ksdensity
Estimación de la función de suavizado de kernel para datos univariantes y bivariantes
Sintaxis
Descripción
[ devuelve una estimación de la densidad de probabilidad, f,xi] = ksdensity(x)f, para los datos de muestra en el vector o la matriz de dos columnas x. La estimación se basa en una función de kernel normal y se evalúa en puntos equidistantes, xi, que cubren el rango de los datos de x. ksdensity estima la densidad en 100 puntos para datos univariantes o en 900 puntos para datos bivariantes.
ksdensity es adecuada para muestras distribuidas de forma continua.
[ usa opciones adicionales especificadas por uno o varios argumentos de par nombre-valor además de los argumentos de entrada de las sintaxis anteriores. Por ejemplo, puede definir el tipo de función que f,xi] = ksdensity(___,Name,Value)ksdensity evalúa, como la densidad de probabilidad, la probabilidad acumulada, la función de supervivencia, etc. O bien puede especificar el ancho de banda de la ventana de suavizado.
Ejemplos
Genere un conjunto de datos de muestra a partir de una combinación de dos distribuciones normales.
rng('default') % For reproducibility x = [randn(30,1); 5+randn(30,1)];
Represente la densidad estimada.
[f,xi] = ksdensity(x); figure plot(xi,f);

La estimación de la densidad muestra la bimodalidad de la muestra.
Genere un conjunto de datos de muestra no negativos a partir de la distribución seminormal.
rng('default') % For reproducibility pd = makedist('HalfNormal','mu',0,'sigma',1); x = random(pd,100,1);
Estime las pdf con dos métodos diferentes de corrección de límites, reflejo y transformación logarítmica, utilizando el argumento de par nombre-valor 'BoundaryCorrection'.
pts = linspace(0,5,1000); % points to evaluate the estimator [f1,xi1] = ksdensity(x,pts,'Support','positive'); [f2,xi2] = ksdensity(x,pts,'Support','positive','BoundaryCorrection','reflection');
Represente las dos pdf estimadas.
plot(xi1,f1,xi2,f2) lgd = legend('log','reflection'); title(lgd, 'Boundary Correction Method') xl = xlim; xlim([xl(1)-0.25 xl(2)])

ksdensity usa un método de corrección de límites cuando se especifica el soporte positivo o acotado. El método de corrección de límites predeterminado es la transformación logarítmica. Cuando ksdensity transforma de nuevo el soporte, introduce el término 1/x en el estimador de densidad de kernel. Por consiguiente, la estimación presenta un pico cerca de x = 0. Por otro lado, el método de reflejo no causa picos no deseados cerca del límite.
Cargue los datos de muestra.
load hospitalCalcule y represente la cdf estimada evaluada en un conjunto de valores especificado.
pts = (min(hospital.Weight):2:max(hospital.Weight)); figure() ecdf(hospital.Weight) hold on [f,xi,bw] = ksdensity(hospital.Weight,pts,'Support','positive',... 'Function','cdf'); plot(xi,f,'-g','LineWidth',2) legend('empirical cdf','kernel-bw:default','Location','northwest') xlabel('Patient weights') ylabel('Estimated cdf')
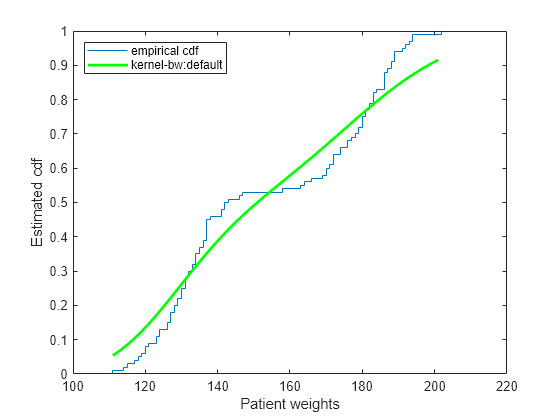
ksdensity parece que suaviza demasiado la estimación de la función de distribución acumulada. Una estimación con un ancho de banda más pequeño podría generar una estimación más cercana a la función de distribución acumulada empírica.
Devuelva el ancho de banda de la ventana de suavizado.
bw
bw = 0.1070
Represente la estimación de la función de distribución acumulada con un ancho de banda más pequeño.
[f,xi] = ksdensity(hospital.Weight,pts,'Support','positive',... 'Function','cdf','Bandwidth',0.05); plot(xi,f,'--r','LineWidth',2) legend('empirical cdf','kernel-bw:default','kernel-bw:0.05',... 'Location','northwest') hold off

