fitdist
Ajustar un objeto de distribución de probabilidad a datos
Sintaxis
Descripción
pd = fitdist(x,distname,Name,Value)
[ crea objetos de distribución de probabilidad ajustando la distribución especificada por pdca,gn,gl] = fitdist(x,distname,'By',groupvar)distname a los datos de x basándose en la variable de agrupación groupvar. Devuelve un arreglo de celdas de objetos de distribución de probabilidad ajustados, pdca, un arreglo de celdas de etiquetas de grupo, gn, y un arreglo de celdas de niveles de variables de agrupación, gl.
[ devuelve los argumentos de salida anteriores utilizando más opciones especificadas por uno o más argumentos de par nombre-valor. Por ejemplo, puede indicar datos censurados o especificar parámetros de control para el algoritmo iterativo de ajuste.pdca,gn,gl] = fitdist(x,distname,'By',groupvar,Name,Value)
Ejemplos
Ajuste una distribución normal a datos de muestra y examine el ajuste utilizando un histograma y una gráfica cuantil-cuantil.
Cargue los pesos de los pacientes desde el archivo de datos patients.mat.
load patients
x = Weight;Cree un objeto de distribución normal ajustándolo a los datos.
pd = fitdist(x,'Normal')pd =
NormalDistribution
Normal distribution
mu = 154 [148.728, 159.272]
sigma = 26.5714 [23.3299, 30.8674]
La visualización del objeto de distribución incluye las estimaciones de los parámetros para la media (mu) y la desviación estándar (sigma), y los intervalos de confianza del 95% para los parámetros.
Puede utilizar las funciones del objeto pd para evaluar la distribución y generar números aleatorios. Muestre las funciones del objeto compatibles.
methods(pd)
Methods for class prob.NormalDistribution: cdf gather icdf iqr mean median negloglik paramci pdf plot proflik random std truncate var
Por ejemplo, obtenga los intervalos de confianza del 95% utilizando la función paramci.
ci95 = paramci(pd)
ci95 = 2×2
148.7277 23.3299
159.2723 30.8674
Especifique el nivel de significación (Alpha) para obtener intervalos de confianza con un nivel de confianza diferente. Calcule los intervalos de confianza del 99%.
ci99 = paramci(pd,'Alpha',.01)ci99 = 2×2
147.0213 22.4257
160.9787 32.4182
Evalúe y represente los valores de la pdf de la distribución.
x_values = 50:1:250; y = pdf(pd,x_values); plot(x_values,y)

Cree un histograma con el ajuste de distribución normal utilizando la función histfit. histfit utiliza fitdist para ajustar una distribución a los datos.
histfit(x)
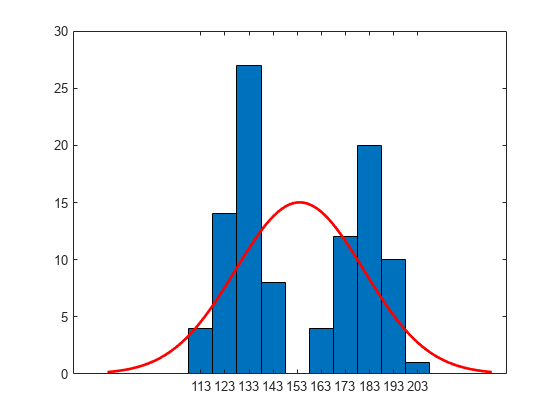
El histograma muestra que los datos tienen dos modos y que el modo del ajuste de distribución normal se encuentra entre esos dos modos.
Utilice qqplot para crear una gráfica cuantil-cuantil de los cuantiles de los datos de muestra de x frente a los valores cuantílicos teóricos de la distribución ajustada.
qqplot(x,pd)

La gráfica no es una línea recta, lo que sugiere que los datos no siguen una distribución normal.
Cargue los pesos de los pacientes desde el archivo de datos patients.mat.
load patients
x = Weight;Cree un objeto de distribución de kernel ajustándolo a los datos. Utilice la función de kernel de Epanechnikov.
pd = fitdist(x,'Kernel','Kernel','epanechnikov')
pd =
KernelDistribution
Kernel = epanechnikov
Bandwidth = 14.3792
Support = unbounded
Represente la pdf de la distribución.
x_values = 50:1:250; y = pdf(pd,x_values); plot(x_values,y)

