predict
(No recomendado) Predecir respuestas usando una red neuronal de deep learning entrenada
No se recomienda el uso de predict. Utilice la función minibatchpredict o predict (dlnetwork) en su lugar. Para obtener más información, consulte Historial de versiones.
Sintaxis
Descripción
Puede hacer predicciones usando una red neuronal entrenada para deep learning, tanto en una CPU como en una GPU. Utilizar una GPU requiere una licencia de Parallel Computing Toolbox™ y un dispositivo GPU compatible. Para obtener información sobre los dispositivos compatibles, consulte GPU Computing Requirements (Parallel Computing Toolbox). Especifique los requisitos de hardware mediante el argumento nombre-valor ExecutionEnvironment.
[ predice las respuestas de las Y1,...,YM] = predict(___)M salidas de una red multi-salida utilizando cualquiera de los argumentos de entrada anteriores. La salida Yj corresponde a la salida de red net.OutputNames(j). Para devolver salidas categóricas para las capas salida de clasificación, establezca la opción ReturnCategorical en 1 (verdadero).
___ = predict(___, predice las respuestas con opciones adicionales especificadas por uno o más argumentos de par nombre-valor.Name=Value)
Sugerencia
Utilice la función
predictpara predecir respuestas mediante una red de regresión o para clasificar datos con una red multi-salida. Para clasificar datos con una red de clasificación de una sola salida, use la funciónclassify.Al hacer predicciones con secuencias de diferentes tamaños, el tamaño de los minilotes puede influir en la cantidad de relleno que se añade a los datos de entrada, pudiendo dar como resultado valores predichos diferentes. Pruebe a utilizar valores distintos para ver cuál se adapta mejor a su red. Para especificar los tamaños de los minilotes y las opciones de relleno, utilice las opciones
MiniBatchSizeySequenceLength, respectivamente.Para predecir respuestas usando objetos
dlnetwork, consultepredict.
Ejemplos
Prediga las respuestas numéricas usando una red neuronal convolucional entrenada
Cargue una red neuronal SqueezeNet preentrenada.
net = squeezenet;
Lea y muestre una imagen de ejemplo.
I = imread("peppers.png");
figure
imshow(I)
Cambie el tamaño de la imagen al tamaño de entrada de la red.
sz = net.Layers(1).InputSize; I = imresize(I,sz(1:2));
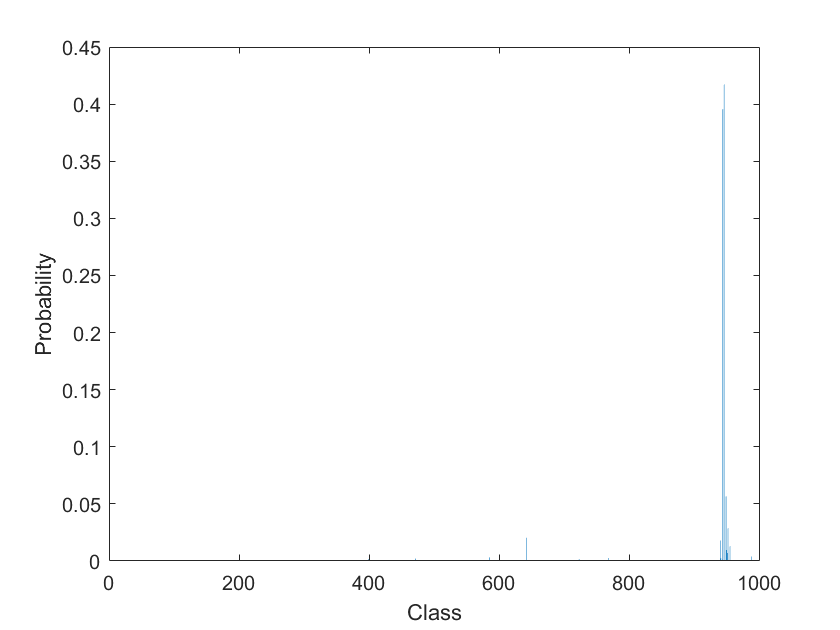
Realice predicciones con la función predict. Dado que la red es una red de clasificación, la salida de la función predict son las probabilidades de clase. Para las redes de regresión, la función produce como salida las respuestas numéricas predichas.
Y = predict(net,I);
Muestre las probabilidades en una gráfica de barras.
figure bar(Y) xlabel("Class") ylabel("Probability")
Argumentos de entrada
Red entrenada, especificada como un objeto SeriesNetwork o DAGNetwork. Puede obtener una red entrenada importando una red preentrenada (por ejemplo, utilizando la función googlenet) o entrenando su propia red mediante trainNetwork.
Para obtener información sobre la predicción de respuestas con objetos dlnetwork, consulte predict.
