Regresión de secuencia a secuencia mediante deep learning
Este ejemplo muestra cómo predecir la vida útil restante (RUL) de motores mediante deep learning.
Para entrenar una red neuronal profunda con la que predecir valores numéricos a partir de series de tiempo o datos secuenciales, se puede utilizar una red de memoria de corto-largo plazo (LSTM).
Este ejemplo usa el conjunto de datos de simulación de degradación de motores de turbofán descrito en [1]. En el ejemplo se entrena una red de LSTM para predecir la vida útil restante de un motor (mantenimiento predictivo), medida en ciclos, dados los datos de series de tiempo que representan varios sensores del motor. Los datos de entrenamiento contienen datos de series de tiempo simuladas para 100 motores. Cada secuencia varía en longitud y corresponde a una instancia completa de funcionamiento hasta el fallo (RTF). Los datos de la prueba contienen 100 secuencias parciales y los correspondientes valores de la vida útil restante al final de cada secuencia.
El conjunto de datos contiene 100 observaciones de entrenamiento y 100 observaciones de prueba.
Descargar datos
Descargue y descomprima el conjunto de datos de simulación de degradación de motores de turbofán.
Cada serie de tiempo del conjunto de datos de simulación de degradación de motores turbofán representa un motor diferente. Cada motor comienza con grados desconocidos de desgaste inicial y variación de fabricación. El motor funciona con normalidad al inicio de cada serie de tiempo y desarrolla una avería en algún momento de la serie. En el conjunto de entrenamiento, la magnitud de la avería crece hasta convertirse en un fallo del sistema.
Los datos contienen un archivo de texto comprimido en ZIP con 26 columnas de números, separados por espacios. Cada fila es una instantánea de los datos tomados durante un único ciclo operativo, y cada columna es una variable diferente. Las columnas corresponden a lo siguiente:
Columna 1: número de unidad
Columna 2: tiempo en ciclos
Columnas 3-5: ajustes operativos
Columnas 6-26: mediciones de los sensores 1-21
Cree un directorio para guardar el conjunto de datos de simulación de degradación de motores de turbofán.
dataFolder = fullfile(tempdir,"turbofan"); if ~exist(dataFolder,"dir") mkdir(dataFolder); end
Descargue y extraiga el conjunto de datos de simulación de degradación de motores de turbofán.
filename = matlab.internal.examples.downloadSupportFile("nnet","data/TurbofanEngineDegradationSimulationData.zip"); unzip(filename,dataFolder)
Preparar datos de entrenamiento
Cargue los datos mediante la función processTurboFanDataTrain incluida en este ejemplo. La función processTurboFanDataTrain extrae los datos de filenamePredictors y devuelve un arreglo de celdas XTrain y TTrain, que contienen el predictor de entrenamiento y las secuencias de respuesta.
filenamePredictors = fullfile(dataFolder,"train_FD001.txt");
[XTrain,TTrain] = processTurboFanDataTrain(filenamePredictors);Eliminar características con valores constantes
Las características que permanecen constantes en todas las unidades de tiempo pueden influir de forma negativa en el entrenamiento. Encuentre las columnas de datos que tengan los mismos valores mínimo y máximo y elimínelas.
XTrainConcatenatedTimesteps = cat(1,XTrain{:});
m = min(XTrainConcatenatedTimesteps,[],1);
M = max(XTrainConcatenatedTimesteps,[],1);
idxConstant = M == m;
for i = 1:numel(XTrain)
XTrain{i}(:,idxConstant) = [];
endVisualice el número de características restantes en las secuencias.
numFeatures = size(XTrain{1},2)numFeatures = 17
Normalizar predictores de entrenamiento
Normalice los predictores de entrenamiento para que tengan media cero y varianza unitaria. Para calcular la media y la desviación estándar sobre todas las observaciones, concatene los datos secuenciales horizontalmente.
XTrainConcatenatedTimesteps = cat(1,XTrain{:});
mu = mean(XTrainConcatenatedTimesteps,1);
sig = std(XTrainConcatenatedTimesteps,0,1);
for i = 1:numel(XTrain)
XTrain{i} = (XTrain{i} - mu) ./ sig;
endRespuestas de recorte
Para obtener más información sobre los datos secuenciales cuando los motores están a punto de fallar, recorte las respuestas en el umbral de 150. Esto hace que la red trate como iguales las instancias con valores de RUL más altos.
thr = 150; for i = 1:numel(TTrain) TTrain{i}(TTrain{i} > thr) = thr; end
Esta figura muestra la primera observación y la respuesta recortada correspondiente.

