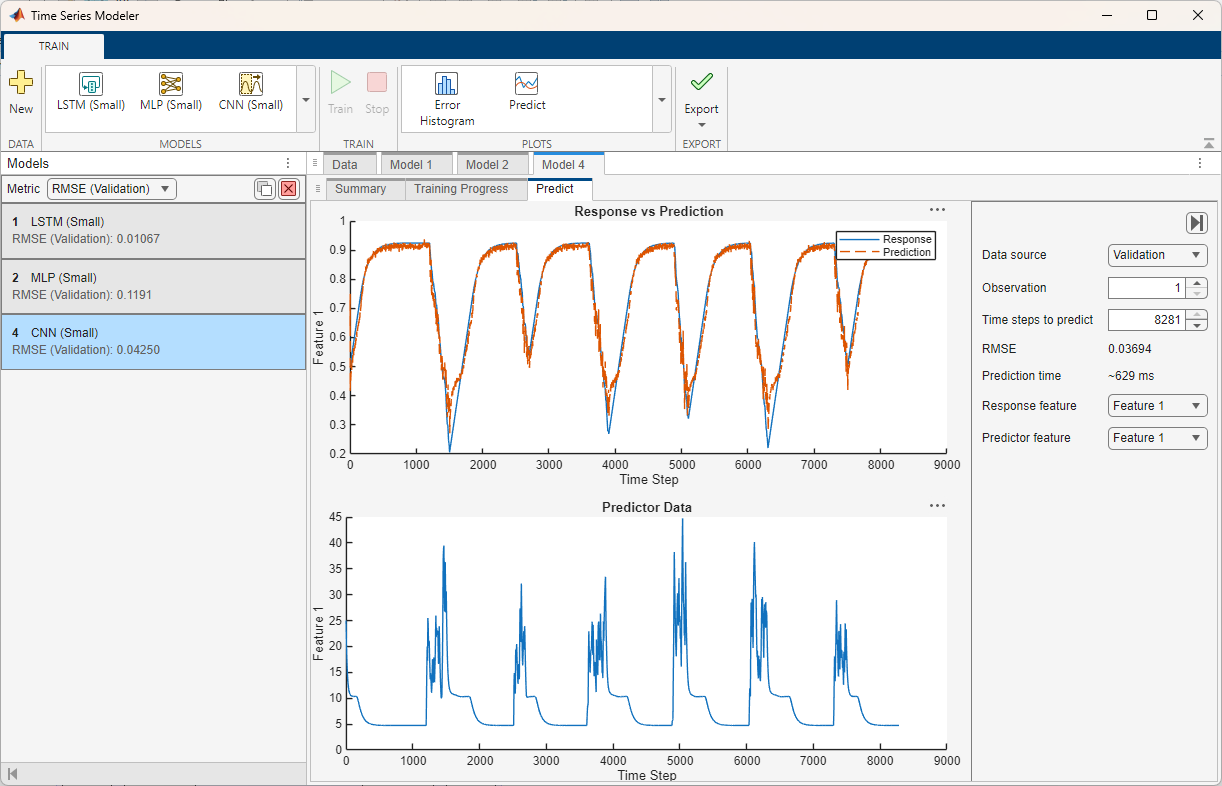
Click the Predict button to predict values for the training and validation data. In the Predict tab you can set these options: Prediction type, Data source, Observation, Time steps to predict, Response feature, Predictor feature, Use stateful prediction, and Sliding window length.
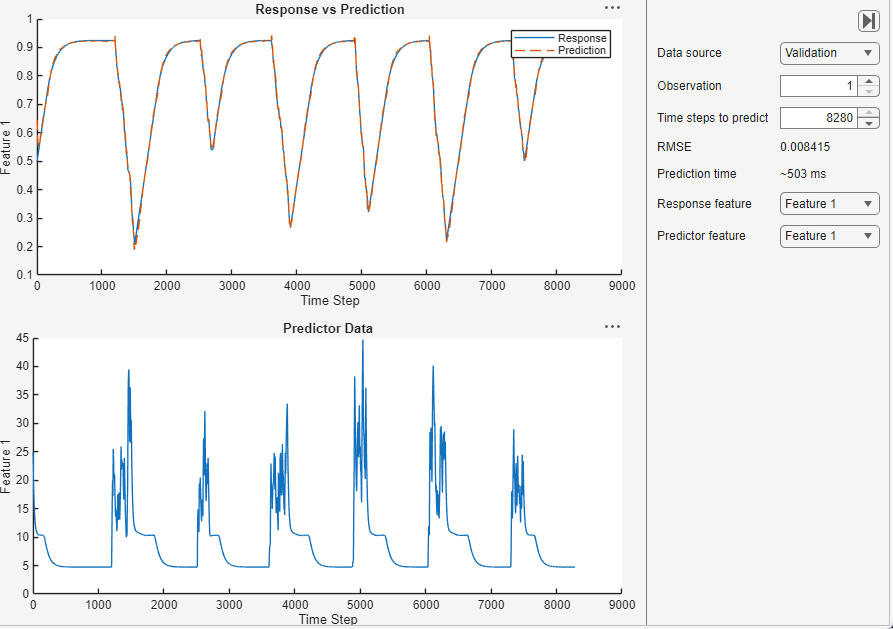
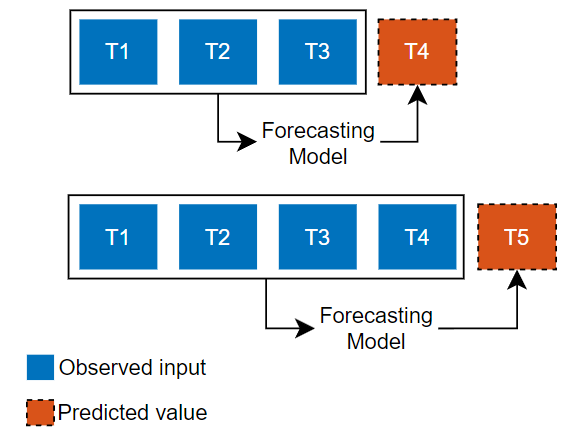
Use the Prediction type list to select the type of prediction.