Datos de imágenes, especificados como una de las siguientes opciones:
| Tipo de datos | Descripción | Ejemplo de uso | |
|---|---|---|---|
| Almacén de datos | ImageDatastore | Almacén de datos de imágenes guardadas en disco | Hacer predicciones con imágenes guardadas en disco, donde las imágenes tienen el mismo tamaño. Si las imágenes tienen diferentes tamaños, use un objeto |
augmentedImageDatastore | Almacén de datos que aplica transformaciones geométricas afines aleatorias, incluyendo cambio de tamaño, rotación, reflexión, estiramiento y traslación | Hacer predicciones con imágenes guardadas en disco, donde las imágenes tienen distinto tamaño. | |
TransformedDatastore | Almacén de datos que transforma lotes de datos leídos de un almacén de datos subyacente mediante una función de transformación personalizada |
| |
CombinedDatastore | Almacén de datos que lee de dos o más almacenes de datos subyacentes |
| |
| Almacén de datos de minilotes personalizado | Almacén de datos personalizado que devuelve minilotes de datos | Hacer predicciones usando datos en un formato no compatible con otros almacenes de datos. Para obtener más detalles, consulte Develop Custom Mini-Batch Datastore. | |
| Arreglo numérico | Imágenes especificadas como arreglo numérico | Hacer predicciones usando datos que quepan en la memoria y no requieran procesamiento adicional, como un cambio de tamaño. | |
| Tabla | Imágenes especificadas como tabla | Hacer predicciones usando datos guardados en una tabla. | |
Cuando utiliza un almacén de datos con redes con varias entradas, el almacén de datos debe ser un objeto TransformedDatastore o CombinedDatastore.
Sugerencia
Para secuencias de imágenes, por ejemplo, datos de vídeo, use el argumento de entrada sequences.
Almacén de datos
Los almacenes de datos leen minilotes de imágenes y respuestas. Use almacenes de datos cuando tenga datos que no caben en la memoria o cuando quiera cambiar el tamaño de los datos de entrada.
Estos almacenes de datos son directamente compatibles con predict para datos de imágenes:
Almacén de datos de minilotes personalizado. Para obtener más detalles, consulte Develop Custom Mini-Batch Datastore.
Sugerencia
Use augmentedImageDatastore para preprocesar eficiente de las imágenes para deep learning, incluyendo el cambio de tamaño de las imágenes. No use la opción ReadFcn de objetos ImageDatastore.
ImageDatastore permite leer lotes de archivos de imágenes JPG o PNG mediante precarga. Si establece la opción ReadFcn como una función personalizada, ImageDatastore no realiza la precarga y suele ser bastante más lenta.
Puede utilizar otros almacenes de datos integrados para hacer predicciones mediante las funciones transform y combine. Estas funciones pueden convertir los datos leídos de almacenes de datos al formato requerido por classify.
El formato requerido de la salida del almacén de datos depende de la arquitectura de red.
| Arquitectura de red | Salida del almacén de datos | Ejemplo de salida |
|---|---|---|
| Entrada única | Tabla o arreglo de celdas, donde la primera columna especifica los predictores. Los elementos de la tabla deben ser escalares, vectores fila o arreglos de celdas de 1 por 1 que contengan un arreglo numérico. Los almacenes de datos personalizados deben producir tablas como salida. | data = read(ds) data =
4×1 table
Predictors
__________________
{224×224×3 double}
{224×224×3 double}
{224×224×3 double}
{224×224×3 double}
|
data = read(ds) data =
4×1 cell array
{224×224×3 double}
{224×224×3 double}
{224×224×3 double}
{224×224×3 double} | ||
| Varias entradas | Arreglo de celdas con al menos Las primeras El orden de las entradas se indica mediante la propiedad | data = read(ds) data =
4×2 cell array
{224×224×3 double} {128×128×3 double}
{224×224×3 double} {128×128×3 double}
{224×224×3 double} {128×128×3 double}
{224×224×3 double} {128×128×3 double} |
El formato de los predictores depende del tipo de datos.
| Datos | Formato |
|---|---|
| Imágenes 2D | Arreglo numérico de h por w por c, donde h, w y c son la altura, la anchura y el número de canales de las imágenes, respectivamente |
| Imágenes 3D | Arreglo numérico de h por w por d por c, donde h, w, d y c son la altura, la anchura, la profundidad y el número de canales de las imágenes, respectivamente |
Para obtener más información, consulte Datastores for Deep Learning.
Arreglo numérico
Para datos que quepan en la memoria y no requieran procesamiento adicional, como aumento, puede especificar un conjunto de datos de imágenes como arreglo numérico.
El tamaño y la forma del arreglo numérico dependen del tipo de datos de imágenes.
| Datos | Formato |
|---|---|
| Imágenes 2D | Arreglo numérico de h por w por c por N, en el que h, w y c son la altura, la anchura y el número de canales de las imágenes, respectivamente, y N es el número de imágenes |
| Imágenes 3D | Arreglo numérico de h por w por d por c por N, en el que h, w, d y c son la altura, la anchura, la profundidad y el número de canales de las imágenes, respectivamente, y N es el número de imágenes |
Tabla
Como alternativa a los almacenes de datos o arreglos numéricos, también puede especificar imágenes en una tabla.
Cuando especifica imágenes en una tabla, cada fila de la tabla corresponde a una observación.
Para entradas de imagen, los predictores deben estar en la primera columna de la tabla, especificados como una de las siguientes opciones:
Ruta de archivo absoluta o relativa a una imagen, especificada como vector de caracteres.
Arreglo de celdas de 1 por 1 con un arreglo numérico de h por w por c que represente una imagen 2D, donde h, w y c corresponden a la altura, la anchura y el número de canales de la imagen, respectivamente.
Sugerencia
Este argumento admite predictores de valores complejos. Para introducir datos de valores complejos en un objeto SeriesNetwork o DAGNetwork, la opción SplitComplexInputs de la capa de entrada debe ser 1 (true).
