Adopting MLOps at HSBC
Matt Barnes, HSBC
Discover how HSBC focused on implementing a MLOps process within their global risk analytics team. You’ll hear a summary of the history of model development practices and the pitfalls encountered along the way, and also explore:
- The need for change and a new focus on engineering
- The implementation challenge and story so far
- The push to cloud and unleashing the possibilities of scale
Published: 6 Oct 2021
Hello, I'm Matt Barnes from HSBC. Pleasure to meet everyone here today. Let me give you an overview of who I am, my experience, and background. And then I'll go into the reason why I'm here presenting to you today.
So I've been at the bank for over 20 years now with a lot of experience in technology. So I've worked from mainframe systems, email systems. I was involved in the bank's first implementation of websites at the end of the 1990s. And I've recently worked in supporting regulatory systems around finance, and over the past six or seven years, worked predominantly in supporting the business in delivering risk technologies to support their risk function.
I currently am the service line lead within global risk analytics. And we have about 200 people, sometimes a little bit more depending on projects, in various different locations around the globe with high focus on our engineering functions within India and China. And our purpose in life is to help the business in being able to manage, run, and deploy their risk models.
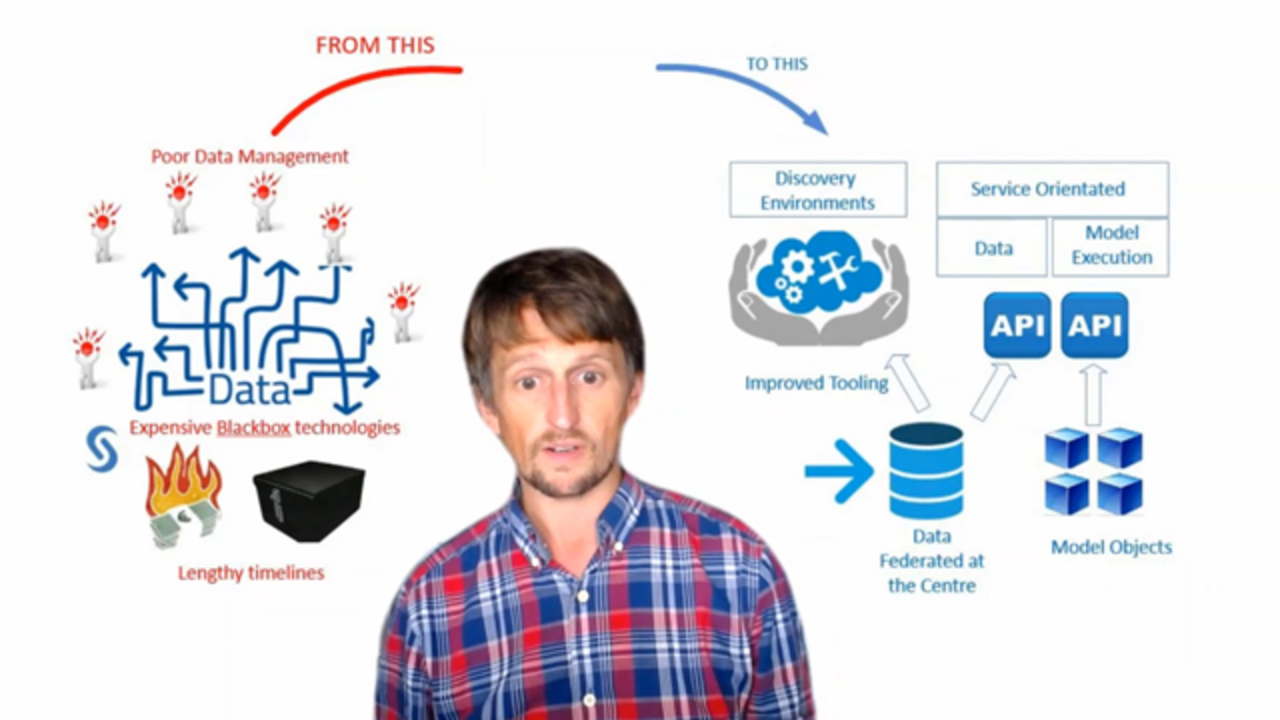
We're not a panacea. We don't do it for every area of the bank, but we're increasingly doing so. So why am I here today? So I'm here to talk to you about how we have moved over the past five or six years from this here, which is effectively our old legacy estate where we were involved in managing and supporting a lot of old blackbox technologies, some of them that we built in-house of this that we have been relying upon for many years provided by vendors with a very poor data environment that our modeling teams in the business were using and relying upon and struggling with, into something that looks more like this, which is very much a service-driven architecture with APIs, with a centralized data environment that can be trusted, and models that you can deploy like you can down a pipeline with standard application code.