La estimación ksdensity con un ancho de banda más pequeño combina mejor con la función de distribución acumulada empírica.
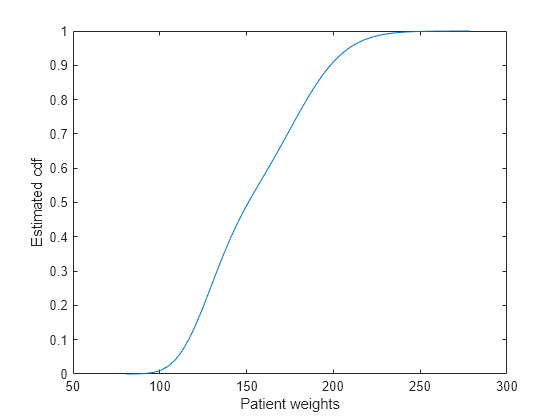
Cargue los datos de muestra.
load hospitalRepresente la cdf estimada evaluada en 50 puntos equidistantes.
figure() ksdensity(hospital.Weight,'Support','positive','Function','cdf',... 'NumPoints',50) xlabel('Patient weights') ylabel('Estimated cdf')
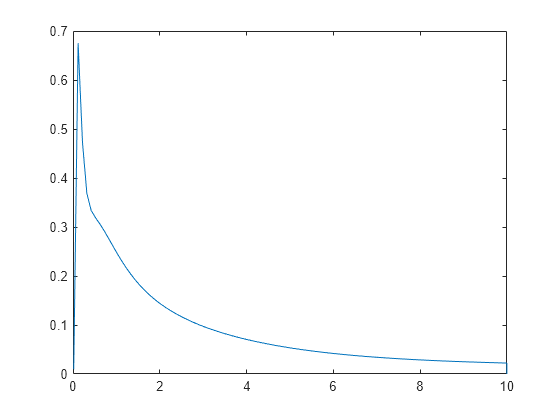
Genere datos de muestra a partir de una distribución exponencial con una media de 3.
rng('default') % For reproducibility x = random('exp',3,100,1);
Cree un vector lógico que indique censura. Aquí, se censuran las observaciones con una duración superior a 10.
T = 10; cens = (x>T);
Calcule y represente la función de densidad estimada.
figure ksdensity(x,'Support','positive','Censoring',cens);
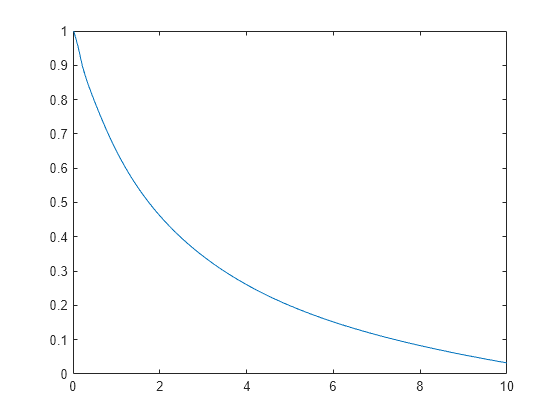
Calcule y represente la función de supervivencia.
figure ksdensity(x,'Support','positive','Censoring',cens,... 'Function','survivor');
Calcule y represente la función de riesgo acumulativo.
figure ksdensity(x,'Support','positive','Censoring',cens,... 'Function','cumhazard');

Genere una combinación de dos distribuciones normales y represente la función de distribución acumulativa inversa estimada en un conjunto especificado de valores de probabilidad.
rng('default') % For reproducibility x = [randn(30,1); 5+randn(30,1)]; pi = linspace(.01,.99,99); figure ksdensity(x,pi,'Function','icdf');
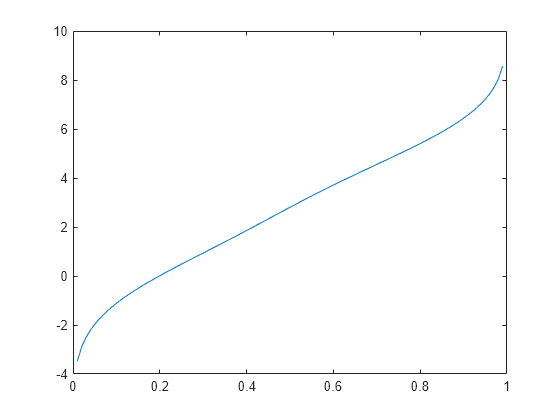
Genere una combinación de dos distribuciones normales.
rng('default') % For reproducibility x = [randn(30,1); 5+randn(30,1)];
Devuelva el ancho de banda de la ventana de suavizado para la estimación de la densidad de probabilidad.
[f,xi,bw] = ksdensity(x); bw
bw = 1.5141
El ancho de banda predeterminado es óptimo para densidades normales.
Represente la densidad estimada.
figure plot(xi,f); xlabel('xi') ylabel('f') hold on