Secuencia o datos de series de tiempo, especificados como una de las siguientes opciones:
| Tipo de datos | Descripción | Ejemplo de uso | |
|---|---|---|---|
| Almacén de datos | TransformedDatastore | Almacén de datos que transforma lotes de datos leídos de un almacén de datos subyacente mediante una función de transformación personalizada |
|
CombinedDatastore | Almacén de datos que lee de dos o más almacenes de datos subyacentes |
| |
| Almacén de datos de minilotes personalizado | Almacén de datos personalizado que devuelve minilotes de datos | Hacer predicciones usando datos en un formato no compatible con otros almacenes de datos. Para obtener más detalles, consulte Develop Custom Mini-Batch Datastore. | |
| Arreglo numérico o de celdas | Una única secuencia especificada como arreglo numérico o un conjunto de datos de secuencias especificado como arreglo de celdas de arreglos numéricos | Hacer predicciones usando datos que quepan en la memoria y no requieran procesamiento adicional, como transformaciones personalizadas. | |
Almacén de datos
Los almacenes de datos leen minilotes de secuencias y respuestas. Use almacenes de datos cuando tenga datos que no caben en la memoria o cuando quiera aplicar transformaciones a los datos.
Estos almacenes de datos son directamente compatibles con predict para datos secuenciales:
Almacén de datos de minilotes personalizado. Para obtener más detalles, consulte Develop Custom Mini-Batch Datastore.
Puede utilizar otros almacenes de datos integrados para hacer predicciones mediante las funciones transform y combine. Estas funciones pueden convertir los datos leídos de almacenes de datos al formato de tabla o arreglo de celdas requerido por predict. Por ejemplo, puede transformar y combinar datos leídos de arreglos en memoria y archivos CVS mediante un objeto ArrayDatastore y un objeto TabularTextDatastore, respectivamente.
El almacén de datos debe devolver datos en una tabla o arreglo de celdas. Los almacenes de datos de minilotes personalizados deben producir tablas como salida.
| Salida del almacén de datos | Ejemplo de salida |
|---|---|
| Tabla | data = read(ds) data =
4×2 table
Predictors
__________________
{12×50 double}
{12×50 double}
{12×50 double}
{12×50 double} |
| Arreglo de celdas | data = read(ds) data =
4×2 cell array
{12×50 double}
{12×50 double}
{12×50 double}
{12×50 double} |
El formato de los predictores depende del tipo de datos.
| Datos | Formato de los predictores |
|---|---|
| Secuencia de vector | Matriz de c por s, donde c es el número de características de la secuencia y s es la longitud de la secuencia |
| Secuencia de imágenes 1D | Arreglo de h por c por s, donde h y c corresponden a la altura y el número de canales de la imagen, respectivamente, y s es la longitud de la secuencia. Cada secuencia del minilote debe tener la misma longitud de secuencia. |
| Secuencia de imágenes 2D | Arreglo de h por w por c por s, donde h, w y c corresponden a la altura, la anchura y el número de canales de la imagen, respectivamente, y s es la longitud de la secuencia. Cada secuencia del minilote debe tener la misma longitud de secuencia. |
| Secuencia de imágenes 3D | Arreglo de h por w por d por c por s, donde h, w, d y c corresponden a la altura, la anchura, la profundidad y el número de canales de la imagen, respectivamente, y s es la longitud de la secuencia. Cada secuencia del minilote debe tener la misma longitud de secuencia. |
Para predictores devueltos en tablas, los elementos deben contener un escalar numérico, un vector fila numérico o un arreglo de celdas de 1 por 1 con un arreglo numérico.
Para obtener más información, consulte Datastores for Deep Learning.
Arreglo numérico o de celdas
Para datos que quepan en la memoria y no requieran procesamiento adicional, como transformaciones personalizadas, puede especificar una única secuencia como arreglo numérico o un conjunto de datos de secuencias como un arreglo de celdas de arreglos numéricos.
Para entradas en forma de arreglo de celdas, el arreglo de celdas debe ser un arreglo de celdas de N por 1 de arreglos numéricos, donde N es el número de observaciones. El tamaño y la forma del arreglo numérico que representa una secuencia depende del tipo de datos secuenciales.
| Entrada | Descripción |
|---|---|
| Secuencias de vectores | Matrices de c por s, donde c es el número de características de las secuencias y s es la longitud de la secuencia |
| Secuencias de imágenes 1D | Arreglos de h por c por s, donde h y c corresponden a la altura y el número de canales de las imágenes, respectivamente, y s es la longitud de la secuencia |
| Secuencias de imágenes 2D | Arreglos de h por w por c por s, donde h, w y c corresponden a la altura, la anchura y el número de canales de las imágenes, respectivamente, y s es la longitud de la secuencia |
| Secuencias de imágenes 3D | Arreglos de h por w por d por c por s, donde h, w, d y c corresponden a la altura, la anchura, la profundidad y el número de canales de las imágenes 3D, respectivamente, y s es la longitud de la secuencia |
Sugerencia
Este argumento admite predictores de valores complejos. Para introducir datos de valores complejos en un objeto SeriesNetwork o DAGNetwork, la opción SplitComplexInputs de la capa de entrada debe ser 1 (true).