Preparar datos para el relleno
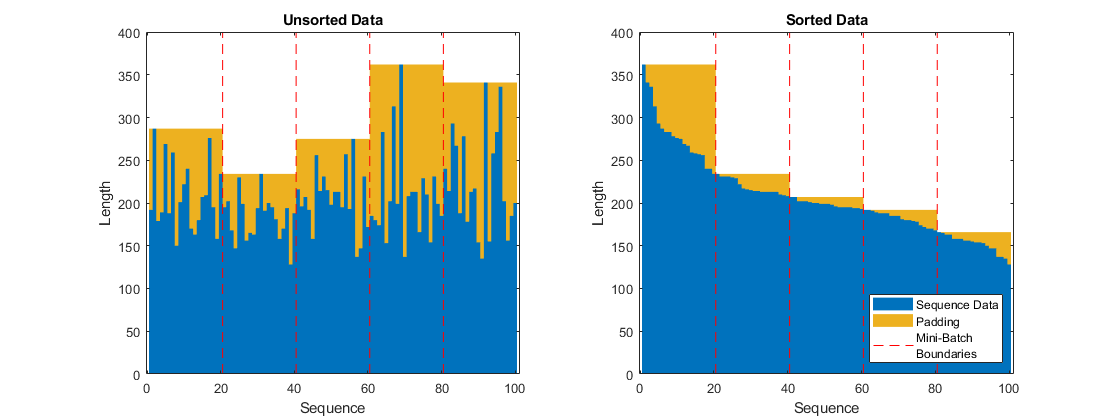
Para minimizar la cantidad de relleno que se añade a los minilotes, ordene los datos de entrenamiento por longitud de secuencia. A continuación, elija un tamaño de minilotes que divida los datos de entrenamiento de manera uniforme y reduzca la cantidad de relleno en los minilotes.
Ordene los datos de entrenamiento por longitud de secuencia.
for i=1:numel(XTrain) sequence = XTrain{i}; sequenceLengths(i) = size(sequence,1); end [sequenceLengths,idx] = sort(sequenceLengths,"descend"); XTrain = XTrain(idx); TTrain = TTrain(idx);
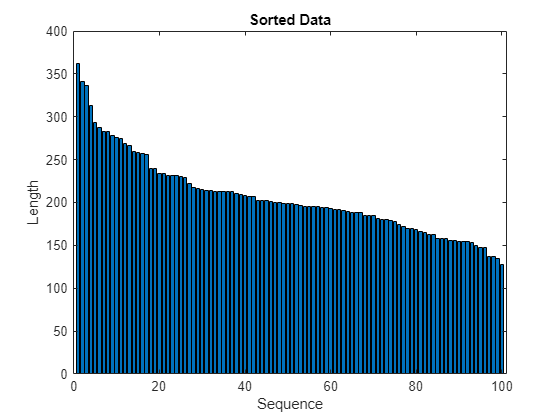
Visualice las longitudes de las secuencias ordenadas en una gráfica de barras.
figure bar(sequenceLengths) xlabel("Sequence") ylabel("Length") title("Sorted Data")
Elija un tamaño de minilotes que divida los datos de entrenamiento de manera uniforme y reduzca la cantidad de relleno en los minilotes. Esta figura ilustra el relleno añadido a las secuencias no clasificadas y clasificadas para minilotes de tamaño 20.
Definir la arquitectura de red
Defina la arquitectura de la red. Cree una red de LSTM que conste de una capa de LSTM con 200 unidades ocultas, seguida de una capa totalmente conectada de tamaño 50 y una capa de abandono con probabilidad de abandono del 0,5.
numResponses = size(TTrain{1},2);
numHiddenUnits = 200;
layers = [ ...
sequenceInputLayer(numFeatures)
lstmLayer(numHiddenUnits,OutputMode="sequence")
fullyConnectedLayer(50)
dropoutLayer(0.5)
fullyConnectedLayer(numResponses)];Especifique las opciones de entrenamiento. Entrene durante 60 épocas con minilotes de tamaño 20 mediante el solver "adam". Especifique una tasa de aprendizaje de 0,01. Para evitar que los gradientes exploten, establezca el umbral del gradiente en 1. Para mantener las secuencias ordenadas por su longitud, establezca la opción Shuffle en "never". Muestre el progreso del entrenamiento en una gráfica y monitorice la métrica de error cuadrático medio raíz (RMSE).