So, as I mentioned, this has been a journey. It's our move effectively into MLOps in the similar way that we've moved applications into DevOps. When I joined GRA about five years ago, when we were in this particular state, I inherited a set of applications which weren't particularly well connected. The data environments that the business had were very sparse.
They had to rely on acquiring data from lots of different operational databases, old warehouses, pull it together in largely desktop-based environments, try and understand it, try and find the source system business team that could explain what the data was about, and then spend many weeks, if not months, pulling it together in order to build a model.
And the problem with that is that, nine times out of 10, the understanding of the data wasn't necessarily correct. That led to poor-quality decision-making around how the models were built, and it took a huge amount of time. And when that model needed to be redeveloped again, the same problem occurred where the new model went through that same process.
And sometimes it was taking the modeler probably 60%, 70% of their time in just getting access to data and preparing it, which is clearly not what we're paying them for. We want them to effectively use their modeling skills to produce good, quality models. The second problem we had was around the systems we use to run models. What we had was an environment, or set of environments, per model that weren't aligned, that have different technologies in the way in which they run models.
But the main common theme was that a model, for it to be operationalized, had to be converted from what the modeler had actually produced in the analytics environment into something that could be executed in the runtime environment. So that involved-- once the model had gone through the modeling process, got a model that had gone through review had been approved-- working with a business analyst who had to convert the very dense model documentation and into something that could be picked up by an implementation team, whether that's within my IT area or in another business unit who could then transcribe it into the operational environment.
And that could be done through different coding language. It could be through configuration. And what we've found is that, that, again, was a very lengthy process in the same way that the model development was, but also invariably ended up with a translation that wasn't quite the same as the modeler had put together in the first place.
And it had to be reconciled. It took a lot of time for the modeler to try and understand the differences. And ultimately, you were implementing something that took a long time to do. I wasn't exactly the same as what the model had put together in the first place.
So because we had a poor data operating model and environment and a very manual way in which we deployed models, our models were expensive to develop. Not particularly great in terms of some of the quality. And as a result, that led to certain scrutiny when it came to things like internal reviews and also sometimes regulatory reviews as well.
And you have to think the model space that I'm operating in predominantly in this particular example here for capital models, wholesale capital models. So these are highly regulated and used for approving lending to high-value corporate customers. So we knew we have to resolve these two particular areas.
On the data side, we move towards implementing a big data environment, a set of services that sat around it that allowed the business in a controlled way to move data from sources, reconcile back to source, prepare the data, and align it and federate it, and provide consumption layers that the modelers could trust with an appropriate set of data quality tools. And then the second area that we wanted to focus on is where we actually took the problem around models, and we wanted to apply engineering discipline in terms of how we took what the modelers were doing, and how we could deliver it in such a way that could be applied operationally without having to do an interim retranscription rebuild of that model for production execution.
And that's where we involved MathWorks and went into a partnership with them. So the business set up a research and development function in Cambridge and established co-located with MathWorks, an environment that allowed them to collaborate on a set of solutions around how we resolve that problem for model development and implementation. And through that, they decided that the best way to take this forward was to provide a toolbox with development environment.
We call it the MDE, which provided a structured way in which the modelers could produce a model, initially focusing on wholesale capital models, but not in such a way that meant it was restrictive around the particular technique or methodology that they were using to build the model, but in such a way that provided some structure in the way in which the model was described in terms of the inputs, the model function itself, and the model outputs, but meant that the output in the model artifacts could then be packaged in such a way that it could be deployed into a runtime environment without somebody coming in and having to try and translate it.
My team became involved from an IT perspective when we were looking at taking these models and running them in production services on our data center. So we worked with our colleagues in MathWorks to implement MATLAB Production Server on a set of initially test servers, understanding how that product worked, how models could be deployed onto it, but at the same time, working with a set of developers from third parties internally to build a application and service around our models that allowed them to be called and run and deployed so that operations teams around the bank that supported our relationship managers could go.
They could select a corporate customer. They could go through a rating approval process; and as part of that rating approval process, run the models that have been deployed. So we developed a microservice-based application with a from end above it that lab as operational teams to do exactly that-- select a customer and run a model, but in such a way that the model itself that was deployed had inside it, encapsulated within it, all of the metadata required for that model to run.