Datos de características, especificados como una de las siguientes opciones:
| Tipo de datos | Descripción | Ejemplo de uso | |
|---|---|---|---|
| Almacén de datos | TransformedDatastore | Almacén de datos que transforma lotes de datos leídos de un almacén de datos subyacente mediante una función de transformación personalizada |
|
CombinedDatastore | Almacén de datos que lee de dos o más almacenes de datos subyacentes |
| |
| Almacén de datos de minilotes personalizado | Almacén de datos personalizado que devuelve minilotes de datos | Hacer predicciones usando datos en un formato no compatible con otros almacenes de datos. Para obtener más detalles, consulte Develop Custom Mini-Batch Datastore. | |
| Tabla | Datos de características especificados como una tabla | Hacer predicciones usando datos guardados en una tabla. | |
| Arreglo numérico | Datos de características especificados como un arreglo numérico | Hacer predicciones usando datos que quepan en la memoria y no requieran procesamiento adicional, como transformaciones personalizadas. | |
Almacén de datos
Los almacenes de datos leen minilotes de datos de características y respuestas. Use almacenes de datos cuando tenga datos que no caben en la memoria o cuando quiera aplicar transformaciones a los datos.
Estos almacenes de datos son directamente compatibles con predict para datos de características:
Almacén de datos de minilotes personalizado. Para obtener más detalles, consulte Develop Custom Mini-Batch Datastore.
Puede utilizar otros almacenes de datos integrados para hacer predicciones mediante las funciones transform y combine. Estas funciones pueden convertir los datos leídos de almacenes de datos al formato de tabla o arreglo de celdas requerido por predict. Para obtener más información, consulte Datastores for Deep Learning.
Para redes con varias entradas, el almacén de datos debe ser un objeto TransformedDatastore o CombinedDatastore.
El almacén de datos debe devolver datos en una tabla o arreglo de celdas. Los almacenes de datos de minilotes personalizados deben producir tablas como salida. El formato de la salida del almacén de datos depende de la arquitectura de red.
| Arquitectura de red | Salida del almacén de datos | Ejemplo de salida |
|---|---|---|
| Capa de entrada única | Tabla o arreglo de celdas con al menos una columna, donde la primera columna especifica los predictores. Los elementos de la tabla deben ser escalares, vectores fila o arreglos de celdas de 1 por 1 que contengan un arreglo numérico. Los almacenes de datos de minilotes personalizados deben producir tablas como salida. | Tabla para red con una entrada: data = read(ds) data =
4×2 table
Predictors
__________________
{24×1 double}
{24×1 double}
{24×1 double}
{24×1 double}
|
Arreglo de celdas para red con una entrada:
data = read(ds) data =
4×1 cell array
{24×1 double}
{24×1 double}
{24×1 double}
{24×1 double} | ||
| Capas de entrada múltiples | Arreglo de celdas con al menos Las primeras El orden de las entradas se indica mediante la propiedad | Arreglo de celdas para red con dos entradas: data = read(ds) data =
4×3 cell array
{24×1 double} {28×1 double}
{24×1 double} {28×1 double}
{24×1 double} {28×1 double}
{24×1 double} {28×1 double} |
Los predictores deben ser vectores columna de c por 1, donde c es el número de características.
Para obtener más información, consulte Datastores for Deep Learning.
Tabla
Para datos de características que quepan en la memoria y no requieran procesamiento adicional, como transformaciones personalizadas, puede especificar datos de características y respuestas como una tabla.
Cada fila de la tabla corresponde a una observación. La disposición de los predictores en las columnas de la tabla depende del tipo de tarea.
| Tarea | Predictores |
|---|---|
| Clasificación de características | Características especificadas en una o más columnas como escalares. |
Arreglo numérico
Para datos de características que quepan en la memoria y no requieran procesamiento adicional, como transformaciones personalizadas, puede especificar datos de características como un arreglo numérico.
El arreglo numérico debe ser un arreglo numérico de N por numFeatures, donde N es el número de observaciones y numFeatures es el número de características de los datos de entrada.
Sugerencia
Este argumento admite predictores de valores complejos. Para introducir datos de valores complejos en un objeto SeriesNetwork o DAGNetwork, la opción SplitComplexInputs de la capa de entrada debe ser 1 (true).
Arreglos numéricos o de celdas para redes con varias entradas.
Para entradas de predictor de imagen, secuencia y característica, el formato de los predictores debe coincidir con los formatos descritos en las descripciones de los argumentos images, sequences o features, respectivamente.
Para ver un ejemplo de cómo entrenar una red con varias entradas, consulte Entrenar una red con datos de características y de imagen.
Para introducir datos de valores complejos en un objeto DAGNetwork o SeriesNetwork, la opción SplitComplexInputs de la capa de entrada debe ser 1 (true).
Tipos de datos: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64 | cell
Soporte de números complejos: Sí
Datos mezclados, especificados como una de las siguientes opciones:
| Tipo de datos | Descripción | Ejemplo de uso |
|---|---|---|
TransformedDatastore | Almacén de datos que transforma lotes de datos leídos de un almacén de datos subyacente mediante una función de transformación personalizada |
|
CombinedDatastore | Almacén de datos que lee de dos o más almacenes de datos subyacentes |
|
| Almacén de datos de minilotes personalizado | Almacén de datos personalizado que devuelve minilotes de datos | Hacer predicciones usando datos en un formato no compatible con otros almacenes de datos. Para obtener más detalles, consulte Develop Custom Mini-Batch Datastore. |
Puede utilizar otros almacenes de datos integrados para hacer predicciones mediante las funciones transform y combine. Estas funciones pueden convertir los datos leídos de almacenes de datos al formato de tabla o arreglo de celdas requerido por predict. Para obtener más información, consulte Datastores for Deep Learning.
