sequenceInputLayer
Capa de entrada de secuencias
Descripción
Una capa de entrada de secuencias introduce datos secuenciales en una red neuronal y aplica normalización de datos.
Creación
Descripción
layer = sequenceInputLayer(inputSize,Name=Value)
Argumentos de entrada
Argumentos de par nombre-valor
Propiedades
Ejemplos
Cree una capa de entrada de secuencias con un tamaño de entrada de 12.
layer = sequenceInputLayer(12)
layer =
SequenceInputLayer with properties:
Name: ''
InputSize: 12
MinLength: 1
SplitComplexInputs: 0
Hyperparameters
Normalization: 'none'
NormalizationDimension: 'auto'
Incluya una capa de entrada de secuencias en un arreglo Layer.
inputSize = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(inputSize) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numClasses) softmaxLayer]
layers =
4×1 Layer array with layers:
1 '' Sequence Input Sequence input with 12 dimensions
2 '' LSTM LSTM with 100 hidden units
3 '' Fully Connected 9 fully connected layer
4 '' Softmax softmax
Cree una capa de entrada de secuencias para secuencias de imágenes RGB 224-224 con el nombre 'seq1'.
layer = sequenceInputLayer([224 224 3], 'Name', 'seq1')
layer =
SequenceInputLayer with properties:
Name: 'seq1'
InputSize: [224 224 3]
MinLength: 1
SplitComplexInputs: 0
Hyperparameters
Normalization: 'none'
NormalizationDimension: 'auto'
Entrene una red de LSTM de deep learning para la clasificación secuencia a etiqueta.
Cargue los datos de ejemplo de WaveformData.mat. Los datos son un arreglo de celdas de numObservations por 1 de secuencias, donde numObservations es el número de secuencias. Cada secuencia es un arreglo numérico de numTimeSteps por numChannels, donde numTimeSteps es el número de unidades de tiempo de la secuencia y numChannels es el número de canales de la secuencia.
load WaveformDataVisualice algunas de las secuencias en una gráfica.
numChannels = size(data{1},2);
idx = [3 4 5 12];
figure
tiledlayout(2,2)
for i = 1:4
nexttile
stackedplot(data{idx(i)},DisplayLabels="Channel "+string(1:numChannels))
xlabel("Time Step")
title("Class: " + string(labels(idx(i))))
end
Visualice los nombres de las clases.
classNames = categories(labels)
classNames = 4×1 cell
{'Sawtooth'}
{'Sine' }
{'Square' }
{'Triangle'}
Reserve datos para pruebas. Divida los datos en un conjunto de entrenamiento que contenga el 90% de los datos y en un conjunto de prueba que contenga el 10% restante. Para dividir los datos, use la función trainingPartitions, incluida en este ejemplo como un archivo de soporte. Para acceder al archivo, abra el ejemplo como un script en vivo.
numObservations = numel(data); [idxTrain,idxTest] = trainingPartitions(numObservations, [0.9 0.1]); XTrain = data(idxTrain); TTrain = labels(idxTrain); XTest = data(idxTest); TTest = labels(idxTest);
Defina la arquitectura de la red de LSTM. Especifique el tamaño de la entrada como el número de canales de los datos de entrada. Especifique una capa de LSTM con 120 unidades ocultas y que genere el último elemento de la secuencia. Por último, incluya una totalmente conectada con un tamaño de salida que coincida con el número de clases, seguida de una capa softmax.
numHiddenUnits = 120; numClasses = numel(categories(TTrain)); layers = [ ... sequenceInputLayer(numChannels) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numClasses) softmaxLayer]
layers =
4×1 Layer array with layers:
1 '' Sequence Input Sequence input with 3 dimensions
2 '' LSTM LSTM with 120 hidden units
3 '' Fully Connected 4 fully connected layer
4 '' Softmax softmax
Especifique las opciones de entrenamiento. Entrene usando el solver Adam con una tasa de aprendizaje del 0.01 y un umbral de gradiente de 1. Establezca el número máximo de épocas en 200 y redistribuya el orden de cada época. De forma predeterminada, el software se entrena en una GPU, si se dispone de ella. Utilizar una GPU requiere Parallel Computing Toolbox y un dispositivo GPU compatible. Para obtener información sobre los dispositivos compatibles, consulte GPU Computing Requirements (Parallel Computing Toolbox).
options = trainingOptions("adam", ... MaxEpochs=200, ... InitialLearnRate=0.01,... Shuffle="every-epoch", ... GradientThreshold=1, ... Verbose=false, ... Metrics="accuracy", ... Plots="training-progress");
Entrene la red de LSTM con la función trainnet. Para la clasificación, utilice la pérdida de entropía cruzada.
net = trainnet(XTrain,TTrain,layers,"crossentropy",options);
Clasifique los datos de prueba. Especifique el mismo tamaño de minilote utilizado para el entrenamiento.
scores = minibatchpredict(net,XTest); YTest = scores2label(scores,classNames);
Calcule la precisión de clasificación de las predicciones.