Represente la densidad con un valor de ancho de banda aumentado.
[f,xi] = ksdensity(x,'Bandwidth',1.8); plot(xi,f,'--r','LineWidth',1.5)
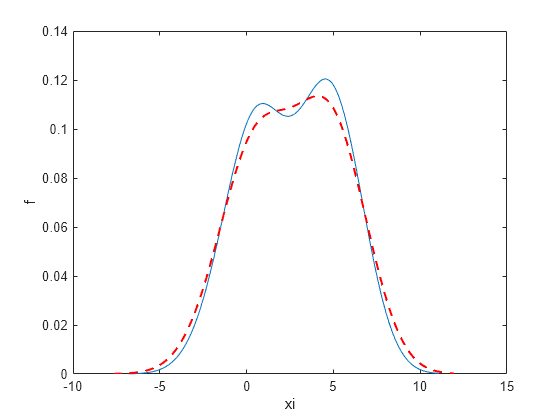
Un ancho de banda más alto suaviza aún más la estimación de la densidad, lo que podría ocultar algunas características de la distribución.
Ahora, represente la densidad con un valor de ancho de banda reducido.
[f,xi] = ksdensity(x,'Bandwidth',0.8); plot(xi,f,'-.k','LineWidth',1.5) legend('bw = default','bw = 1.8','bw = 0.8') hold off
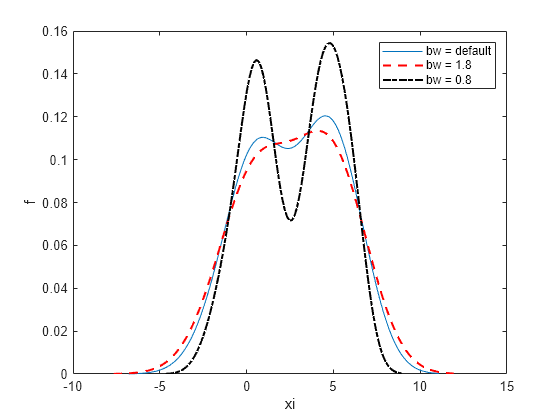
Un ancho de banda más bajo suaviza menos la estimación de la densidad, lo que exagera algunas características de la muestra.
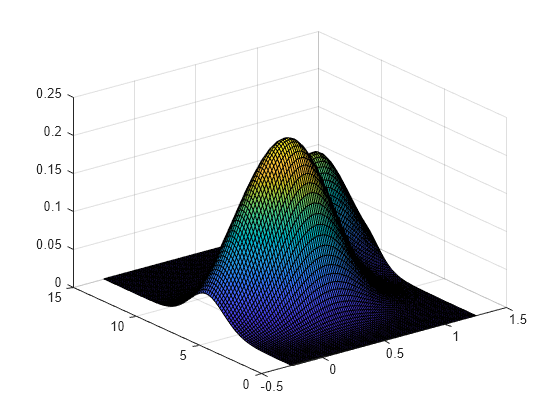
Cree un vector de puntos de dos columnas en los que se evalúe la densidad.
gridx1 = -0.25:.05:1.25; gridx2 = 0:.1:15; [x1,x2] = meshgrid(gridx1, gridx2); x1 = x1(:); x2 = x2(:); xi = [x1 x2];
Genere una matriz de 30 por 2 que contenga números aleatorios de una combinación de distribuciones normales bivariantes.
rng('default') % For reproducibility x = [0+.5*rand(20,1) 5+2.5*rand(20,1); .75+.25*rand(10,1) 8.75+1.25*rand(10,1)];
Represente la densidad estimada de los datos de muestra.
figure ksdensity(x,xi);
Argumentos de entrada
Argumentos de par nombre-valor
Argumentos de salida
Más acerca de
Funcionalidad alternativa
También puede estimar la pdf o cdf para datos univariantes mediante la función kde de MATLAB®. A diferencia de ksdensity, kde no admite métodos de corrección de límites ni censura de datos.
Referencias
[1] Botev, Z. I., J. F. Grotowski, and D. P. Kroese. "Kernel Density Estimation via Diffusion." The Annals of Statistics, vol. 38, no. 5 (October 1, 2010). https://projecteuclid.org/journals/annals-of-statistics/volume-38/issue-5/Kernel-density-estimation-via-diffusion/10.1214/10-AOS799.full
[2] Bowman, A. W., and A. Azzalini. Applied Smoothing Techniques for Data Analysis. New York: Oxford University Press Inc., 1997.
[3] Hill, P. D. “Kernel estimation of a distribution function.” Communications in Statistics - Theory and Methods. Vol 14, Issue. 3, 1985, pp. 605-620.
[4] Jones, M. C. “Simple boundary correction for kernel density estimation.” Statistics and Computing. Vol. 3, Issue 3, 1993, pp. 135-146.
[5] Silverman, B. W. Density Estimation for Statistics and Data Analysis. Chapman & Hall/CRC, 1986.
Capacidades ampliadas
Historial de versiones
Introducido antes de R2006a