El almacén de datos debe devolver datos en una tabla o arreglo de celdas. Los almacenes de datos de minilotes personalizados deben producir tablas como salida. El formato de la salida del almacén de datos depende de la arquitectura de red.
| Salida del almacén de datos | Ejemplo de salida |
|---|---|
Arreglo de celdas con El orden de las entradas se indica mediante la propiedad | data = read(ds) data =
4×3 cell array
{24×1 double} {28×1 double}
{24×1 double} {28×1 double}
{24×1 double} {28×1 double}
{24×1 double} {28×1 double} |
Para entradas de predictor de imagen, secuencia y característica, el formato de los predictores debe coincidir con los formatos descritos en las descripciones de los argumentos images, sequences o features, respectivamente.
Para ver un ejemplo de cómo entrenar una red con varias entradas, consulte Entrenar una red con datos de características y de imagen.
Sugerencia
Para convertir un arreglo numérico a un almacén de datos, use arrayDatastore.
Argumentos de par nombre-valor
Especifique pares de argumentos opcionales como Name1=Value1,...,NameN=ValueN, donde Name es el nombre del argumento y Value es el valor correspondiente. Los argumentos de nombre-valor deben aparecer después de otros argumentos. Sin embargo, el orden de los pares no importa.
En las versiones anteriores a la R2021a, use comas para separar cada nombre y valor, y encierre Name entre comillas.
Ejemplo: MiniBatchSize=256 especifica el tamaño de minilote como 256.
Tamaño de los minilotes utilizados durante la predicción, especificado como un entero positivo. Un tamaño de minilote mayor requiere más memoria, pero puede proporcionar predicciones más rápidas.
Al hacer predicciones con secuencias de diferentes tamaños, el tamaño de los minilotes puede influir en la cantidad de relleno que se añade a los datos de entrada, pudiendo dar como resultado valores predichos diferentes. Pruebe a utilizar valores distintos para ver cuál se adapta mejor a su red. Para especificar los tamaños de los minilotes y las opciones de relleno, utilice las opciones MiniBatchSize y SequenceLength, respectivamente.
Tipos de datos: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Optimización de rendimiento, especificada como una de las siguientes opciones:
"auto": aplicar automáticamente un número de optimizaciones adecuado para la red de entrada y los recursos de hardware."mex": compilar y ejecutar una función MEX. Esta opción solo está disponible cuando usa una GPU. Utilizar una GPU requiere una licencia de Parallel Computing Toolbox y un dispositivo GPU compatible. Para obtener información sobre los dispositivos compatibles, consulte GPU Computing Requirements (Parallel Computing Toolbox). Si no está disponible Parallel Computing Toolbox o una GPU adecuada, el software devuelve un error."none": deshabilitar toda la aceleración.
Si Acceleration es "auto", MATLAB® aplica un número de optimizaciones compatibles y no genera una función MEX.
Las opciones "auto" y "mex" pueden ofrecer beneficios de rendimiento a costa de un mayor tiempo de ejecución inicial. Las siguientes llamadas con parámetros compatibles son más rápidas. Utilice la optimización de rendimiento cuando planee llamar a la función varias veces con nuevos datos de entrada.
La opción "mex" genera y ejecuta una función MEX basada en la red y en parámetros utilizados en la llamada a la función. Puede tener varias funciones MEX asociadas a una única red al mismo tiempo. Borrando la variable de red también se borra cualquier función MEX asociada a esa red.
La opción "mex" es compatible con redes que contienen las capas que aparecen en la página Supported Layers (GPU Coder), excepto los objetos sequenceInputLayer.
La opción "mex" está disponible cuando usa una única GPU.
Para usar la opción "mex", debe tener instalado un compilador C/C++ y el paquete de soporte GPU Coder™ Interface for Deep Learning. Instale el paquete de soporte usando Add-On Explorer en MATLAB. Para obtener instrucciones de configuración, consulte Set Up Compiler (GPU Coder). No se requiere GPU Coder.
Para las redes cuantificadas, la opción "mex" requiere una GPU NVIDIA® habilitada para CUDA® con capacidad de cálculo 6.1, 6.3 o superior.
MATLAB Compiler™ no es compatible con el despliegue de redes cuando utiliza la opción "mex".
Recurso de hardware, especificado como una de las siguientes opciones:
"auto": usar una GPU si hay alguna disponible; si no, usar la CPU."gpu": usar la GPU. Utilizar una GPU requiere una licencia de Parallel Computing Toolbox y un dispositivo GPU compatible. Para obtener información sobre los dispositivos compatibles, consulte GPU Computing Requirements (Parallel Computing Toolbox). Si no está disponible Parallel Computing Toolbox o una GPU adecuada, el software devuelve un error."cpu": usar la CPU."multi-gpu": usar varias GPU en una máquina, usando un grupo paralelo local basado en su perfil de cluster predeterminado. Si no hay grupo paralelo actual, el software inicia un grupo paralelo con un tamaño de grupo idéntico al número de GPU disponibles."parallel": usar un grupo paralelo local o remoto basado en su perfil de cluster predeterminado. Si no hay grupo paralelo actual, el software inicia uno mediante el perfil de cluster predeterminado. Si el grupo tiene acceso a varias GPU, solo workers con una GPU única realizan el cálculo. Si el grupo no tiene varias GPU, en su lugar el cálculo se realiza en todos los workers de las CPU disponibles.
Para obtener más información sobre cuándo utilizar los diferentes entornos de ejecución, consulte Scale Up Deep Learning in Parallel, on GPUs, and in the Cloud.