Cargue los pesos y los géneros de los pacientes desde el archivo de datos patients.mat.
load patients
x = Weight;Cree objetos de distribución normal ajustándolos a los datos, agrupados por género del paciente.
[pdca,gn,gl] = fitdist(x,'Normal','By',Gender)
pdca=1×2 cell array
{1×1 prob.NormalDistribution} {1×1 prob.NormalDistribution}
gn = 2×1 cell
{'Male' }
{'Female'}
gl = 2×1 cell
{'Male' }
{'Female'}
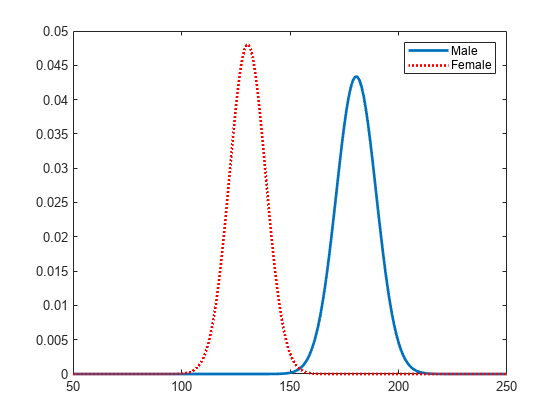
El arreglo de celdas pdca contiene dos objetos de distribución de probabilidad, uno para cada grupo de género. El arreglo de celdas gn contiene dos etiquetas de grupo. El arreglo de celdas gl contiene dos niveles de grupo.
Visualice cada distribución en el arreglo de celdas pdca para comparar la media, mu, y la desviación estándar, sigma, agrupadas por género del paciente.
female = pdca{1} % Distribution for femalesfemale =
NormalDistribution
Normal distribution
mu = 180.532 [177.833, 183.231]
sigma = 9.19322 [7.63933, 11.5466]
male = pdca{2} % Distribution for malesmale =
NormalDistribution
Normal distribution
mu = 130.472 [128.183, 132.76]
sigma = 8.30339 [6.96947, 10.2736]
Calcule la pdf de cada distribución.
x_values = 50:1:250; femalepdf = pdf(female,x_values); malepdf = pdf(male,x_values);
Represente las pdf para una comparación visual de la distribución del peso por género.
figure plot(x_values,femalepdf,'LineWidth',2) hold on plot(x_values,malepdf,'Color','r','LineStyle',':','LineWidth',2) legend(gn,'Location','NorthEast') hold off
Cargue los pesos y los géneros de los pacientes desde el archivo de datos patients.mat.
load patients
x = Weight;Cree objetos de distribución de kernel ajustándolos a los datos, agrupados por género del paciente. Utilice una función de kernel triangular.
[pdca,gn,gl] = fitdist(x,'Kernel','By',Gender,'Kernel','triangle');
Visualice cada distribución en el arreglo de celdas pdca para ver las distribuciones de kernel para cada género.
female = pdca{1} % Distribution for femalesfemale =
KernelDistribution
Kernel = triangle
Bandwidth = 5.08961
Support = unbounded
male = pdca{2} % Distribution for malesmale =
KernelDistribution
Kernel = triangle
Bandwidth = 4.25894
Support = unbounded
Calcule la pdf de cada distribución.
x_values = 50:1:250; femalepdf = pdf(female,x_values); malepdf = pdf(male,x_values);
Represente las pdf para una comparación visual de la distribución del peso por género.
figure plot(x_values,femalepdf,'LineWidth',2) hold on plot(x_values,malepdf,'Color','r','LineStyle',':','LineWidth',2) legend(gn,'Location','NorthEast') hold off

Argumentos de entrada
Argumentos de par nombre-valor
Argumentos de salida
Algoritmos
La función fitdist ajusta la mayoría de distribuciones usando la estimación de máxima verosimilitud. Las distribuciones normal y lognormal con datos no censurados son dos excepciones.
En el caso de la distribución normal no censurada, el valor estimado del parámetro sigma es la raíz cuadrada de la estimación no sesgada de la varianza.
En el caso de la distribución lognormal no censurada, el valor estimado del parámetro sigma es la raíz cuadrada de la estimación no sesgada de la varianza del logaritmo de los datos.
Funcionalidad alternativa
La app Distribution Fitter abre una interfaz gráfica de usuario para importar datos desde el área de trabajo y ajustar de manera interactiva una distribución de probabilidad a esos datos. A continuación, puede guardar la distribución en el área de trabajo como un objeto de distribución de probabilidad. Abra la app Distribution Fitter utilizando
distributionFitteren la línea de comandos o haga clic en Distribution Fitter en la pestaña Apps.Para ajustar una distribución a datos censurados a la izquierda, doblemente censurados o datos censurados a intervalos, use
mle. Puede encontrar las estimaciones de máxima verosimilitud usando la funciónmley crear un objeto de distribución de probabilidad usando la funciónmakedist. Para ver un ejemplo, consulte Find MLEs for Double-Censored Data.
Referencias
[1] Johnson, N. L., S. Kotz, and N. Balakrishnan. Continuous Univariate Distributions. Vol. 1, Hoboken, NJ: Wiley-Interscience, 1993.
[2] Johnson, N. L., S. Kotz, and N. Balakrishnan. Continuous Univariate Distributions. Vol. 2, Hoboken, NJ: Wiley-Interscience, 1994.
[3] Bowman, A. W., and A. Azzalini. Applied Smoothing Techniques for Data Analysis. New York: Oxford University Press, 1997.