maxEpochs = 60; miniBatchSize = 20; options = trainingOptions("adam", ... MaxEpochs=maxEpochs, ... MiniBatchSize=miniBatchSize, ... InitialLearnRate=0.01, ... GradientThreshold=1, ... Shuffle="never", ... Metrics="rmse", ... Plots="training-progress", ... Verbose=0);
Entrenar la red
Entrene la red neuronal con la función trainnet. Para la regresión, utilice la pérdida de error cuadrático medio. De forma predeterminada, la función trainnet usa una GPU en caso de que esté disponible. Para entrenar en una GPU se requiere una licencia de Parallel Computing Toolbox™ y un dispositivo GPU compatible. Para obtener información sobre los dispositivos compatibles, consulte GPU Computing Requirements (Parallel Computing Toolbox). De lo contrario, la función trainnet usa la CPU. Para especificar el entorno de ejecución, utilice la opción de entrenamiento ExecutionEnvironment.
net = trainnet(XTrain,TTrain,layers,"mse",options);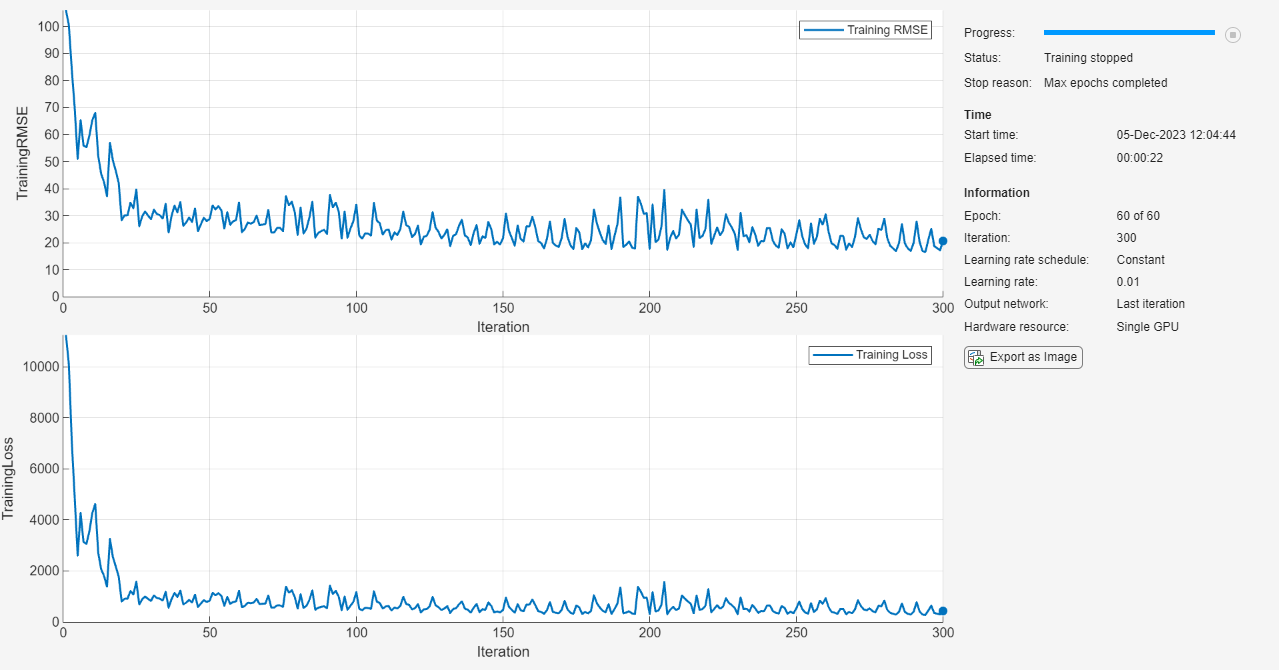
Probar la red
Prepare los datos de prueba mediante la función processTurboFanDataTest incluida en este ejemplo. La función processTurboFanDataTest extrae los datos de filenamePredictors y filenameResponses, y devuelve un arreglo de celdas XTest y TTest, que contienen el predictor de prueba y las secuencias de respuesta, respectivamente.
filenamePredictors = fullfile(dataFolder,"test_FD001.txt"); filenameResponses = fullfile(dataFolder,"RUL_FD001.txt"); [XTest,TTest] = processTurboFanDataTest(filenamePredictors,filenameResponses);
Elimine características con valores constantes con idxConstant, que se calcula a partir de los datos de entrenamiento. Normalice los predictores de prueba con los mismos parámetros que en los datos de entrenamiento. Recorte las respuestas de prueba según el mismo umbral que se ha utilizado en los datos de entrenamiento.
for i = 1:numel(XTest) XTest{i}(:,idxConstant) = []; XTest{i} = (XTest{i} - mu) ./ sig; TTest{i}(TTest{i} > thr) = thr; end
Realice predicciones con la red neuronal. Para hacer predicciones con varias observaciones, utilice la función minibatchpredict. La función minibatchpredict usa automáticamente una GPU en caso de que esté disponible. Para utilizar una GPU se requiere una licencia de Parallel Computing Toolbox™ y un dispositivo GPU compatible. Para obtener información sobre los dispositivos compatibles, consulte Requisitos de cálculo por GPU. De lo contrario, la función usa la CPU. Para que evitar que la función añada relleno a los datos, especifique un tamaño de minilote de 1. Para devolver predicciones en un arreglo de celdas, establezca UniformOutput en false.