Las opciones "gpu", "multi-gpu" y "parallel" requieren Parallel Computing Toolbox. Para utilizar una GPU para deep learning, debe también disponer de un dispositivo GPU compatible. Para obtener información sobre los dispositivos compatibles, consulte GPU Computing Requirements (Parallel Computing Toolbox). Si elige una de estas opciones y Parallel Computing Toolbox o una GPU adecuada no está disponible, el software devuelve un error.
Para hacer predicciones en paralelo con redes con capas recurrentes (estableciendo ExecutionEnvironment en "multi-gpu" o "parallel"), la opción SequenceLength debe ser "shortest" o "longest".
Las redes con capas personalizadas que contienen parámetros State no son compatibles con hacer predicciones en paralelo.
Opción para devolver etiquetas categóricas, especificada como 0 (false) o 1 (true).
Si ReturnCategorical es 1 (true), la función devuelve etiquetas categóricas para capas de salida de clasificación. En caso contrario, la función devuelve las puntuaciones de predicción de las capas de salida de clasificación.
Opción para rellenar, truncar o dividir secuencias, especificada como uno de estos valores:
"longest": rellenar secuencias en cada minilote para tener la misma longitud que la secuencia más larga. Esta opción no descarta ningún dato, aunque el relleno puede introducir ruido a la red neuronal."shortest": truncar secuencias en cada minilote para tener la misma longitud que la secuencia más corta. Esta opción garantiza que no se añade relleno, a costa de descartar datos.Entero positivo: para cada minilote, rellenar las secuencias hasta la longitud de la secuencia más larga del minilote y, después, dividir las secuencias en secuencias más pequeñas de la longitud especificada. Si se produce la división, el software crea minilotes adicionales. Si la longitud de secuencia especificada no divide uniformemente las longitudes de secuencia de los datos, entonces los minilotes que contienen las unidades de tiempo finales de las secuencias tienen una longitud más corta que la longitud de secuencia especificada. Utilice esta opción si las secuencias completas no caben en la memoria. Como alternativa, intente reducir el número de secuencias por minilote ajustando la opción
MiniBatchSizea un valor inferior.
Para obtener más información sobre el efecto del relleno y el truncado de las secuencias, consulte Relleno y truncado de secuencias.
Tipos de datos: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64 | char | string
Dirección de relleno o truncado, especificada como una de las siguientes opciones:
"right": rellenar o truncar secuencias a la derecha. Las secuencias comienzan en la misma unidad de tiempo y el software trunca o añade relleno al final de las secuencias."left": rellenar o truncar secuencias a la izquierda. El software trunca o añade relleno al principio de las secuencias para que dichas secuencias finalicen en la misma unidad de tiempo.
Dado que las capas recurrentes procesan los datos secuenciales en una unidad de tiempo cada vez, cuando la propiedad OutputMode de la capa recurrente es "last", cualquier relleno en las unidades de tiempo finales puede influir negativamente en la salida de la capa. Para rellenar o truncar datos secuenciales a la izquierda, establezca la opción SequencePaddingDirection en "left".
Para redes neuronales secuencia a secuencia (cuando la propiedad OutputMode es "sequence" para cada capa recurrente), cualquier relleno en las primeras unidades de tiempo puede influir negativamente en las predicciones para unidades de tiempo anteriores. Para rellenar o truncar datos secuenciales a la derecha, establezca la opción SequencePaddingDirection en "right".
Para obtener más información sobre el efecto del relleno y el truncado de las secuencias, consulte Relleno y truncado de secuencias.
Valor con el que rellenar secuencias de entrada, especificado como un escalar.
No rellene secuencias con NaN, porque haciéndolo se pueden propagar errores por la red neuronal.
Tipos de datos: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Argumentos de salida
Respuestas predichas, devueltas como un arreglo numérico, un arreglo categórico o un arreglo de celdas. El formato de Y depende del tipo de problema.
La tabla siguiente describe el formato de los problemas de regresión.
| Tarea | Formato |
|---|---|
| Regresión de imágenes 2D |
|
| Regresión de imágenes 3D |
|
| Regresión de secuencia a uno | Matriz de N por R, en la que N es el número de secuencias y R es el número de respuestas |
| Regresión secuencia a secuencia | Arreglo de celdas de N por 1 de secuencias numéricas, donde N es el número de secuencias. Las secuencias son matrices con R filas, donde R es el número de respuestas. Cada secuencia tiene el mismo número de unidades de tiempo que la secuencia de entrada correspondiente después de que se aplique la opción Para tareas de regresión secuencia a secuencia con una observación, |
| Regresión de características | Matriz de N por R, en la que N es el número de observaciones y R es el número de respuestas |
Para problemas de regresión secuencia a secuencia con una observación, sequences puede ser una matriz. En ese caso, Y es una matriz de respuestas.