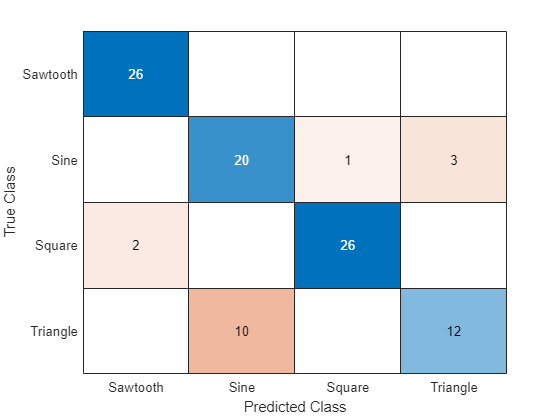
acc = mean(YTest == TTest)
acc = 0.8700
Muestre los resultados de la clasificación en una gráfica de confusión.
figure confusionchart(TTest,YTest)
Para crear una red de LSTM para la clasificación secuencia a etiqueta, cree un arreglo de capas que contenga una capa de entrada de secuencias, una capa de LSTM, una capa totalmente conectada y una capa softmax.
Establezca el tamaño de la capa de entrada de secuencias en el número de características de los datos de entrada. Establezca el tamaño de la capa totalmente conectada en el número de clases. No es necesario especificar la longitud de la secuencia.
Para la capa de LSTM, especifique el número de unidades ocultas y el modo de salida "last".
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numClasses) softmaxLayer];
Para ver un ejemplo de cómo entrenar una red de LSTM para una clasificación secuencia a etiqueta y clasificar nuevos datos, consulte Clasificación de secuencias mediante deep learning.
Para crear una red de LSTM para una clasificación secuencia a secuencia, utilice la misma arquitectura que para la clasificación secuencia a etiqueta, pero establezca el modo de salida de la capa de LSTM en "sequence".
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="sequence") fullyConnectedLayer(numClasses) softmaxLayer];
Para crear una red de LSTM para la regresión secuencia a uno, cree un arreglo de capas que contenga una capa de entrada de secuencias, una capa de LSTM y una capa totalmente conectada.
Establezca el tamaño de la capa de entrada de secuencias en el número de características de los datos de entrada. Establezca el tamaño de la capa totalmente conectada en el número de respuestas. No es necesario especificar la longitud de la secuencia.
Para la capa de LSTM, especifique el número de unidades ocultas y el modo de salida "last".
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numResponses)];
Para crear una red de LSTM para una regresión secuencia a secuencia, utilice la misma arquitectura que para la regresión secuencia a uno, pero establezca el modo de salida de la capa de LSTM en "sequence".
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="sequence") fullyConnectedLayer(numResponses)];
Para ver un ejemplo de cómo entrenar una red de LSTM para la regresión secuencia a secuencia y predecir nuevos datos, consulte Regresión de secuencia a secuencia mediante deep learning.
Puede hacer más profundas las redes de LSTM insertando capas de LSTM adicionales con el modo de salida "sequence" antes de la capa de LSTM. Para evitar un sobreajuste, puede insertar capas de abandono después de las capas de LSTM.
Para redes de clasificación secuencia a etiqueta, el modo de salida de la última capa de LSTM debe ser "last".
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,OutputMode="sequence") dropoutLayer(0.2) lstmLayer(numHiddenUnits2,OutputMode="last") dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer];
Para redes de clasificación secuencia a secuencia, el modo de salida de la última capa de LSTM debe ser "sequence".
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,OutputMode="sequence") dropoutLayer(0.2) lstmLayer(numHiddenUnits2,OutputMode="sequence") dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer];
Algoritmos
Capacidades ampliadas
Historial de versiones
Introducido en R2017bConsulte también
trainnet | trainingOptions | dlnetwork | minibatchpredict | predict | scores2label | lstmLayer | bilstmLayer | gruLayer | sequenceFoldingLayer | flattenLayer | featureInputLayer | Deep Network Designer | exportNetworkToSimulink | Rescale-Symmetric 1D | Rescale-Zero-One 1D | Zerocenter 1D | Zscore 1D
Temas
- Clasificación de secuencias mediante deep learning
- Pronóstico de series de tiempo mediante deep learning
- Clasificación secuencia a secuencia mediante deep learning
- Classify Videos Using Deep Learning
- Visualizar activaciones de redes de LSTM
- Redes neuronales de memoria de corto-largo plazo
- Deep learning en MATLAB
- Lista de capas de deep learning