YTest = minibatchpredict(net,XTest,MiniBatchSize=1,UniformOutput=false);
La red de LSTM hace predicciones sobre la secuencia parcial por cada unidad de tiempo. En cada unidad de tiempo, la red hace predicciones con el valor en la unidad en la que esté y el estado de la red, que se calcula solo según las unidades de tiempo anteriores. La red actualiza su estado entre cada predicción. La función minibatchpredict devuelve una secuencia de dichas predicciones. El último elemento de la predicción corresponde a la RUL predicha para la secuencia parcial.
Como alternativa, puede hacer predicciones de una unidad de tiempo cada vez con predict y actualizar la propiedad State de red. Esta opción resulta útil cuando se tienen los valores de las unidades de tiempo que llegan a un flujo. Por lo general, es más rápido hacer predicciones sobre secuencias completas en comparación con hacer predicciones de una unidad de tiempo cada vez. Para ver un ejemplo que muestra cómo pronosticar unidades de tiempo futuras actualizando la red entre predicciones de una sola unidad, consulte Pronóstico de series de tiempo mediante deep learning.
Visualice algunas de las predicciones en una gráfica.
idx = randperm(numel(YTest),4); figure for i = 1:numel(idx) subplot(2,2,i) plot(TTest{idx(i)},"--") hold on plot(YTest{idx(i)},".-") hold off ylim([0 thr + 25]) title("Test Observation " + idx(i)) xlabel("Time Step") ylabel("RUL") end legend(["Test Data" "Predicted"],Location="southeast")
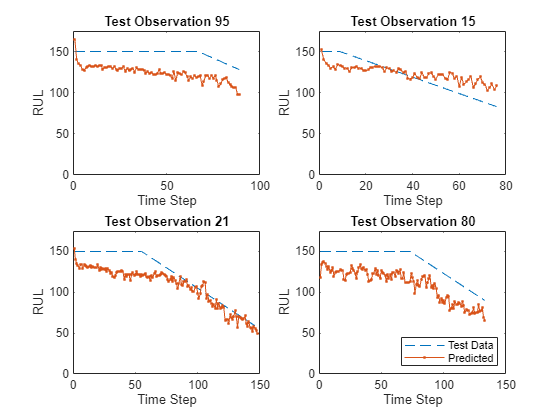
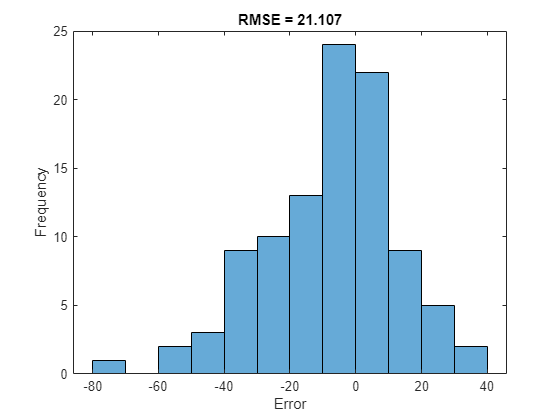
Para una secuencia parcial determinada, la RUL actual predicha es el último elemento de las secuencias predichas. Calcule el error cuadrático medio raíz (RMSE) de las predicciones y visualice el error de predicción en un histograma.
for i = 1:numel(TTest) TTestLast(i) = TTest{i}(end); YTestLast(i) = YTest{i}(end); end figure rmse = sqrt(mean((YTestLast - TTestLast).^2))
rmse = single
21.1070
histogram(YTestLast - TTestLast) title("RMSE = " + rmse) ylabel("Frequency") xlabel("Error")
Referencias
Saxena, Abhinav, Kai Goebel, Don Simon y Neil Eklund. "Damage propagation modeling for aircraft engine run-to-failure simulation". En Prognostics and Health Management, 2008. PHM 2008. International Conference on, págs. 1-9. IEEE, 2008.
Consulte también
trainnet | trainingOptions | dlnetwork | testnet | minibatchpredict | scores2label | predict | lstmLayer | sequenceInputLayer
Consulte también
Temas
- Regresión de secuencia a uno mediante deep learning
- Clasificación de secuencias mediante deep learning
- Pronóstico de series de tiempo mediante deep learning
- Clasificación secuencia a secuencia mediante deep learning
- Redes neuronales de memoria de corto-largo plazo
- Deep learning en MATLAB
- Choose Training Configurations for LSTM Using Bayesian Optimization