Si ReturnCategorical es 0 (falso) y la capa de salida de la red es una capa de clasificación, Y son las puntuaciones de clasificación predichas. Esta tabla describe el formato de las puntuaciones de las tareas de clasificación.
| Tarea | Formato |
|---|---|
| Clasificación de imágenes | Matriz de N por K, en la que N es el número de observaciones y K es el número de clases |
| Clasificación secuencia a etiqueta | |
| Clasificación de características | |
| Clasificación secuencia a secuencia | Arreglo de celdas de N por 1 de matrices, en el que N es el número de observaciones. Las secuencias son matrices con K filas, donde K es el número de clases. Cada secuencia tiene el mismo número de unidades de tiempo que la secuencia de entrada correspondiente después de que se aplique la opción |
Si ReturnCategorical es 1 (verdadero) y la capa de salida de la red es una capa de clasificación, Y es un vector categórico o un arreglo de celdas de vectores categóricos. Esta tabla describe el formato de las etiquetas de las tareas de clasificación.
| Tarea | Formato |
|---|---|
| Clasificación de características o imágenes | Vector categórico de N por 1 de etiquetas, en el que N es el número de observaciones |
| Clasificación secuencia a etiqueta | |
| Clasificación secuencia a secuencia | Arreglo de celdas de N por 1 de secuencias categóricas de etiquetas, en el que N es el número de observaciones. Cada secuencia tiene el mismo número de unidades de tiempo que la secuencia de entrada correspondiente después de que se aplique la opción En cuanto a las tareas de clasificación secuencia a secuencia con una observación, |
Puntuaciones o respuestas predichas de redes con varias salidas, devueltas como arreglos numéricos, arreglos categóricos o arreglos de celdas.
Cada salida Yj corresponde a la salida de red net.OutputNames(j) y su formato es el que se describe en el argumento de salida Y.
Algoritmos
Cuando entrena una red neuronal mediante las funciones trainnet o trainNetwork o cuando usa las funciones de predicción o validación con objetos DAGNetwork y SeriesNetwork, el software realiza estos cálculos utilizando aritmética de precisión simple y de punto flotante. Las funciones para predicción y validación incluyen predict, classify y activations. El software utiliza aritmética de precisión simple cuando entrena redes neuronales usando tanto CPU como GPU.
Para proporcionar el mejor rendimiento, no se garantiza que deep learning utilizando una GPU en MATLAB sea determinista. Según la arquitectura de su red, con ciertas condiciones puede obtener resultados diferentes al usar una GPU para entrenar dos redes idénticas o hacer dos predicciones utilizando la misma red y los mismos datos.
Alternativas
En redes con solo una capa de clasificación, puede calcular las clases y las puntuaciones predichas a partir de una red entrenada con la función classify.
Para calcular las activaciones de una capa de red, use la función activations.
Para redes recurrentes, como las redes de LSTM, puede hacer predicciones y actualizar el estado de la red usando classifyAndUpdateState y predictAndUpdateState.
Referencias
[1] Kudo, Mineichi, Jun Toyama, and Masaru Shimbo. “Multidimensional Curve Classification Using Passing-through Regions.” Pattern Recognition Letters 20, no. 11–13 (November 1999): 1103–11. https://doi.org/10.1016/S0167-8655(99)00077-X.
[2] UCI Machine Learning Repository: Japanese Vowels Dataset. https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels.
Capacidades ampliadas
Notas y limitaciones de uso:
La generación de código C++ es compatible con las siguientes sintaxis:
Y = predict(net,images), dondeimageses un arreglo numéricoY = predict(net,sequences), dondesequenceses un arreglo de celdasY = predict(net,features), dondefeatureses un arreglo numérico[Y1,...,YM] = predict(__)utilizando cualquiera de las sintaxis anteriores__ = predict(__,Name=Value)utilizando cualquiera de las sintaxis anteriores
Para entradas numéricas, la entrada no debe tener un tamaño variable. El tamaño debe estar fijado en el momento de la generación de código.
Para entradas secuenciales de vector, el número de características debe ser una constante durante la generación de código. La longitud de la secuencia puede tener un tamaño variable.
Para entradas secuenciales de imágenes, la altura, la anchura y el número de canales deben ser una constante durante la generación de código.
Solo los argumentos de par nombre-valor
MiniBatchSize,ReturnCategorical,SequenceLength,SequencePaddingDirectionySequencePaddingValueson compatibles con la generación de código. Todos los pares nombre-valor deben ser constantes en tiempo de compilación.Solo las opciones
"longest"y"shortest"del par nombre-valorSequenceLengthson compatibles con la generación de código.Si
ReturnCategoricales1(verdadero) y usa un compilador GCC C o C++ con la versión 8.2 o superior, podría recibir un aviso-Wstringop-overflow.La generación de código para el objetivo de Intel® MKL-DNN no es compatible con la combinación de argumentos nombre-valor
SequenceLength="longest",SequencePaddingDirection="left"ySequencePaddingValue=0.
Para obtener información sobre generar código para redes neuronales de deep learning, consulte Workflow for Deep Learning Code Generation with MATLAB Coder (MATLAB Coder).
Notas y limitaciones de uso:
La generación de código GPU es compatible con las siguientes sintaxis:
Y = predict(net,images), dondeimageses un arreglo numéricoY = predict(net,sequences), dondesequenceses un arreglo de celdas o un arreglo numéricoY = predict(net,features), dondefeatureses un arreglo numérico[Y1,...,YM] = predict(__)utilizando cualquiera de las sintaxis anteriores__ = predict(__,Name=Value)utilizando cualquiera de las sintaxis anteriores
Para entradas numéricas, la entrada no debe tener tamaño variable. El tamaño debe estar fijado en el momento de la generación de código.
La generación de código GPU no es compatible con entradas
gpuArraya la funciónpredict.La biblioteca cuDNN es compatible con secuencias de vectores y de imágenes 2D. La biblioteca TensorRT es solo compatible con secuencias de entrada de vectores. La ARM®
Compute Librarypara GPU no es compatible con redes recurrentes.Para entradas secuenciales de vector, el número de características debe ser una constante durante la generación de código. La longitud de la secuencia puede tener un tamaño variable.