| Open Loop | Closed Loop |
|---|---|
|
|
|
Predict the next time step in a sequence using only the input data. When making predictions for subsequent time steps, you collect the true values from your data source and use those as input. Use this type of prediction when you have true values to provide to the model before making the next prediction. For example, use this option if you want to predict the next day's temperature, where each day you can record the true temperature value and use it as input to your model. | Predict subsequent time steps in a sequence by using the previous predictions as input. In this case, the model does not require the true values to make the prediction. Use this type of prediction to predict multiple subsequent time steps or when you do not have the true values to provide to the RNN before making the next prediction. For example, use this option if you have a virtual sensor and do not have access to live values to use as input to your model at each time step. |
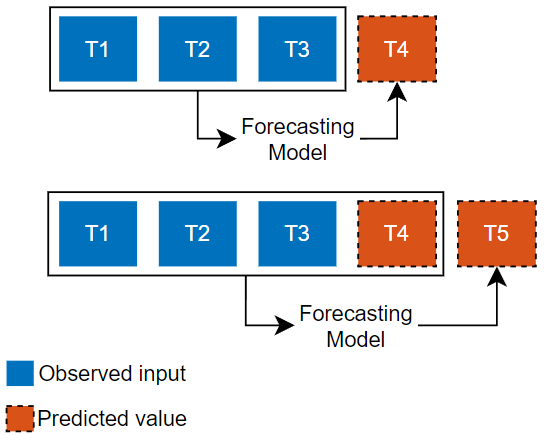
Dependencies
These options appear only when you select Use past values of responses as inputs (use an autoregressive model).
Use the Data source list to select which data to predict with. The performance of the model on the validation data is usually a more accurate reflection of how the model will perform on new data than the performance of the model on the training data.
This option is only available for deep learning models.
Select the Use stateful prediction check box to update the network state every iteration during closed loop prediction. Select this option if your model architecture supports statefulness (for example, LSTM or GRU) and you want to maintain the state of the network between iterations.
Dependencies
This options is available only if Prediction type is set to Closed loop.
The default Use stateful prediction value depends on the network and the Sliding window length value. For most networks, using stateful prediction with a sliding window length value greater than 1 will produce poor results. By default, the app does not use stateful prediction if the sliding window length is greater than one.
This option is only available for deep learning models.
Specify the number of time steps to use as input at each subsequent prediction step during closed loop prediction. After the initial prediction, the model slides through the time series as it makes predictions. Choose a window length that captures enough information to make the prediction. A window length that is too short can cause the model to miss trends, and a window length that is too long can add noise or complexity to the predictions. If you have only response data, then you might need a longer window length in order to make accurate predictions.
Dependencies
This options is available only if Prediction type is set to Closed loop.
Click the Error Histogram button to plot a histogram of the RMSE errors per time series, for either the training or validation data.
Use the Prediction type list to select the type of prediction. For more information, see Prediction type.
Use the Data source list to select which data to predict with. For more information, see Data source.
Dependencies
This plot is available only if your time series data contains multiple observations.
Click the Export button to export the trained model and the
training statistics to the MATLAB workspace and generate a live script for predicting on new data. For deep
learning models, the app exports a structure array that contains the model as a dlnetwork object. For the ARMA model,
the app exports a structure that contains an idpoly (System Identification Toolbox) model. The generated live script contains code for preparing and
normalizing data and predicting values for new data.
This button has the same effect as the Export button.
Click the Export to Simulink button to export the trained model to Simulink. For deep learning models, the app exports the model as layer blocks. For more information, see List of Deep Learning Layer Blocks and Subsystems. For the ARMA model, the app exports the model as an Idmodel (System Identification Toolbox) block. For more information, see Export Trained Model (System Identification Toolbox).
Algorithms
The app trains its models using a one‑step‑ahead sequence‑to‑sequence regression task. At each time step t, the model predicts the response, y(t), using your selected predictors ,x(t), and, if you choose to include it, the previous value of the response, y(t−1). This training setup shapes the strengths and limitations of each network type. For example, an MLP network can only learn one‑step relationships, while LSTM and GRU networks can use their internal state to capture longer‑term dependencies.
Version History
Introduced in R2026a