So all of the definition around the inputs. So when the model built the model, the packaging of it into an artifact that could be deployed into the MATLAB runtime environment in MATLAB Production Server had all of the descriptions around the model inputs; where those model inputs were coming from so that our service that sat above it could then interrogate a model when it needed to be run for a particular customer who needed to be rated, and then determine from the metadata what to display, for example, on the screen for the operator to capture what additional data could be obtained from source systems such as customer systems, spreading systems, and then collect all of that together so the model could be run.
And the advantage of what we developed effectively meant that a model could be changed. It could have new inputs. A new model could be developed and deployed. We did not have to change anything around the front end or the underlying services because of the metadata being encapsulated in the model. If you were to change some of the subjective questions, then the front end screens would read the model, understand that the questions have changed, and dynamically change the screen accordingly. And likewise, for any data that needed to be captured from a source, if additional information from that source needed to be collected, it will be described within the metadata of the model so it could go away and collect it.
So that then allowed us to migrate our models away from the old legacy environments, deploy it down a set of MATLAB production server environments, package them, use DevOps processes around Ansible so that we could then control the way in which models were moved through environments and into production. So we have effectively almost implemented a zero-touch, from an IT perspective, environment that allows models to be developed, packaged, moved through a series of MATLAB production server environments into production in a controlled way where the business have to go through and approve how that model gets moved, and prove that they have tested that particular model. And it's linked into our bank's formal change, control, processes, and mechanisms.
And now we have about 1,000 users, operators supporting our relationship managers in multiple countries, supporting our most material wholesale capital models that we use as part of the credit approval process for lending to large corporate customers. And we rate tens of thousands of customers, corporate customers, high-value corporate customers every single year now using this. And without it, we wouldn't have been able to deploy the models to the rate that we've been able to do and have the success that we have done in this particular service.
And now what we are doing is, on top of this, is looking to go further. And we now use MATLAB products elsewhere. So in parallel to a lot of this that happened in our wholesale capital model space, we've continued the partnership with MathWorks. We've implemented a monte carlo parallel compute implementation in Amazon for our economic capital and operational risk use cases that run on a quarterly basis.
And the advantage of using external cloud is that we can just stand up infrastructure as and when we need to use it at scale. So we can run through our quarterly batches at a much quicker time frame that we did on premise when we're constrained by a certain number of physical machines. So the run time is quicker.
So we can reduce the operational time it takes to run our quarterly processes, which means we've got more time to answer questions that the business may have on the results. And therefore, we de-risk the regulatory submissions that we have to make in terms of the timeline. And it also means it's more cost-effective because we're only running machines when we need to. These are quarterly batch processes. We can stand them down.
And MathWorks have worked very closely with us to ensure that the scripting that they have around their product works within our infrastructure scripting that deploys infrastructure inside our Amazon environment. Our new initiative is now looking at Google. So the bank's preferred partner in terms of cloud analytics is Google.
So we have now a new use case where we are looking at taking one of our capital models that's being deployed within our on-premise service, but running it instead of an operational system that relationship manager teams use online, running it in batch at scale on a monthly basis. And we need to run 200,000 model calculations for our Asia-Pacific region in under 20 minutes.
And we've been able through a proof of concept recently, been able to take data, prepare it using sort of scaled products within Google and then feedback through to a large pair of MATLAB Production Server engines and return back the results, and prepare the package back to the business in 20 minutes. In fact, it's under 20 minutes. So we've been able to prove that through working with Google, through working with MATLAB and our partners at MathWorks, that we've put together a solution here that we know can run at scale.
And next year, that will go into an operational execution. And we'll only be building now upon these kinds of technologies, this kind of approach for other model use cases and turning our attention, for example, to retail.
So this has been a huge success. Yes, we have moved from this to this in three or four years. But the value it brings to the bank and the materiality of it is significant. And just to let you know that the service I talked about in terms of these capital models, we have to, because of their materiality and the fact that the regulators have to approve each model, have to go and get approval for running this kind of technology and services with the regulators.
So the PRA and the ECB are aware of these services and have approved them for use for these material models. So that shows that we can implement things at scale using partners such as MathWorks and get them through a process that allows them to run very material models that has oversight and view from the regulators.
All right, well, that's everything about what we've done in terms of moving from our old state to our current. I hope that's been extremely useful. I'm now going to hand that over to Q&A. Thank you very much.
Featured Product
Financial Toolbox
Up Next:

Related Videos:






Seleccione un país/idioma
Seleccione un país/idioma para obtener contenido traducido, si está disponible, y ver eventos y ofertas de productos y servicios locales. Según su ubicación geográfica, recomendamos que seleccione: United States.
También puede seleccionar uno de estos países/idiomas:
América
- América Latina (Español)
- Canada (English)
- United States (English)
Europa
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)