Para entradas secuenciales de imágenes, la altura, la anchura y el número de canales deben ser una constante durante la generación de código.
Solo los argumentos de par nombre-valor
MiniBatchSize,ReturnCategorical,SequenceLength,SequencePaddingDirectionySequencePaddingValueson compatibles con la generación de código. Todos los pares nombre-valor deben ser constantes en tiempo de compilación.Solo las opciones
"longest"y"shortest"del par nombre-valorSequenceLengthson compatibles con la generación de código.La generación de código GPU para la función
predictes compatible con entradas definidas como tipo de datos de precisión media y como flotante. Para obtener más información, consultehalf(GPU Coder).Si
ReturnCategoricalestá establecido en1(verdadero) y usa un compilador GCC C o C++ con la versión 8.2 o superior, podría recibir un aviso-Wstringop-overflow.
Para ejecutar los cálculos en paralelo, establezca la opción ExecutionEnvironment en "multi-gpu" o "parallel".
Para obtener más detalles, consulte Scale Up Deep Learning in Parallel, on GPUs, and in the Cloud.
La opción
ExecutionEnvironmentdebe ser"auto"o"gpu"cuando los datos de entrada son:Un
gpuArrayUn arreglo de celdas que contiene objetos
gpuArrayUna tabla que contiene objetos
gpuArrayUn almacén de datos que produce como salida arreglos de celdas que contienen objetos
gpuArrayUn almacén de datos que produce como salida tablas que contienen objetos
gpuArray
Para obtener más información, consulte Run MATLAB Functions on a GPU (Parallel Computing Toolbox).
Historial de versiones
Introducido en R2016aA partir de la versión R2024a, los objetos DAGNetwork y SeriesNetwork no están recomendados. En su lugar, utilice los objetos dlnetwork. Esta recomendación significa que la función predict tampoco está recomendada. Utilice la función minibatchpredict o predict (dlnetwork) en su lugar.
No está previsto eliminar el soporte para los objetos DAGNetwork y SeriesNetwork. Sin embargo, en su lugar se recomiendan los objetos dlnetwork, que tienen estas ventajas:
Los objetos
dlnetworkson un tipo de datos unificado que admite la creación de redes, la predicción, el entrenamiento integrado, la visualización, la compresión, la verificación y los bucles de entrenamiento personalizados.Los objetos
dlnetworkadmiten una gama más amplia de arquitecturas de red que puede crear o importar desde plataformas externas.La función
trainnetadmite objetosdlnetwork, lo que le permite especificar fácilmente funciones de pérdida. Puede seleccionar entre funciones de pérdida integradas o especificar una función de pérdida personalizada.Entrenar y predecir con los objetos
dlnetworksuele ser más rápido que los flujos de trabajoLayerGraphytrainNetwork.
Para convertir un objeto DAGNetwork o SeriesNetwork entrenado en un objeto dlnetwork, use la función dag2dlnetwork.
Esta tabla muestra un uso habitual de la función predict y cómo actualizar el código para usar los objetos dlnetwork en su lugar.
| No recomendado | Recomendado |
|---|---|
Y = predict(net,X); | Y = minibatchpredict(net,X); |
A partir de R2022b, cuando se hacen predicciones con datos secuenciales utilizando las funciones predict, classify, predictAndUpdateState, classifyAndUpdateState y activations y la opción SequenceLength es un número entero, el software rellena las secuencias hasta la longitud de la secuencia más larga en cada minilote y, luego, divide las secuencias en minilotes con la longitud de secuencia especificada. Si SequenceLength no divide uniformemente la longitud de la secuencia del minilote, entonces el último minilote dividido tiene una longitud más corta que SequenceLength. Este comportamiento evita que las unidades de tiempo que contienen solo valores de relleno influyan en las predicciones.
En versiones anteriores, el software rellena los minilotes de secuencias para que tengan una longitud que coincida con el múltiplo más cercano de SequenceLength que sea mayor o igual a la longitud del minilote y, luego, divide los datos. Para reproducir este comportamiento, rellene de forma manual los datos de entrada de modo que los minilotes tengan una longitud múltiple de SequenceLength apropiada. Para flujos de trabajo de secuencia a secuencia, es posible que también deba eliminar de forma manual unidades de tiempo de la salida que correspondan a valores de relleno.
Consulte también
dlnetwork | predict | forward | minibatchpredict | scores2label | classifyAndUpdateState
Temas
- Entrenar una red neuronal convolucional para regresión
- Regresión de secuencia a secuencia mediante deep learning
- Regresión de secuencia a uno mediante deep learning
- Pronóstico de series de tiempo mediante deep learning
- Convertir una red de clasificación en una red de regresión
- Deep learning en MATLAB
- Trucos y consejos de deep learning
MATLAB Command
You clicked a link that corresponds to this MATLAB command:
Run the command by entering it in the MATLAB Command Window. Web browsers do not support MATLAB commands.
Seleccione un país/idioma
Seleccione un país/idioma para obtener contenido traducido, si está disponible, y ver eventos y ofertas de productos y servicios locales. Según su ubicación geográfica, recomendamos que seleccione: .
También puede seleccionar uno de estos países/idiomas:
Cómo obtener el mejor rendimiento
Seleccione China (en idioma chino o inglés) para obtener el mejor rendimiento. Los sitios web de otros países no están optimizados para ser accedidos desde su ubicación geográfica.
América
- América Latina (Español)
- Canada (English)
- United States (English)
Europa
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)