Distribution Fitter
Ajustar distribuciones de probabilidad a datos
Descripción
La app Distribution Fitter ajusta de manera interactiva distribuciones de probabilidad a datos importados del área de trabajo de MATLAB®. Puede elegir entre 22 distribuciones de probabilidad integradas o crear la suya propia. La app muestra gráficas de la distribución ajustada superpuesta sobre un histograma de los datos. Entre las gráficas disponibles, se encuentran la función de densidad de probabilidad (pdf), la función de distribución acumulativa (cdf), gráficas de probabilidad y funciones de supervivencia. Puede exportar los valores de parámetro ajustados al área de trabajo como objeto de distribución de probabilidad y utilizar las funciones del objeto para realizar más análisis. Para obtener más información sobre cómo trabajar con estos objetos, consulte Working with Probability Distributions. Para ver el flujo de trabajo programático de la app Distribution Fitter, consulte Uso programático.
Productos necesarios
MATLAB
Statistics and Machine Learning Toolbox™

Abrir la aplicación Distribution Fitter
Barra de herramientas de MATLAB: En la pestaña Apps, en Math, Statistics and Optimization, haga clic en el icono de la app.
Línea de comandos de MATLAB: Introduzca
distributionFitter.
Ejemplos
Cargue los datos de muestra carsmall.
load carsmallAbra la app Distribution Fitter utilizando los datos de millas por galón MPG.
distributionFitter(MPG)
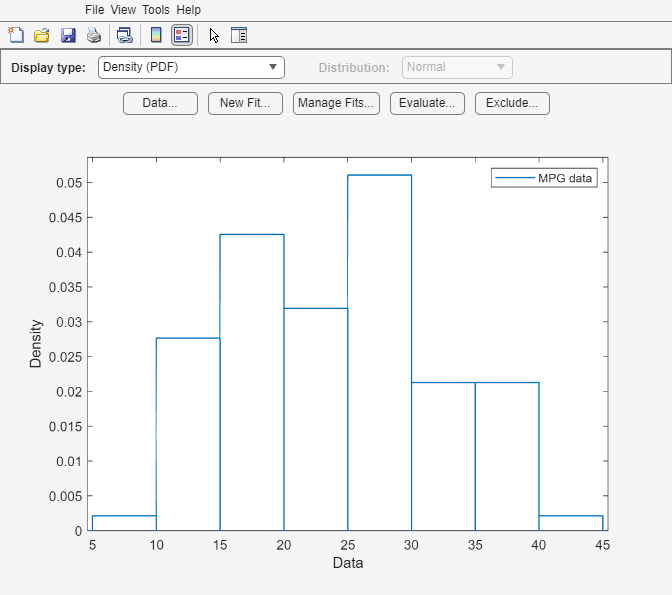
Se abre la app Distribution Fitter, rellena con los datos de MPG y muestra la gráfica de densidad (PDF). Puede utilizar la app para visualizar diferentes gráficas y ajustar distribuciones a estos datos.
Cargue los datos de muestra.
load lightbulb.matLa primera columna de los datos contiene la duración (en horas) de dos tipos de bombillas. La segunda columna contiene información sobre el tipo de bombilla. 1 indica bombillas fluorescentes y 0 indica bombillas incandescentes. La tercera columna contiene información que censurar. 1 indica datos censurados y 0 indica el tiempo exacto de fallo. Estos son datos simulados.
Abra la app Distribution Fitter utilizando la primera columna de lightbulb como datos de entrada y la tercera columna como datos de censura. Asigne el nombre lifetime a los datos.
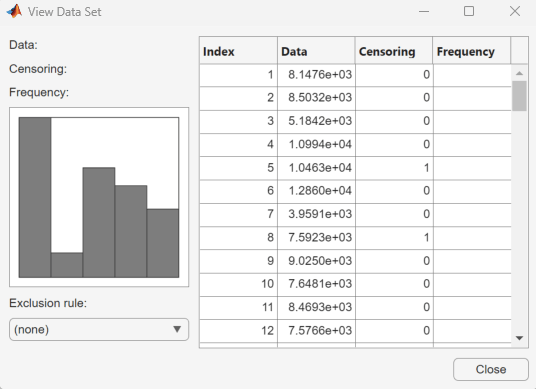
distributionFitter(lightbulb(:,1),lightbulb(:,3),[],"lifetime")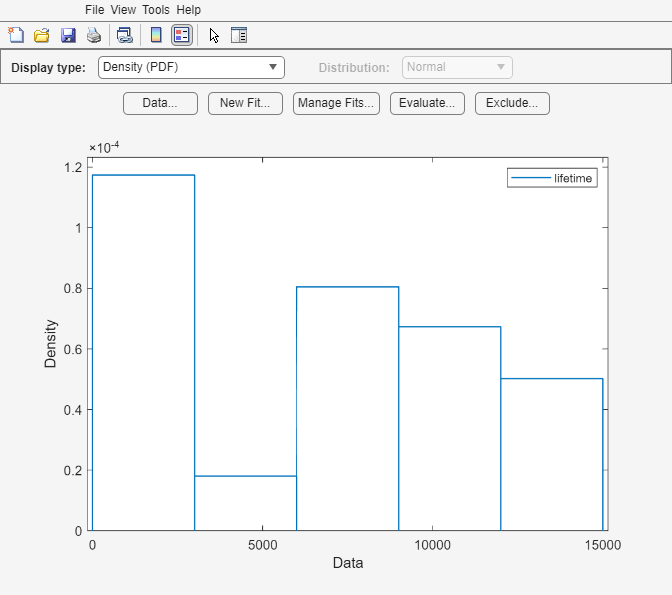
Para abrir el cuadro de diálogo Datos, haga clic en Data. En el panel Manage data sets, haga clic para resaltar la fila del conjunto de datos lifetime. Por último, para abrir el cuadro de diálogo Ver conjunto de datos, haga clic en View. Los datos de vida útil aparecen en la segunda columna y el indicador de censura correspondiente aparece en la tercera.