Regresión lineal con una variable predictora
La regresión lineal simple describe la relación entre una única variable predictora y una variable de respuesta. Un modelo de regresión lineal es útil para comprender cómo los cambios en el predictor influyen en la respuesta.
En este ejemplo se muestra cómo ajustar, visualizar y validar modelos de regresión lineal simple de diversos grados utilizando las funciones polyfit y polyval. Para obtener información sobre cómo ajustar y visualizar un modelo utilizando la herramienta de ajuste básico en su lugar, consulte Ajuste interactivo.
Utilice la regresión lineal simple cuando:
Tenga una variable predictora.
La relación entre el predictor y la respuesta sea lineal en los coeficientes.
Desee cuantificar el efecto del predictor sobre la respuesta.
Representar datos
Comience representando los datos para identificar los posibles grados para el ajuste polinomial.
Por ejemplo, cree y visualice una variable predictora de muestra x y una variable de respuesta de muestra y. Esta visualización sugiere que un ajuste lineal o cuadrático podría describir la relación entre las variables predictoras y las variables de respuesta.
x = [0:0.5:5]'; y = [2.73 2.50 3.79 3.98 4.21 7.18 6.95 9.63 12.39 14.10 19.93]'; scatter(x,y)
Ajustar un modelo de primer grado
Ajuste un modelo (lineal) de primer grado a los datos utilizando la función polyfit. Especifique dos argumentos de salida para devolver los coeficientes polinomiales, así como la estructura de estimación de errores.
[pLinear,SLinear] = polyfit(x,y,1)
pLinear = 1×2
3.1316 0.1155
SLinear = struct with fields:
R: [2×2 double]
df: 9
normr: 6.3071
rsquared: 0.8715
Visualice el modelo ajustado.
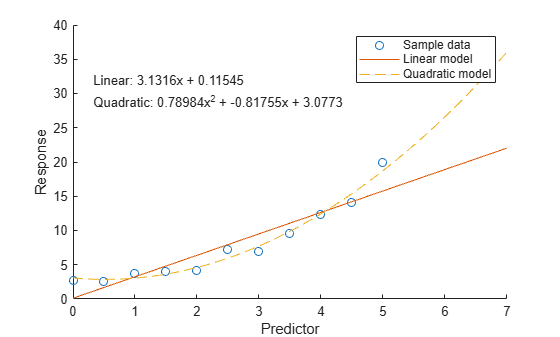
eqLinear = "Linear: " + pLinear(1) + "x + " + pLinear(2)
eqLinear = "Linear: 3.1316x + 0.11545"
Ajustar un modelo de mayor grado
Si un modelo de primer grado no describe correctamente la relación entre las variables predictoras y las variables de respuesta, puede ajustar un modelo de mayor grado. Por ejemplo, ajuste un modelo (cuadrático) de segundo grado a los datos utilizando la función polyfit. Especifique dos argumentos de salida para devolver los coeficientes polinomiales, así como la estructura de estimación de errores.
[pQuad,SQuad] = polyfit(x,y,2)
pQuad = 1×3
0.7898 -0.8175 3.0773
SQuad = struct with fields:
R: [3×3 double]
df: 8
normr: 2.5152
rsquared: 0.9796
Visualice el modelo ajustado.
eqQuad = "Quadratic: " + pQuad(1) + "x^2 + " + pQuad(2) + "x + " + pQuad(3)
eqQuad = "Quadratic: 0.78984x^2 + -0.81755x + 3.0773"
Comparar modelos
Para comparar modelos utilizando una gráfica, primero evalúe cada modelo en los puntos de consulta y devuelva los valores de respuesta pronosticados utilizando la función polyval. Luego, visualice los datos y ambos modelos.
Por ejemplo, obtenga los valores de respuesta para el modelo lineal y el modelo cuadrático en un rango más preciso de valores x.
xQuery = [0:0.05:7]'; yLinear = polyval(pLinear,xQuery); yQuad = polyval(pQuad,xQuery);
Si el modelo de mayor grado no predice bien los valores de respuesta, esto podría indicar un sobreajuste. Para obtener información sobre cómo validar el modelo y seleccionar la complejidad de modelo adecuada, consulte la sección Validar modelos.
Después, represente los datos de muestra y los datos del modelo.
scatter(x,y) hold on plot(xQuery,yLinear,"-") plot(xQuery,yQuad,"--") hold off xlabel("Predictor") ylabel("Response") legend(["Sample data" "Linear model" "Quadratic model"]) text(0.3,30,[eqLinear eqQuad])
Validar modelos
Para validar un modelo, calcule el coeficiente de determinación (R al cuadrado) o el coeficiente de determinación ajustado (R al cuadrado ajustado). Un valor cercano a 1 indica un buen ajuste.
Validar un modelo lineal con R al cuadrado
Para un modelo de primer grado, puede acceder al valor R al cuadrado utilizando la estructura de estimación de errores devuelta por la función polyfit. Por ejemplo, consulte el campo rsquared en SLinear.
linearR2 = SLinear.rsquared
linearR2 = 0.8715
Validar un modelo de mayor grado con R al cuadrado ajustado
En los modelos de mayor grado con más términos, el valor R al cuadrado suele aumentar, lo que indica un ajuste más preciso a los datos observados. Sin embargo, estos modelos tienen un mayor riesgo de que se produzca un sobreajuste.
El sobreajuste se produce cuando un modelo describe los datos originales (incluido el ruido) con demasiada precisión y no es un buen predictor de datos nuevos.
Para equilibrar la calidad de la predicción y la complejidad del modelo, considere validar el modelo utilizando el valor R al cuadrado ajustado, que incluye una penalización por el número de predictores. Puede calcular el valor R al cuadrado ajustado utilizando esta ecuación, donde es el valor del campo rsquared en la estructura de estimación de errores, es el número de observaciones de los datos y es el grado del modelo.
Por ejemplo, calcule el valor R al cuadrado ajustado para el modelo cuadrático.
quadAdjRsq = 1 - (1 - SQuad.rsquared) * (numel(y) - 1) / (numel(y) - 2 - 1)
quadAdjRsq = 0.9744
Calcular el error de predicción máximo para cada modelo
También puede validar un modelo calculando el error más grande entre las predicciones del modelo y los datos de muestra. Un error máximo pequeño en relación con los valores de los datos indica un buen ajuste.
Por ejemplo, calcule el error máximo para el modelo lineal y para el modelo cuadrático.
Lia = ismember(xQuery,x); linearMaxError = max(abs(yLinear(Lia) - y))
linearMaxError = 4.1564
quadMaxError = max(abs(yQuad(Lia) - y))
quadMaxError = 1.2926
Consulte también
Funciones
Temas
- Ajuste interactivo
- Linear Regression with Nonpolynomial Terms
- Linear Regression with Multiple Predictor Variables
- Crear y evaluar polinomios
- Linear Regression Workflow (Statistics and Machine Learning Toolbox)
- Ajustar modelos polinomiales (Curve Fitting Toolbox)